I recently discovered that OpenAI is set to introduce conversion-optimized ad campaigns starting in early June. This marks a significant step towards creating a performance advertising ecosystem within ChatGPT.
Why does this matter to us? This move by OpenAI, as reported by The Information, confirms the development of conversion-focused ads along with necessary tracking infrastructure and performance measurement tools for advertisers like us.
What’s the current update? OpenAI has communicated with advertisers, stating that those who set up the OpenAI Pixel or Conversions API in advance will get early access to these campaigns in June.
According to the company:
Advertisers configuring conversions by June 1 will gain early access by June 5.
Advertisers can already start tracking conversions using Ads Manager today.
This system enables advertisers to measure actions triggered by ads, enhancing campaign effectiveness.
A deeper look. OpenAI is setting up an infrastructure akin to performance platforms like Google and Meta. With the OpenAI Pixel, advertisers can track website activity post-ad interaction, while the Conversions API allows them to send first-party conversion data back into OpenAI’s systems directly.
This capability allows OpenAI to optimize campaigns for measurable business outcomes, beyond just engagement metrics.
What’s at stake? The future of OpenAI’s advertising strategy largely hinges on measurement accuracy and gaining advertisers’ trust.
With browser restrictions and privacy changes eroding traditional tracking methods, OpenAI’s Conversions API could play a crucial role in demonstrating campaign performance and attribution within AI-driven ad experiences.
The latest updates to ChatGPT Ads are empowering me as an advertiser with greater control over how I manage my campaigns, especially when it comes to pacing, location targeting, and engaging with ads more effectively.
OpenAI’s recent rollout of updates to the Ads Manager Beta is expanding my capabilities in the realm of campaign pacing, targeting, and reporting. They’re also quietly testing intriguing new ad experiences within ChatGPT.
With these ongoing enhancements, OpenAI is clearly investing in building a robust advertising platform. This makes ChatGPT an increasingly attractive channel for both performance and brand advertising.
What’s new in Ads Manager Beta:
Daily Budgets are Here. Now, I have the option to choose between a daily or a lifetime budget when setting up new campaigns.
Currently, daily budgets apply only to newly launched campaigns. This change provides me with the flexibility to better manage pacing and spending, especially for ongoing campaigns or those requiring tighter control.
Enhanced Geo Targeting. OpenAI is introducing more detailed location targeting options across the U.S.
Now, I’m able to target campaigns by state, designated market area (DMA), and zip code, allowing for more precise audience targeting.
These targeting settings can be applied either during campaign setup or modified later within campaign settings. This update aligns ChatGPT’s ad tools more closely with familiar location controls on platforms like Google and Meta.
Aggregate Totals in Reporting Views. Now, the Ads Manager table views display aggregate totals for essential metrics such as impressions, clicks, and spending.
Having these totals available across campaign, ad group, and ad-level reporting views helps me quickly assess performance without the need for data exports.
Testing New ChatGPT Ad Experiences. In tandem with the Ads Manager updates, OpenAI has begun testing new ad experiences within ChatGPT.
Some ads now feature dynamic calls-to-action (CTAs) such as:
“Shop Now”
“Book Now”
“Sign Up”
“Learn More”
OpenAI indicates that CTAs are automatically chosen based on ad creative and destination experience, with the possibility of advertiser controls for CTA selection in the future.
OpenAI describes this feature as a lightweight enhancement aimed at improving user understanding and engagement with ads seen in ChatGPT.
Why I Care. Essentially, these updates show that OpenAI is committed to developing a sophisticated, performance-driven ad platform within ChatGPT.
With features like daily budgets and detailed geo-targeting, I’m armed with greater spend and target audience control. These tools are indispensable for mature advertising platforms.
The introduction of dynamic CTAs indicates that OpenAI is optimizing ads for higher engagement and conversion, paving the way for performance-centric ad formats in the future. For brands like ours dipping our toes into AI-native advertising, these updates signal that we’re moving beyond initial testing phases to establish ChatGPT as a viable media channel.
Recently, I’ve been exploring the fascinating divergence in AI adoption between professional circles and general consumers. According to Datos and SparkToro’s latest data, this trend is becoming increasingly apparent.
It was intriguing to see how AI usage is starting to plateau among consumers while remaining on the rise in professional environments. Tools like Claude, ChatGPT, and Gemini are seemingly more popular in the B2B landscape.
Why we care. As I delve deeper into AI’s impact, it’s becoming clear that a universal AI strategy won’t work for everyone. It’s essential to identify whether my audience aligns with these broader trends or if their AI engagement habits are entirely different.
