
I’ve been contemplating how even when content ranks well on search engines, it can still falter when it comes to AI retrieval. These AI systems assess pages very differently, based not just on their rank, but also on how information is extracted, embedded, and structured.
There’s an intriguing disconnect between traditional ranking and being successfully parsed by AI. A webpage can comply with excellent SEO guidelines and still miss the mark with AI-generated responses and citations.
In many situations, content quality isn’t the issue. It’s about whether the information can be reliably extracted after being segmented and embedded by AI systems.
This challenge is becoming increasingly common as search engines view pages as complete entities, but AI systems dive into the raw HTML to extract meaning from fragments rather than entire pages.
Crucial insights can get lost if they’re not appropriately structured or if they rely too heavily on visual rendering or inference.
This leads to a divergence between what’s visible in search and what’s accessible via AI, where content might exist in an index but lacks substantial meaning for AI retrieval.
The visibility gap is something I’ve been grappling with: Understanding the difference between ranking versus retrieval is key.
As search winds its processes around rankings, AI systems engage with fragments operated within a different representation of similar information. It’s here the visibility gap takes shape.
A page might rank high, but if its embedded content is incomplete or poorly organized, then the AI retrieval process becomes unreliable.
Treat retrieval as an entirely unique visibility factor. It doesn’t override SEO, but increasingly defines whether content can be effectively surfaced, summarized, or cited when AI filters come into play.
Dig deeper: What is GEO (generative engine optimization)?Another structural issue arises when content never even becomes accessible to AI. Many AI crawlers only parse raw HTML without executing JavaScript or client-side rendering. This creates blind spots, especially for JavaScript-heavy sites where the core content may appear in Google’s index but remains invisible to AI.
Testing if your content appears in initial HTML is quite straightforward. Simply inspect the HTML response at fetch time rather than the version rendered in a browser.
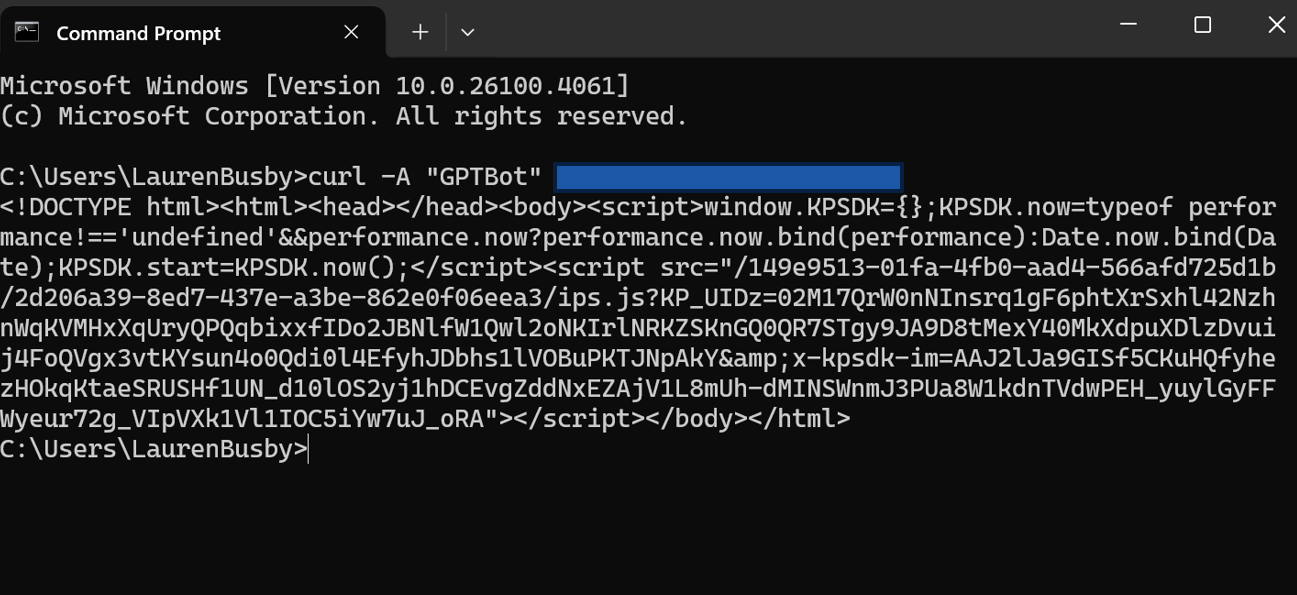
Running requests with AI user agents like “GPTBot” reveals if your site returns blank HTML even if it appears fully populated to users, highlighting its absence in initial responses.
