
An analysis of 200 GPT-5.2 responses revealed that enhanced reasoning increases the citation of sources, deepens research, and boosts early-stage funnel visibility.
Subscribe to Growth Memo for weekly expert insights delivered straight to your inbox at no cost.
I’ve explored how AI provides a conversational experience through large language models (LLMs) and chatbots. However, I’ve noticed that no one has thoroughly examined the evolution of citations and mentions within these conversations.
By examining data from the Semrush AI Visibility Toolkit, I reviewed 20 buyer journeys across four industries, comparing the high and low reasoning of ChatGPT5.2.
In this analysis, you’ll discover:
- How high reasoning cites a vastly different web with only 25.6% domain overlap and which source types gain or lose prominence.
- The renewed importance of TOFU content: Brands cited at the Problem stage tend to persist through to the Selection stage under high reasoning.
- How to differentiate your prompt tracking by reasoning modes, ensuring your AI visibility reports reflect two distinct systems instead of an average.
Methodology
Data collection utilized the Semrush AI Visibility Toolkit to capture prompts, citations, and fan-out queries generated by ChatGPT for each response.
- We executed 100 prompts twice through GPT-5.2, once with minimal reasoning and once with high reasoning, totaling 200 responses.
- Prompts covered 20 buyer journeys across four sectors (B2B SaaS, Finance, Consumer Tech, Health/Lifestyle), each consisting of 5 stages: Problem, Exploration, Comparison, Validation, Selection.
- The citation rate represents the proportion of prompts where the response cited at least one external source.
- The average citation quantifies the sources per cited response.
- Fan-out queries are sub-queries the model generates internally for research before responding, surfaced via the Semrush API.
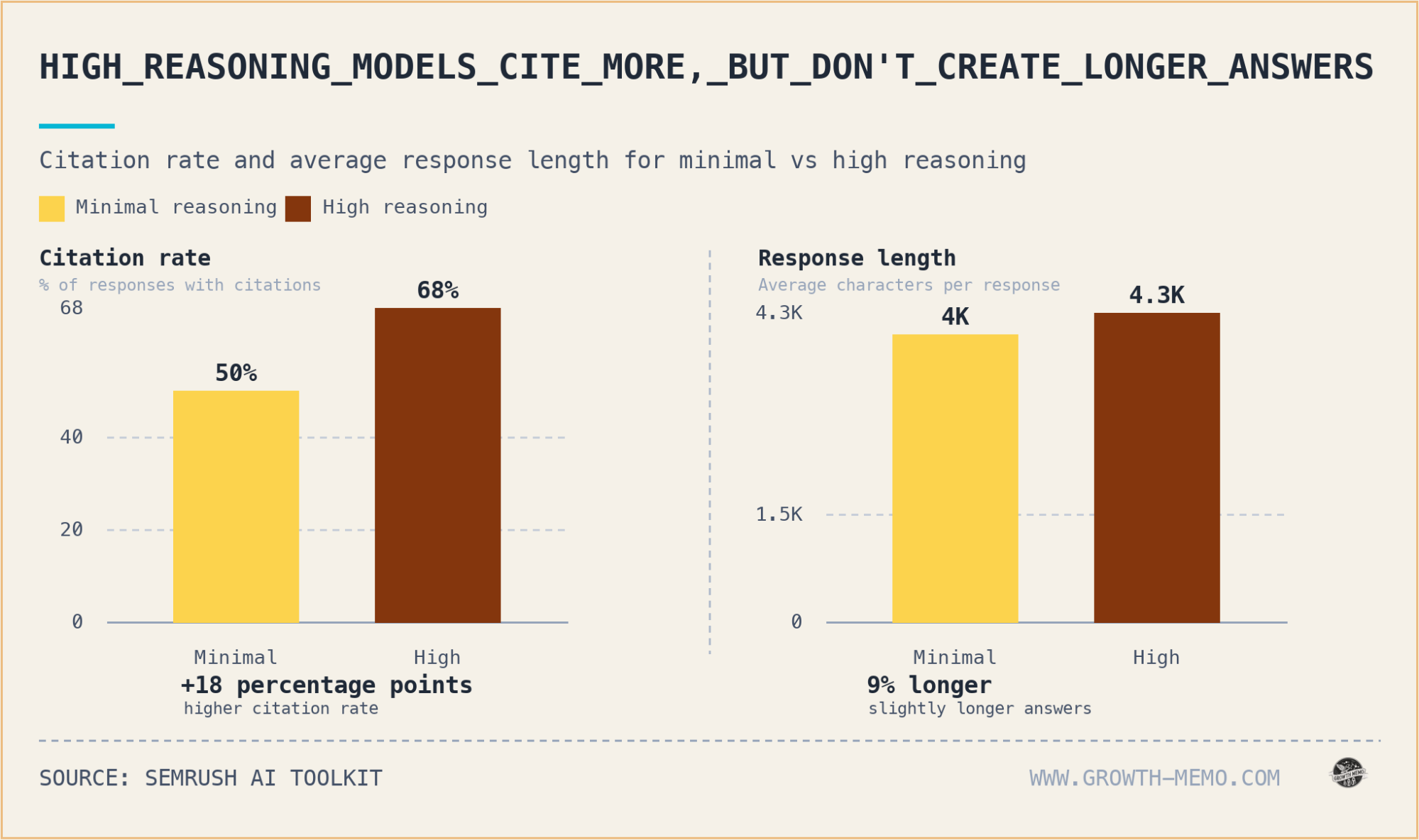
High Reasoning in GPT 5.2 Leads to More Citations and Searches
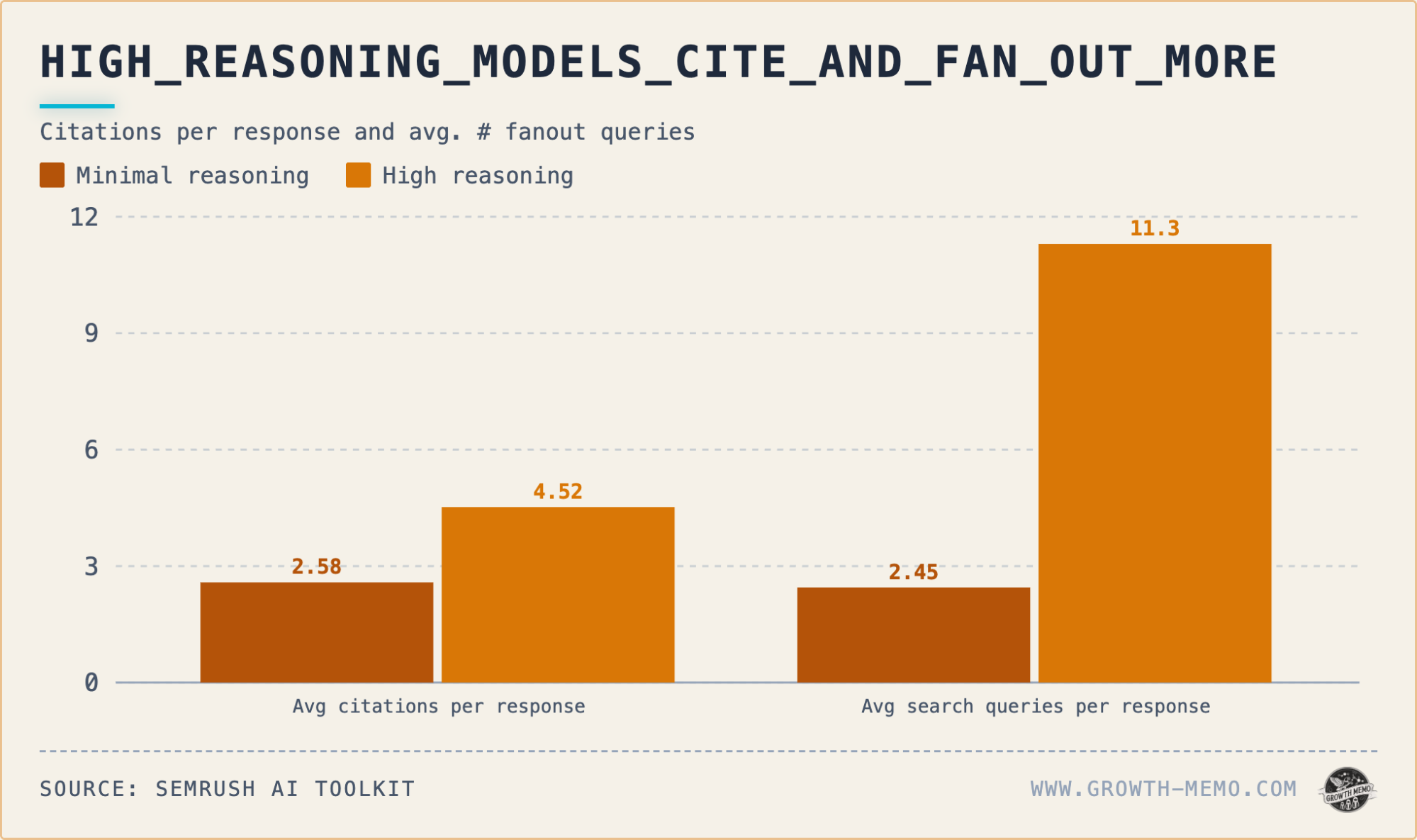
Activating high reasoning elevates the citation rate from 50% to 68%, nearly doubles the average sources per response (from 2.6 to 4.5), and multiplies fan-out queries by 4.6 times. High reasoning also draws from 173 unique domains versus 127 with minimal reasoning, with 99 domains appearing exclusively under high reasoning.
*Citation Rate signifies the share of prompts where at least one external source is cited.