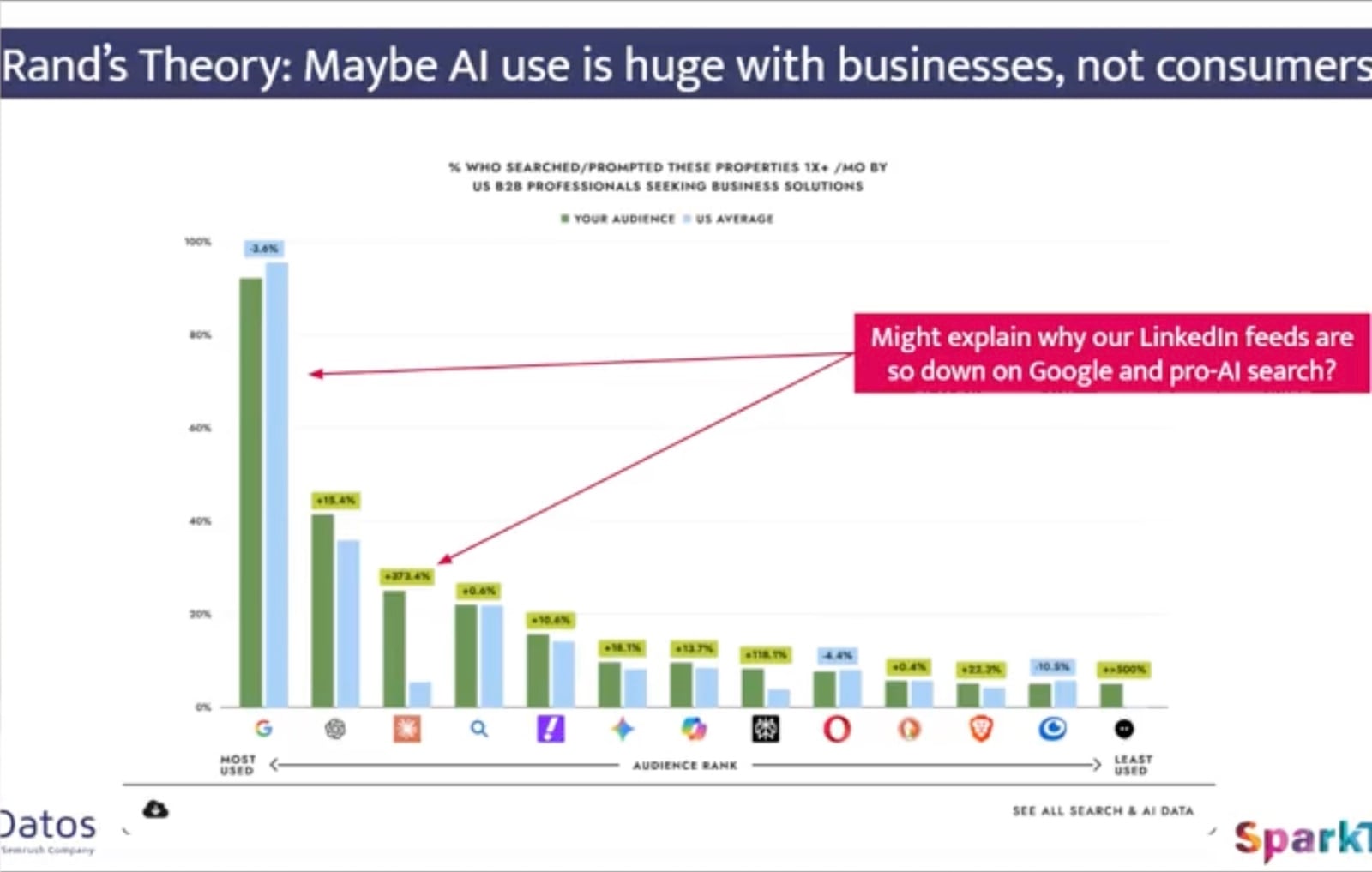
ChatGPT desktop growth slowed. From Fishkin’s analysis, it appears that ChatGPT’s usage in the U.S. has stagnated over recent months while Claude and Gemini continue their growth trajectories. It seems that professionals are continually finding value in these tools.
At its zenith, 37% of U.S. desktop users engaged with OpenAI or ChatGPT back in September 2025. This number dipped slightly to 34% by March, a trend mirrored, albeit with higher numbers, in the EU and U.K.
Claude gained with professionals. I noticed Claude is particularly gaining traction among professional users. Fishkin’s data suggests a significant rise in usage among business professionals, resonating with the notion that AI adoption is stronger in B2B contexts.
The analysis even revealed that Claude’s use among B2B professionals was 373% higher than the U.S. average, reinforcing the tool’s growing popularity in business circles.
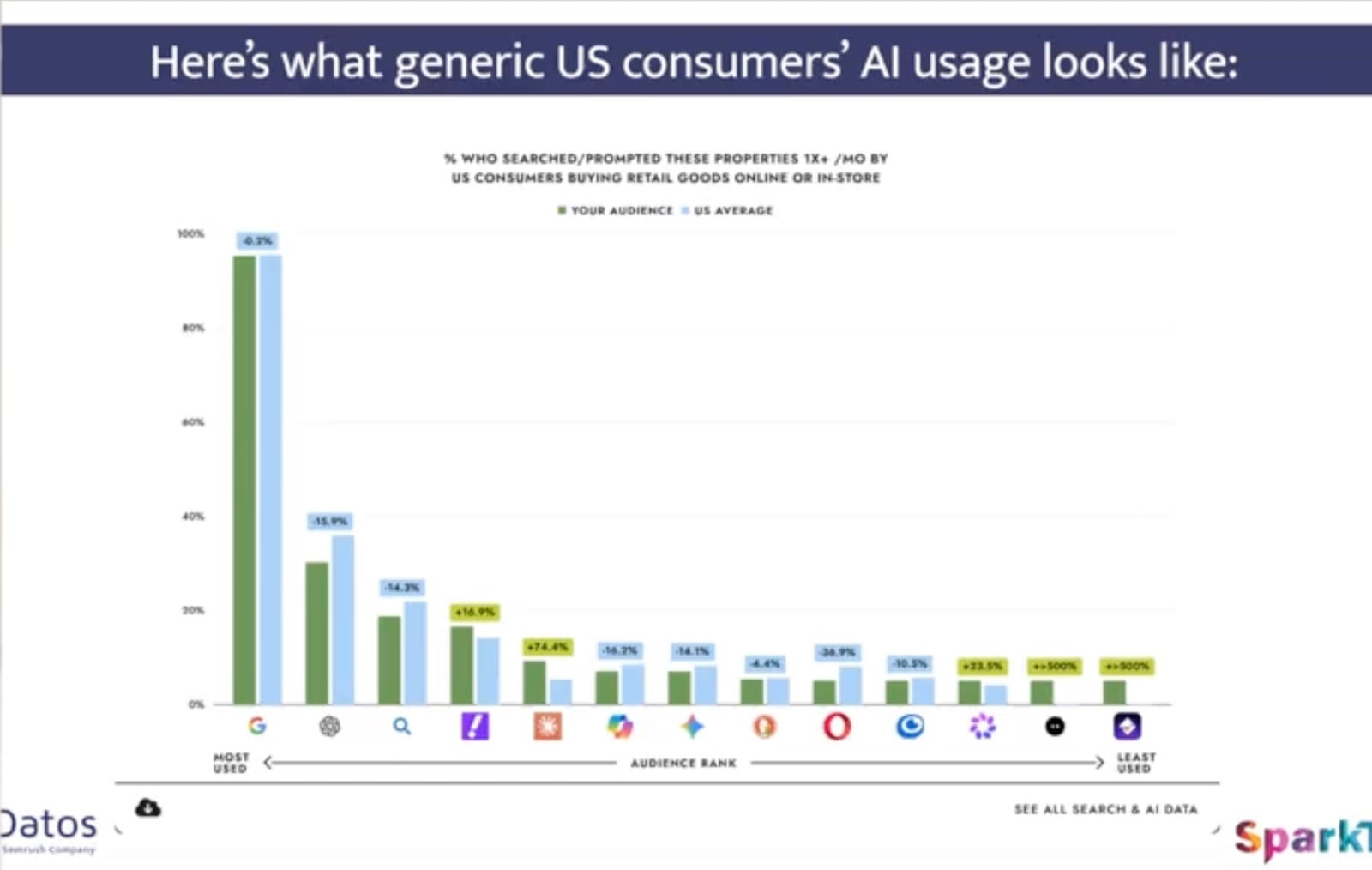
Consumer audiences look different. Interestingly, when it comes to the retail-shopping consumer audience, ChatGPT isn’t as prevalent, being 15% less likely to be used compared to the typical American consumer. For this group, Claude isn’t even in the top four AI tools.
This might explain why AI seems so prevalent in professional networks like LinkedIn, while its visibility is not as pronounced among general consumers.
The research. You can view Rand Fishkin’s detailed insights on LinkedIn by watching his video here.
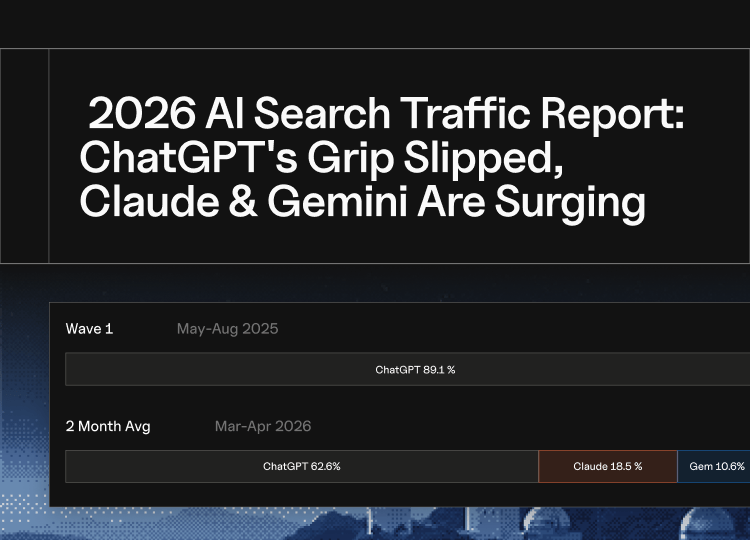
I’ve just delved into Goodie’s enlightening AI search traffic report for early 2026, covering the period from January to April, and I’m excited to share my insights with you. This report dives into trends in usership, referral traffic, and marketing considerations, offering a comprehensive view of the shifting landscape.
You’ll want to pay particular attention to how ChatGPT’s dominance is starting to wane, with some surprising contenders like Claude and Gemini making waves. This shift could significantly impact how marketers strategize their efforts in AI-driven search optimization.