Tools like Screaming Frog can validate this at scale. Disabling JavaScript rendering can reveal what AI systems see—if your essential content only displays with JavaScript, it can be indexed by Google’s search but not by AI retrieval systems.
Keep in mind that even with content returned, excessive code and scripts can hinder extraction by AI systems. Cleaner HTML results in more reliable embeddings, enhancing AI visibility.
To tackle this, deliver fully rendered HTML when AI systems fetch your content. Pre-rendering can often fix these retrieval issues, ensuring content is present in initial responses.
Delivery can be managed effectively at the edge layer, providing AI crawlers with complete pages instantly. Human users receive a dynamic version while AI sees what it needs to extract meaning.
If pre-rendering isn’t viable, focus on ensuring primary content is accessible in a clean initial HTML response, even without script execution.
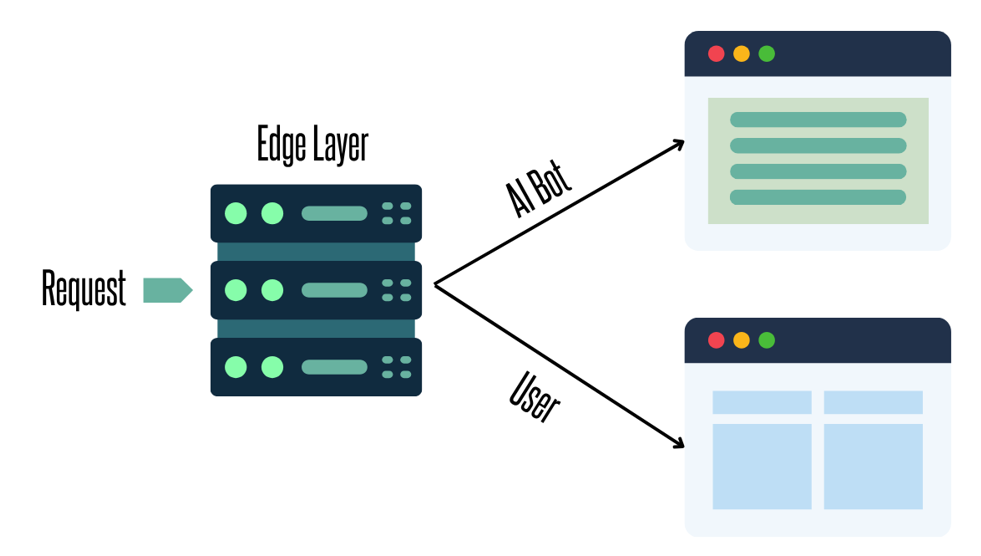
Columns laden with excessive markup can interfere with proper extraction, diminishing the content’s value.
The next structural failure to consider is when content is optimized for keywords rather than the entities AI seeks. Traditional SEO applies keyword relevance, but AI retrieves based on entity relationships.
Without clear definition, entity signals can weaken, causing pages to underperform in retrieval even if they rank well for queries.
AI evaluates sections independently once extracted, making the consistency of header tags essential to maintaining coherence.
Ensuring sections have a single, defined purpose allows for better embedding when isolated from larger context.
Finally, conflicting signals or metadata can dilute the semantics retrieved by AI, creating noise and ambiguity.
SEO doesn’t have to mean choosing between ranking and retrieval anymore. Both must be prioritized to succeed in today’s landscape.
Inspired by this post on Search Engine Land.

Leave a Reply