This grounding is essential. When the model thinks more critically, it increasingly depends on web-based research, significantly impacting brand visibility, although user activation of reasoning remains uncertain.
Query intent provides a clearer indication than user demographics. Even free-tier users can access reasoning, albeit at limited rates, and ChatGPT automatically routes challenging prompts to Thinking mode. The critical question isn’t about affordability but about which prompts trigger reasoning automatically.
Complex comparisons, evaluation frameworks, compliance inquiries, and intricate shopping setups are most likely to invoke reasoning across all users. It’s crucial to categorize your audience by query type rather than paywall status.
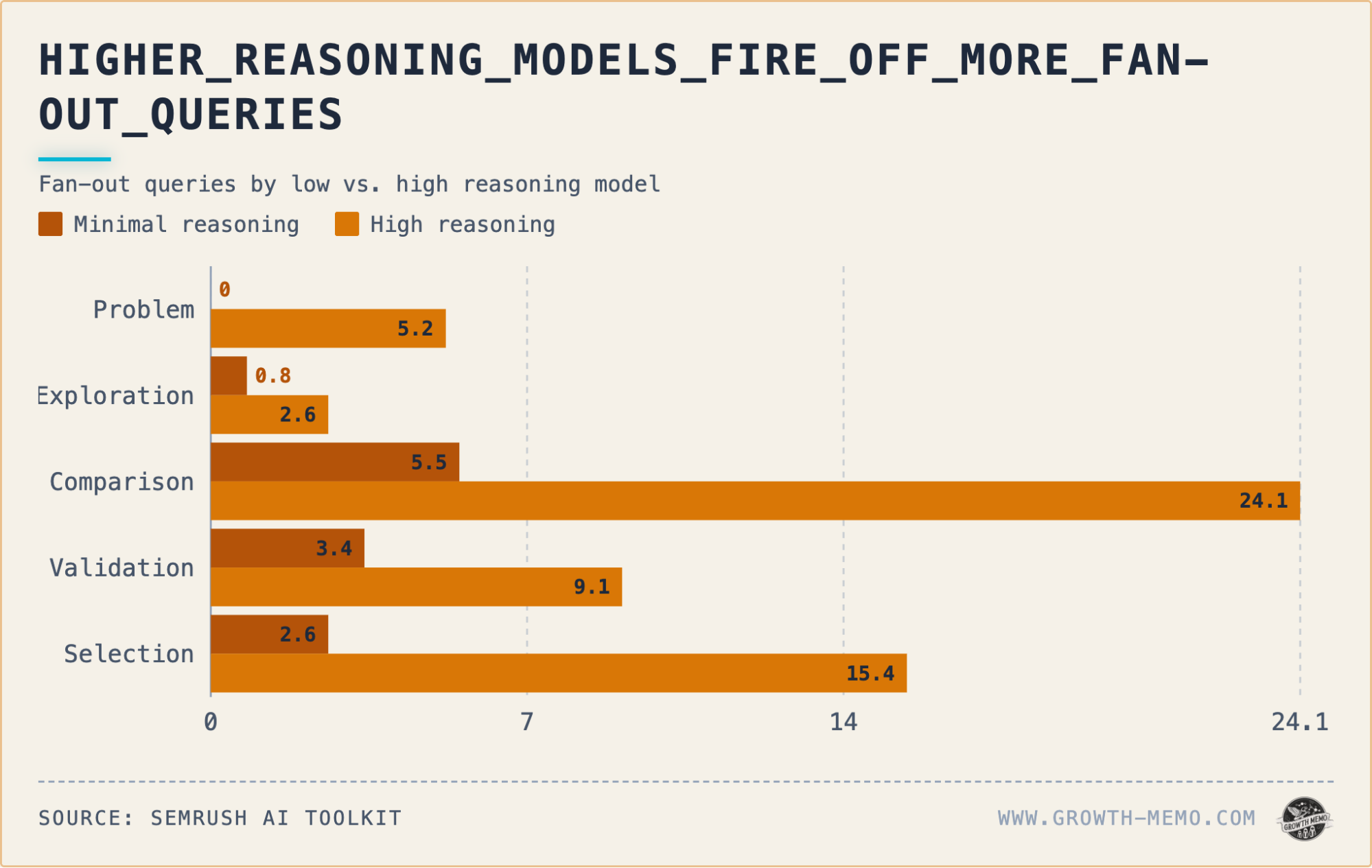
High Reasoning Launches More Fan-out Queries in Later Stages
Users navigate problem-solving and purchasing decisions through stages, often within the same conversation. The distinction between minimal and high reasoning is not static; it varies based on the user’s journey stage.
For instance, consider a buyer evaluating CRM software:
- Problem: “How do I know if my sales team needs a CRM?”
- Exploration: “What types of CRM software exist for B2B SaaS?”
- Comparison: “HubSpot vs. Salesforce vs. Pipedrive for a 50-person sales team.”
- Validation: “Is HubSpot worth the price for mid-market B2B?”
- Selection: “How do I get started with HubSpot Sales Hub?”

The following patterns are consistent across all 20 buyer journeys:
- The citation rate increases as users progress through the funnel in both reasoning modes, but early-stage gaps close faster in high reasoning: +35pp at the Problem stage, only +5pp at Validation.
- Fan-out queries peak during the Comparison stage, with high reasoning triggering 24 sub-queries per response compared to 5.5 in minimal reasoning. For Selection, these numbers are 15.4 and 2.6, respectively.
- Average citations per response culminate during the Comparison stage (9.8 high, 5.8 minimal) and narrow during the Selection stage (4.7 high, 2.6 minimal). The citation pattern resembles an hourglass throughout the funnel.
Aggregately, minimal reasoning triggers 245 search queries over 100 prompts, while high reasoning triggers 1,130. In high reasoning, the model conducts thorough investigations for each prompt, with most research occurring during the Comparison and Selection phases.