The data reveals fascinating patterns in user habits and referral traffic, which could inform future marketing strategies and the allocation of resources. For a full dive into these emerging trends and what they might mean for businesses, I encourage you to explore the detailed findings of the report.
On May 7, 2026, something remarkable happened that completely shifted the landscape of AI-driven brand traffic. As I watched, ChatGPT quietly launched the most significant single-day transformation I’ve seen all year.
Overnight, the referrals from OpenAI to various brand sites practically doubled. It felt like each mention of a brand by ChatGPT was suddenly more valuable—because they turned into clickable referrals directly to the brands’ homepages.
An analysis of 200 GPT-5.2 responses revealed that enhanced reasoning increases the citation of sources, deepens research, and boosts early-stage funnel visibility.
Subscribe to Growth Memo for weekly expert insights delivered straight to your inbox at no cost.
I’ve explored how AI provides a conversational experience through large language models (LLMs) and chatbots. However, I’ve noticed that no one has thoroughly examined the evolution of citations and mentions within these conversations.
By examining data from the Semrush AI Visibility Toolkit, I reviewed 20 buyer journeys across four industries, comparing the high and low reasoning of ChatGPT5.2.
In this analysis, you’ll discover:
How high reasoning cites a vastly different web with only 25.6% domain overlap and which source types gain or lose prominence.
The renewed importance of TOFU content: Brands cited at the Problem stage tend to persist through to the Selection stage under high reasoning.
How to differentiate your prompt tracking by reasoning modes, ensuring your AI visibility reports reflect two distinct systems instead of an average.
Methodology
Data collection utilized the Semrush AI Visibility Toolkit to capture prompts, citations, and fan-out queries generated by ChatGPT for each response.
