
I’ve noticed a startling trend with the latest AI models: they’re wreaking havoc on my SEO workflows. The recent benchmark results show that there’s a significant 9% drop in SEO accuracy with newer models like Claude, Gemini, and GPT.
It turns out, these AI models aren’t just glitching—it’s all part of how they’re optimized now for deeper reasoning rather than giving quick, straightforward answers.
Last year, it was easy to think that newer meant better. But the results from our AI SEO benchmark with Claude Opus 4.5, Gemini 3 Pro, and ChatGPT-5.1 Thinking make it clear: newer models aren’t just failing to improve, they’re actually less effective.
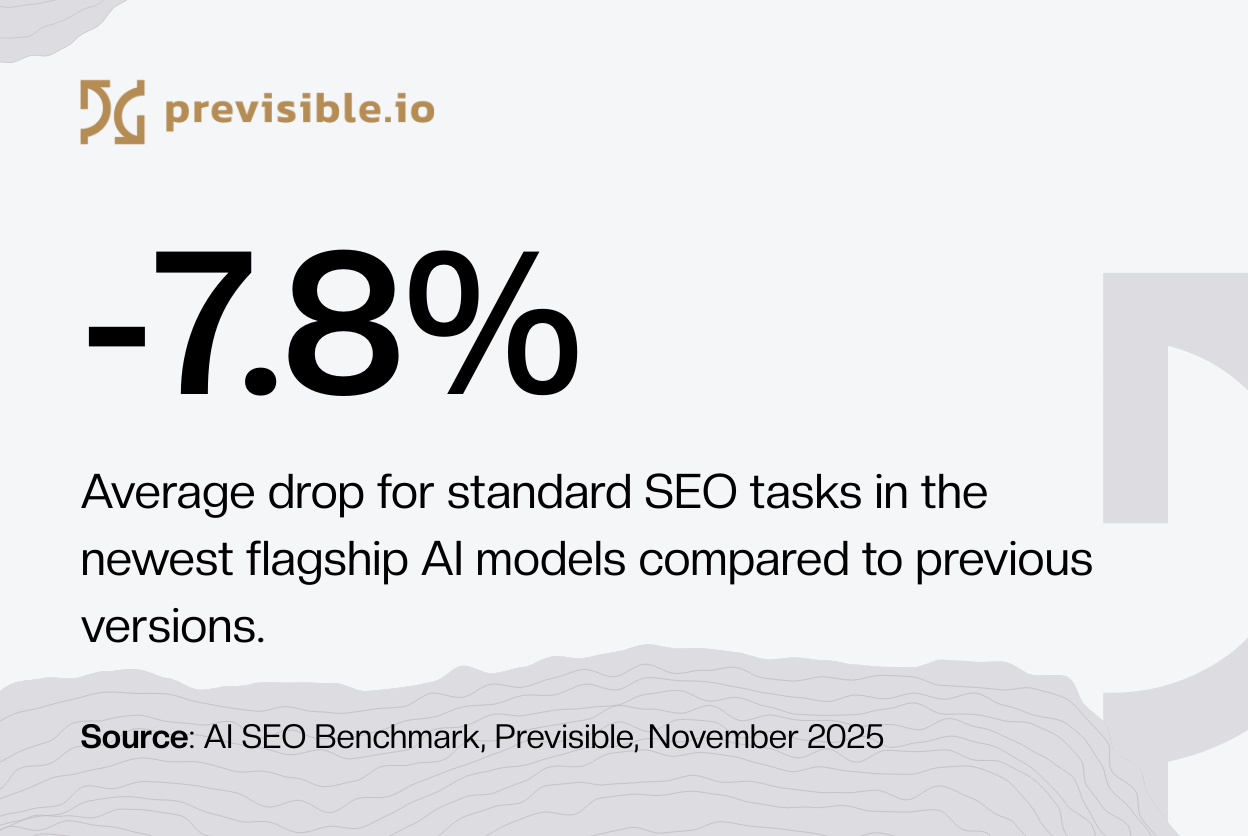
I can no longer rely on models out of the box. If I want to get back to, or surpass, the accuracy benchmarks, I need to focus on structuring my workflow differently. Just using raw prompts isn’t going to cut it anymore.
One of the biggest shifts I need to make is moving away from the chat interface and towards more structured workflows. This means considering tools like OpenAI’s Custom GPTs or Google’s Gemini Gems.

I’ve realized that hard-coding context is crucial. Without strict guidelines, these models stray, giving generic instead of tailored advice.
The key takeaways for me are clear: I shouldn’t rush to upgrade to the newest models simply because they’re the latest. I shouldn’t be stuck on single prompts without robust contextual backgrounds either.
In this new age of AI agents, my role isn’t becoming obsolete. Instead, it’s evolving, requiring me to architect AI systems and apply my judgment to refine and steer outputs effectively.
Inspired by this post on Search Engine Land.

Leave a Reply