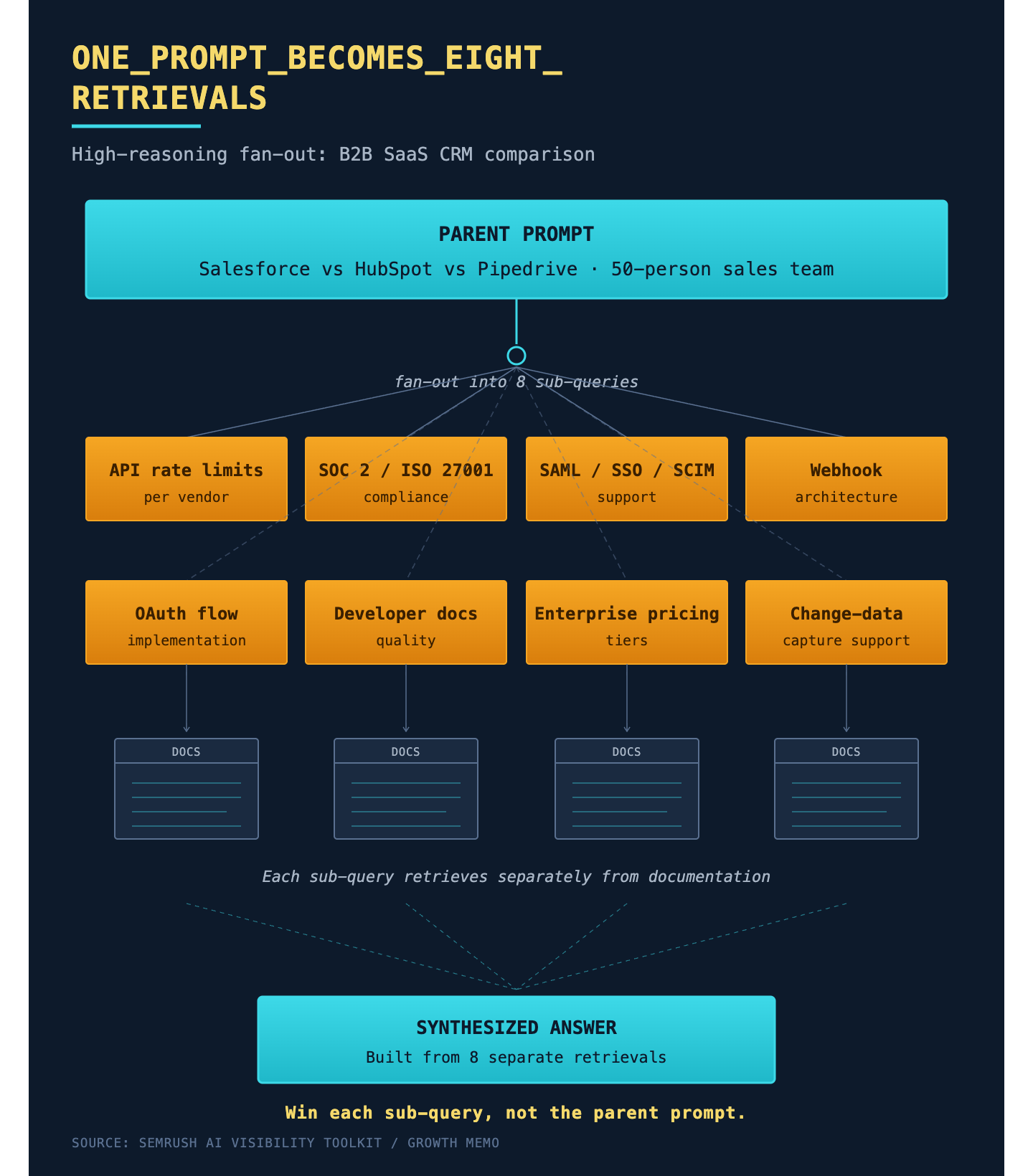
What does fan-out look like?