We executed 100 prompts twice through GPT-5.2, once with minimal reasoning and once with high reasoning, totaling 200 responses.
Prompts covered 20 buyer journeys across four sectors (B2B SaaS, Finance, Consumer Tech, Health/Lifestyle), each consisting of 5 stages: Problem, Exploration, Comparison, Validation, Selection.
The citation rate represents the proportion of prompts where the response cited at least one external source.
The average citation quantifies the sources per cited response.
Fan-out queries are sub-queries the model generates internally for research before responding, surfaced via the Semrush API.
High Reasoning in GPT 5.2 Leads to More Citations and Searches
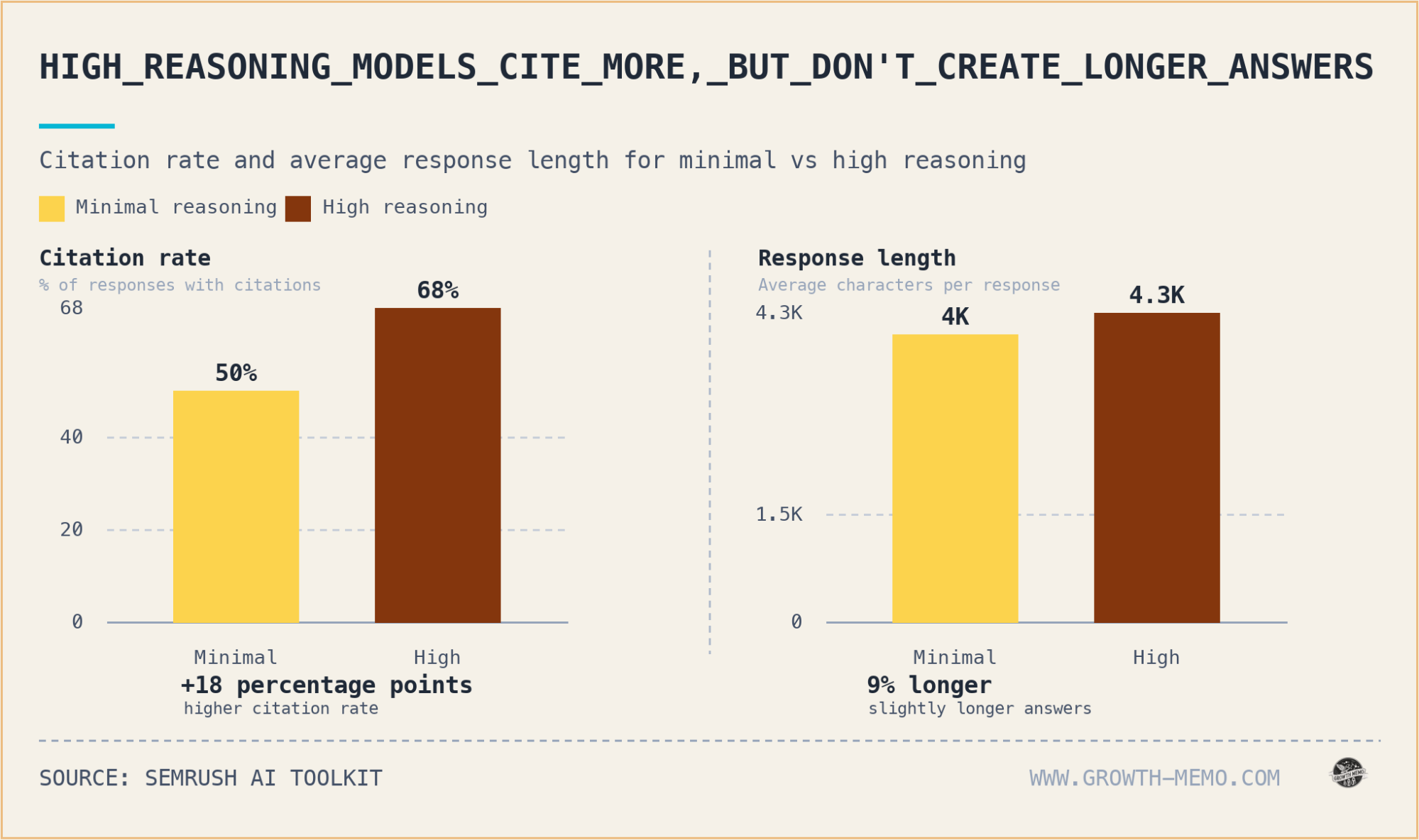
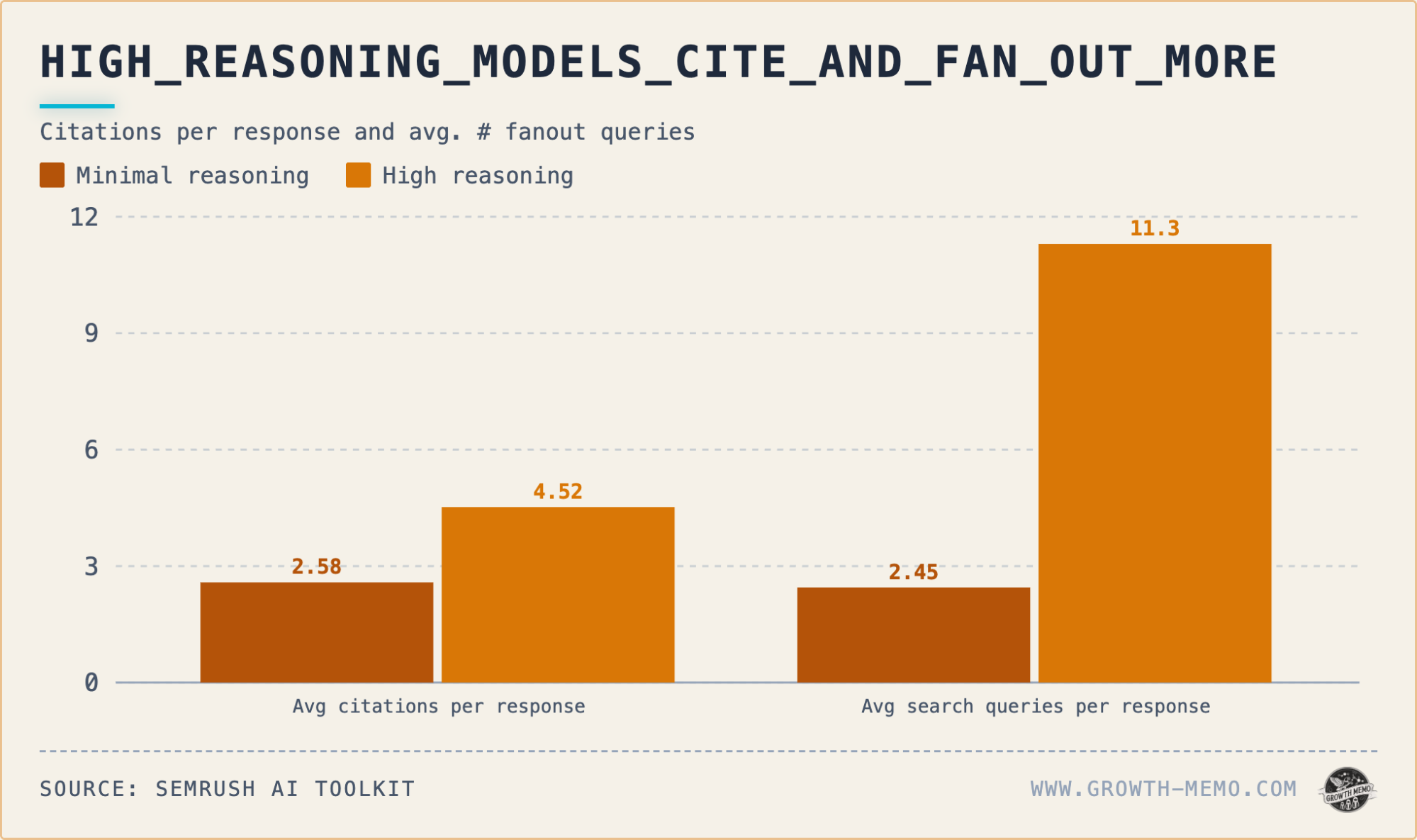
Activating high reasoning elevates the citation rate from 50% to 68%, nearly doubles the average sources per response (from 2.6 to 4.5), and multiplies fan-out queries by 4.6 times. High reasoning also draws from 173 unique domains versus 127 with minimal reasoning, with 99 domains appearing exclusively under high reasoning.
*Citation Rate signifies the share of prompts where at least one external source is cited.
This grounding is essential. When the model thinks more critically, it increasingly depends on web-based research, significantly impacting brand visibility, although user activation of reasoning remains uncertain.
Query intent provides a clearer indication than user demographics. Even free-tier users can access reasoning, albeit at limited rates, and ChatGPT automatically routes challenging prompts to Thinking mode. The critical question isn’t about affordability but about which prompts trigger reasoning automatically.
Complex comparisons, evaluation frameworks, compliance inquiries, and intricate shopping setups are most likely to invoke reasoning across all users. It’s crucial to categorize your audience by query type rather than paywall status.
High Reasoning Launches More Fan-out Queries in Later Stages
Users navigate problem-solving and purchasing decisions through stages, often within the same conversation. The distinction between minimal and high reasoning is not static; it varies based on the user’s journey stage.
For instance, consider a buyer evaluating CRM software:
Problem: “How do I know if my sales team needs a CRM?”
Exploration: “What types of CRM software exist for B2B SaaS?”
Comparison: “HubSpot vs. Salesforce vs. Pipedrive for a 50-person sales team.”
Validation: “Is HubSpot worth the price for mid-market B2B?”
Selection: “How do I get started with HubSpot Sales Hub?”
The following patterns are consistent across all 20 buyer journeys:
The citation rate increases as users progress through the funnel in both reasoning modes, but early-stage gaps close faster in high reasoning: +35pp at the Problem stage, only +5pp at Validation.
