
I recently came across an intriguing study about AI recommendation lists that caught my attention. It revealed that AI systems like ChatGPT, Claude, and Google’s AI don’t often repeat the same recommendations when asked for brands or products. This means if I ask them the same question multiple times, I’ll likely get different lists each time.
This finding came from Rand Fishkin of SparkToro and Patrick O’Donnell of Gumshoe.ai. They investigated how consistent generative AI recommendations are, and their results were quite fascinating.
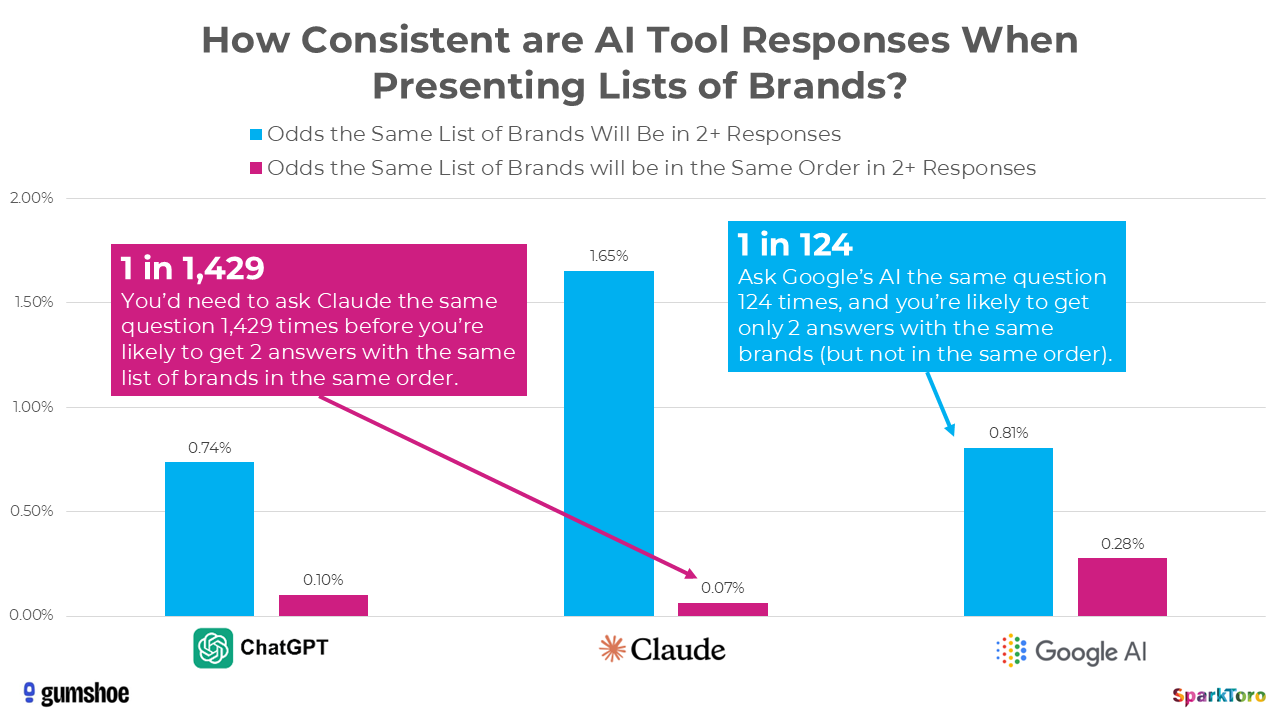
What They Tested. Over 600 volunteers used 12 identical prompts on ChatGPT, Claude, and Google’s AI nearly 3,000 times. What they found was quite revealing.
Each AI response was turned into an ordered list of brands or products, and the overlaps, order, and repetitions were compared to see how often the same answers appeared.
The short answer: almost never. Achieving identical lists twice was incredibly rare, with odds of under 1 in 100, and getting the same list in the same order was even less likely at 1 in 1,000.
Even the length of the lists varied. Some responses listed only two or three options, while others had more than ten. If I’m dissatisfied with the result, simply asking again might yield a better outcome.
Why This Matters. We often hear about personalization in AI answers, but this study is the first to provide real data to support that claim, showing a clear departure from traditional SEO.
Design and Randomness. This variability isn’t a flaw — it’s intentional. These systems are probability engines designed to create diverse outcomes, not stable ordered results like Google’s blue links.
One Consistent Metric. Despite fluctuating rankings, one metric that proved more stable than expected was visibility percentage. Some brands repeatedly appeared in a majority of responses.
Consistent presence in these lists carries more weight than exact ranking, especially across multiple runs and intent changes.
Context Size Counts. The consistency of AI answers improves in smaller, niche markets compared to larger categories, where results scatter significantly.
Real-World Prompts. Testing with actual human prompts showed varied results — as people phrased their queries differently, semantic similarity was low.
Yet, AI still returned similar brands for the same intent, proving that AI captures the underlying purpose behind the queries.
The Power of Intent. Even with hundreds of unique prompts for headphone recommendations, prominent brands like Bose, Sony, and Apple surfaced consistently.
When I change the purpose — say, to gaming or noise-canceling — the brand results shift accordingly, indicating that AI comprehends intent despite varied prompts.
What Doesn’t Help. Tracking exact positions in AI answers is unreliable because these rankings are too unstable to mean anything.
What Could Work. A more effective approach might be to track how frequently my brand appears over many prompts, even if it seems complex and imperfect.
Unanswered Questions. There are still gaps to explore, like determining how many attempts are needed for reliable visibility stats or whether API-based results align with real user behavior.
Conclusion. AI recommendation lists are inherently variable, but with large-scale, careful visibility measurement, I can derive actionable insights. Just don’t mistake this for traditional ranking metrics.
For more details, you can read the full report here.
Inspired by this post on Search Engine Land.

Leave a Reply