A B2B SaaS prompt that requires high reasoning, like comparing Salesforce, HubSpot, and Pipedrive for a 50-person sales team, breaks down into different queries regarding API rate limits, compliance standards, support tools, pricing tiers, and more. Each aspect requires specific retrieval. The brand that succeeds here will be the one with clean, accessible documentation for each sub-query, not merely ranking for the initial prompt.
The Selection stage features a remarkable variance in per-response queries: between 0 and 40 fan-out queries with the same five-stage cohort. This variance is driven mainly by the specificity of prompts.
Bounded prompts (like “should I finance through the dealer at 0% APR or use a bank?” or “draft an RFP to 3 SEO agencies”) run zero queries since the answer’s structure is predefined. On the other hand, open-ended tasks (“shopping list for a $3,000 home gym” or “which travel card system matches our grocery spending?”) prompt 28 to 40 queries. With no single query type dominating the Selection stage, the model’s research intensity correlates with the degrees of freedom left by the prompt.
For marketers: Capturing early-funnel visibility is highly dependent on reasoning mode. If buyers engage with ChatGPT in reasoning mode, your Problem-stage and Exploration-stage content become more relevant. Otherwise, visibility might only surface during the Comparison stage.
How Reasoning Alters Brand Representation in Conversations
A session with an LLM is more conversational than transactional. Does an initially cited brand endure till the concluding stage? If yes, early-funnel visibility multiplies. If no, each step is an independent battleground.
For minimal reasoning, persistence from the Problem stage to the Selection stage rarely happens. With high reasoning, however, continuous brand presence was recorded in 4 journeys across all 5 stages.
Within individual responses, high reasoning strongly relies on specific sources, with 51 out of 100 high-reasoning responses citing the same domain multiple times versus 26 in minimal reasoning. When committed, high reasoning cites a source repeatedly.
Analyzing brand names mentioned in the text provides a broader perspective. With a relaxed test criterion, persistence was noticeable in 3 high-reasoning sessions and 2 in minimal reasoning: HubSpot through CRM Selection, American Express in Business Credit Cards, and prominent mentions of Sony and Canon in Mirrorless Cameras. Consumer Tech again emerges, albeit without citation persistence, showing dominance through continuous conversation presence.
High reasoning establishes a consistent perception of the solution landscape throughout a session. Crucially, TOFU prompts possess enormous value. A brand appearing at the Problem stage is likely to be present at the Selection stage. Top-of-funnel content transcends mere brand awareness for AI visibility—it’s a predictor of where the model’s reasoning lands at decision-making points.
There are two more significant insights:
- All four persistent journeys occur within Finance, indicating persistence thrives on authoritative-source content like regulatory pages and official brand sites, echoing the +28pp lift in Finance.
- For marketers focusing on account-based strategies or market creation, visibility in reasoning mode is paramount as it’s the sole mode turning early funnel efforts into selection-stage citations.
Reasoning Mode: A Distinct Search Paradigm
The champions under minimal reasoning differ from those under high reasoning: Three out of four cited domains diverge. The diversity in source types and citation stages is unmistakable.

I’m particularly intrigued by these findings:
Firstly, measurement. It’s imperative to differentiate low and high reasoning in our prompt trackers to avoid oversimplification, as their functions are distinct.
This endeavor may seem costlier, but it significantly enhances prompt tracking accuracy.
Secondly, the relevance of funnel stages. In the latest AI Mode user behavior study, it was observed that users heavily rely on shortlists, much like they do with Google’s top results. It initially appeared that focusing on BOFU prompts to generate shortlists was most strategic.
Nonetheless, TOFU prompts carry substantial benefits due to their persistence potential. Brands entering the buyer journey early can remain present throughout. Mapping buyer journeys and tracking persistence offer the best insights.
This post originally appeared on the author’s website and is reproduced here with permission.
Inspired by this post on Search Engine Land.

Leave a Reply