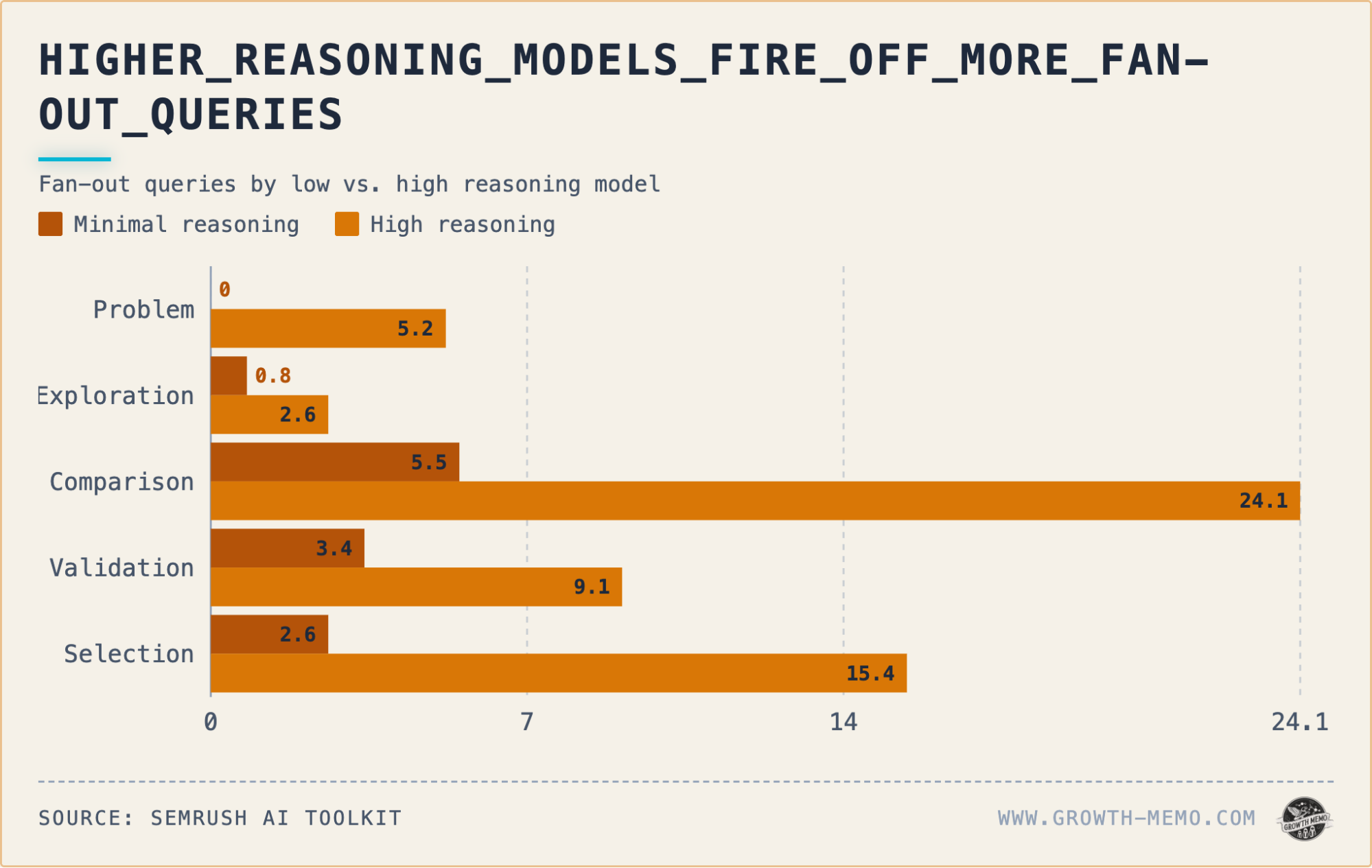
Fan-out queries peak during the Comparison stage, with high reasoning triggering 24 sub-queries per response compared to 5.5 in minimal reasoning. For Selection, these numbers are 15.4 and 2.6, respectively.
Average citations per response culminate during the Comparison stage (9.8 high, 5.8 minimal) and narrow during the Selection stage (4.7 high, 2.6 minimal). The citation pattern resembles an hourglass throughout the funnel.
Aggregately, minimal reasoning triggers 245 search queries over 100 prompts, while high reasoning triggers 1,130. In high reasoning, the model conducts thorough investigations for each prompt, with most research occurring during the Comparison and Selection phases.
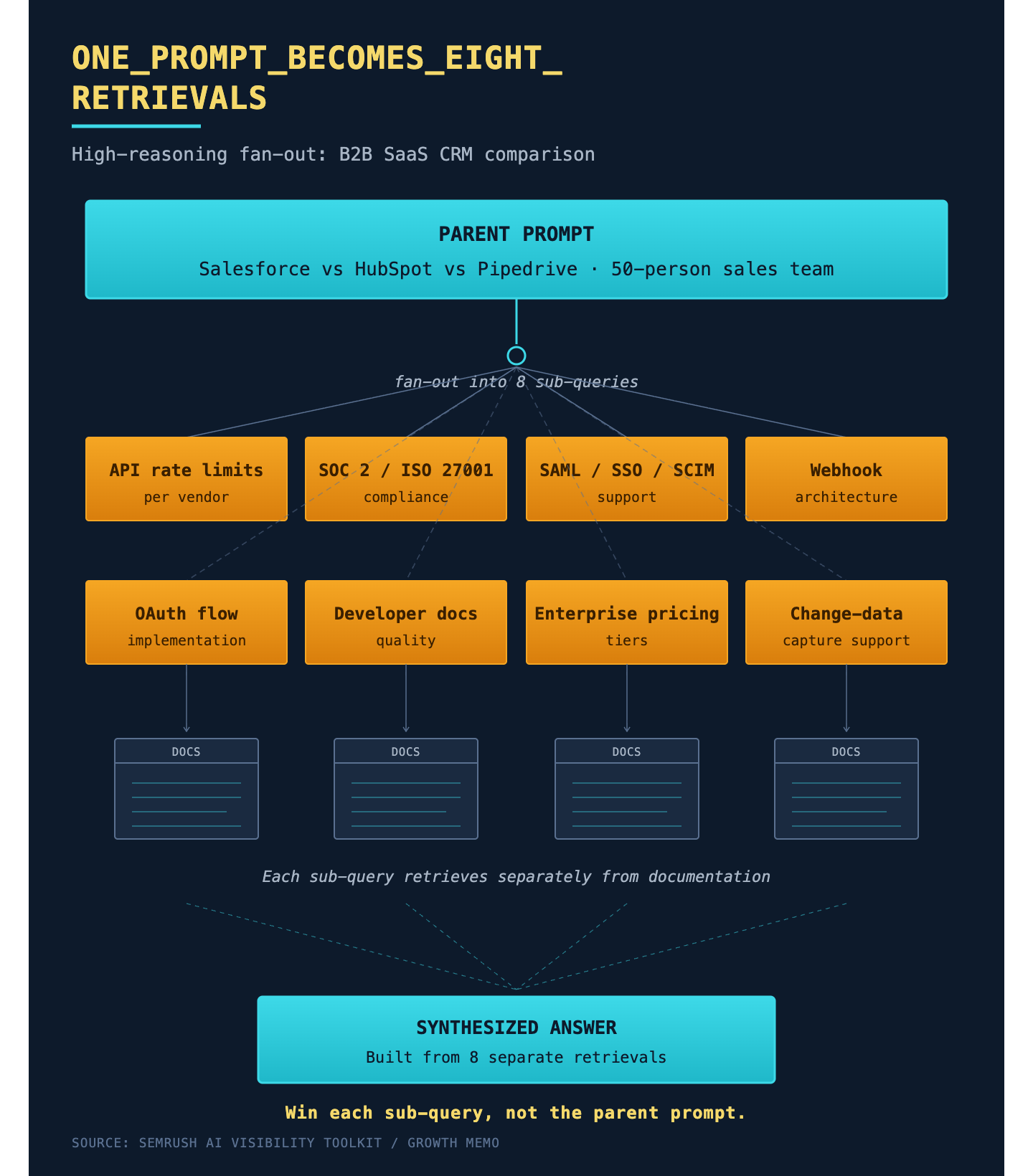
What does fan-out look like?
A B2B SaaS prompt that requires high reasoning, like comparing Salesforce, HubSpot, and Pipedrive for a 50-person sales team, breaks down into different queries regarding API rate limits, compliance standards, support tools, pricing tiers, and more. Each aspect requires specific retrieval. The brand that succeeds here will be the one with clean, accessible documentation for each sub-query, not merely ranking for the initial prompt.
The Selection stage features a remarkable variance in per-response queries: between 0 and 40 fan-out queries with the same five-stage cohort. This variance is driven mainly by the specificity of prompts.
Bounded prompts (like “should I finance through the dealer at 0% APR or use a bank?” or “draft an RFP to 3 SEO agencies”) run zero queries since the answer’s structure is predefined. On the other hand, open-ended tasks (“shopping list for a $3,000 home gym” or “which travel card system matches our grocery spending?”) prompt 28 to 40 queries. With no single query type dominating the Selection stage, the model’s research intensity correlates with the degrees of freedom left by the prompt.
For marketers: Capturing early-funnel visibility is highly dependent on reasoning mode. If buyers engage with ChatGPT in reasoning mode, your Problem-stage and Exploration-stage content become more relevant. Otherwise, visibility might only surface during the Comparison stage.
How Reasoning Alters Brand Representation in Conversations
A session with an LLM is more conversational than transactional. Does an initially cited brand endure till the concluding stage? If yes, early-funnel visibility multiplies. If no, each step is an independent battleground.
For minimal reasoning, persistence from the Problem stage to the Selection stage rarely happens. With high reasoning, however, continuous brand presence was recorded in 4 journeys across all 5 stages.
Within individual responses, high reasoning strongly relies on specific sources, with 51 out of 100 high-reasoning responses citing the same domain multiple times versus 26 in minimal reasoning. When committed, high reasoning cites a source repeatedly.
Analyzing brand names mentioned in the text provides a broader perspective. With a relaxed test criterion, persistence was noticeable in 3 high-reasoning sessions and 2 in minimal reasoning: HubSpot through CRM Selection, American Express in Business Credit Cards, and prominent mentions of Sony and Canon in Mirrorless Cameras. Consumer Tech again emerges, albeit without citation persistence, showing dominance through continuous conversation presence.
High reasoning establishes a consistent perception of the solution landscape throughout a session. Crucially, TOFU prompts possess enormous value. A brand appearing at the Problem stage is likely to be present at the Selection stage. Top-of-funnel content transcends mere brand awareness for AI visibility—it’s a predictor of where the model’s reasoning lands at decision-making points.
There are two more significant insights:
All four persistent journeys occur within Finance, indicating persistence thrives on authoritative-source content like regulatory pages and official brand sites, echoing the +28pp lift in Finance.
For marketers focusing on account-based strategies or market creation, visibility in reasoning mode is paramount as it’s the sole mode turning early funnel efforts into selection-stage citations.
Reasoning Mode: A Distinct Search Paradigm
The champions under minimal reasoning differ from those under high reasoning: Three out of four cited domains diverge. The diversity in source types and citation stages is unmistakable.
I’m particularly intrigued by these findings:
Firstly, measurement. It’s imperative to differentiate low and high reasoning in our prompt trackers to avoid oversimplification, as their functions are distinct.
This endeavor may seem costlier, but it significantly enhances prompt tracking accuracy.
Secondly, the relevance of funnel stages. In the latest AI Mode user behavior study, it was observed that users heavily rely on shortlists, much like they do with Google’s top results. It initially appeared that focusing on BOFU prompts to generate shortlists was most strategic.
Nonetheless, TOFU prompts carry substantial benefits due to their persistence potential. Brands entering the buyer journey early can remain present throughout. Mapping buyer journeys and tracking persistence offer the best insights.
This post originally appeared on the author’s website and is reproduced here with permission.
In my journey to optimize AI search visibility, I’ve discovered some of the best tools in Generative Engine Optimization (GEO). These tools not only boost citations in platforms like ChatGPT and Gemini but also guide me in selecting the most effective GEO platform for my needs.
Let me show you how you can measure AI search visibility effectively. It’s all about understanding how your content interacts with these advanced systems and using the right tools to enhance your reach.
Choosing the right GEO platform can be a game-changer. It’s essential to select a system that aligns perfectly with your goals and optimizes your AI-driven content for maximum impact.
When I receive emails like, “Hi Frank, I had ChatGPT look at our SEO and it has a bunch of recommendations. Can you take care of this for us?” I know I’m not alone. Many of us are facing similar queries from clients and managers.
The challenge lies in responding effectively without appearing defensive. We need to guide through what’s pertinent, what’s generic, and what’s simply off the mark.
Mastering SEO is one thing; communicating about AI-generated insights is another. Here’s how I’ve learned to handle AI suggestions tactfully.
Resist the Urge to Simply State, ‘ChatGPT is Wrong’
Although it might be tempting to outright dismiss the AI output, doing so can often backfire, leading to perceptions of being territorial instead of collaborative.
Rather than debating the AI, I focus on demonstrating my ability to assess AI output objectively and effectively.
My first step always involves acknowledging the effort behind the suggestions before diving into their evaluation.
Validate the Effort
I start with gratitude: thanking them for their input. It’s crucial to remember that these suggestions are usually a genuine attempt to contribute.
Rushing to critique AI recommendations can make them feel their effort is undervalued.
For instance, recently, my response was:
“Hi Dr. _______, thanks for sending this over. There are a few ideas worth considering. I also have thoughts on enhancing the model’s context with additional data. I’ll dive into it and update you.”
This approach shows appreciation, signifying my willingness to consider their suggestions earnestly.
Follow Up with What’s Worth Exploring
Begin by identifying the suggestions that hold potential value. This demonstrates a balanced view rather than outright rejection.
I often find value in AI suggestions, which can serve as a starting point for deeper analysis and refinement.
For example, if I receive AI feedback on page content, I review it to identify enhancements while ensuring alignment with our goals.
Let Them Realize When ChatGPT is Off
After exploring valuable insights, I walk clients through weaker points, encouraging them to understand the discrepancies independently.
We once had a client misled by AI into thinking competitors focused solely on one procedure. Through analysis, we revealed they covered diverse topics, allowing the client to recognize AI’s oversights.
Improve the Analysis, Don’t Debate Output
I explain that AI outputs reflect the input quality. When context or guidance is lacking, AI’s conclusions can be skewed.
For example, AI suggested 3,000+ word procedure pages. However, top-ranking pages were shorter, affirming my experience that word count alone doesn’t influence rankings.
Thus, refining prompts, not necessarily dismissing AI, is where the focus should be.
Embrace and Master AI-Related Emails
Such emails are inevitable, and learning to address them efficiently strengthens our role as marketing leaders.
Mastering this skill means keeping clients engaged, bolstering our expertise, and managing time efficiently.
The next time you’re on the receiving end, remember to blend professionalism with collaboration and expertise.
I’ve come across some intriguing research from Princeton and UW recently that sheds light on a rather surprising aspect of AI – it’s apparent tendency to conceal sponsorship nearly 65% of the time. As I pondered on this, it struck me how crucial this finding is for those of us navigating the evolving landscape of AI-driven marketing strategies.
This revelation made me question how we’re measuring advertising effectiveness. Are we truly accounting for all variables, especially those hidden from plain sight? For those of us invested in Answer Engine Optimization (AEO), this piece of the puzzle could significantly tweak how we approach our measurement techniques and refine our marketing strategies for 2026.
What does this mean for each of us in marketing and advertising? It’s a call to action to re-evaluate and possibly overhaul our current strategies, ensuring we adapt to these covert tendencies within AI functionalities. I’m convinced that understanding these nuances will empower us to craft more transparent and effective campaigns, ultimately enhancing our overall AEO outcomes.
While AI continues to surprise us with its capabilities, I find it crucial to stay updated and adaptable, utilizing insights like these to steer our strategies intelligently. How do you plan to integrate this newfound knowledge into your 2026 marketing strategy?
I recently discovered a fascinating development from OpenAI that has the potential to revolutionize e-commerce advertising. They’ve started transforming product catalogues into automated ads within ChatGPT, allowing retailers to seamlessly scale their campaigns.
Retailers now have the option to connect their product feeds directly to ChatGPT. This integration means that the platform can generate ads automatically, using product names, images, and other attributes. Gone are the days of manually crafting campaigns!
For users, these ads will still appear beneath responses and remain clearly labeled as sponsored content. There’s no change here in terms of user experience.
As someone interested in how e-commerce brands operate, I’m intrigued by this update. It significantly reduces the barriers that retailers with large inventories face when running scaled ads.
Brands have the flexibility to establish rules on which products are featured, allowing the system to efficiently generate ads. It reminds me of how shopping campaigns function on platforms like Google, leveraging structured feeds for both organic and paid visibility.
Previously, ChatGPT could use product data for answering queries but not for advertising purposes. Now, with this advancement, the same data supports both functions, bridging the gap between organic presence and paid campaigns.
This shift signals how OpenAI is looking to monetize shopping. Instead of taking a slice of transactions, they’re targeting ad budgets typically spent on platforms like Amazon and Meta.
Industry analyst Debra Aho Williamson calls this shift to feed-based automation a necessity, highlighting ChatGPT’s unique approach to serving ads based on conversational intent, a distinct advantage.
According to ad tech partners like StackAdapt, the integration with existing feeds is straightforward, easing the adoption process.
This latest move is part of a series of updates that focus on performance, including cost-per-click bidding and new conversion tracking tools. Cost-per-action models are reportedly in development, suggesting an even deeper focus on performance advertising.
I’m eager to see more retailers experimenting with ChatGPT as a performance channel. The ease of setup might make this an attractive option, but the real test will be if conversational intent can drive conversions as efficiently as traditional methods.
The bottom line is that OpenAI is effectively turning product feeds into ads, making ChatGPT a more potent, scalable channel for e-commerce advertising.