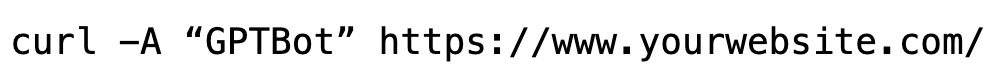I’m tracking an important AMP update from Google Search: users who tap AMP results will now be sent directly to publisher-hosted AMP pages instead of cached AMP pages shown inside Google’s AMP viewer.
A Google spokesperson told Search Engine Land, “Starting today, we are updating how we connect users to AMP pages from Search, taking them directly to the AMP host pages.”
Google also made it clear that this is not a ranking change. AMP content will continue to rank like any other webpage, and Google said the serving and ranking of AMP content in Google Search and Google Discover will remain the same.
From my perspective, the practical value here is mostly on the publisher side. By sending searchers straight to the AMP host page, Google says publishers should have simpler analytics management and tracking, along with less maintenance work when creating and supporting AMP content.
Google told us it will continue to support the open-source AMPhtml format, and it also posted the update in its Search documentation.
I also think it’s worth noting how much AMP’s role has changed over time. AMP has not received preferential treatment in Google’s Top Stories for a while, and AMP pages are much less common to encounter than they once were. Search Engine Land even turned off AMP in 2021.
It has been a long time since I’ve had much reason to cover AMP closely, but this change matters because it shifts the user journey back to publisher-hosted pages while keeping AMP’s ranking treatment unchanged.
What Google said. Google wrote, “Released the June 2026 spam update, which applies globally and to all languages. The rollout may take a few days to complete.”
Timing. I expect this update to move fairly quickly, since Google said the rollout may take only a few days to finish.
Why I care. Google releases search ranking updates several times each year, and spam updates are meant to target sites that use manipulative tactics to abuse the ranking system. If a site is not relying on those kinds of practices, I would not expect it to be the main target of this update.
More on spam updates. Google’s documentation explains that its automated systems are always working to detect search spam, but the company occasionally makes notable improvements to those systems and labels them as spam updates.
Google also points to SpamBrain, its AI-based spam-prevention system, as one example of how it improves its ability to identify spam and catch new types of abuse.
If I saw a ranking change after a spam update, my first step would be to review Google’s spam policies and make sure the site is complying with them. Sites that violate those policies may rank lower or disappear from results, while improvements can help over time if Google’s automated systems recognize that the site is now compliant.
For link spam updates specifically, Google says recovery can work differently. If Google removes the value of spammy links, any ranking benefit those links once created is lost, and that benefit cannot be regained simply by cleaning up the links later.
ChatGPT citations prioritize ranking and precision, not length. I recently came across an intriguing study conducted by AirOps that examined how ChatGPT assigns citations. It revealed that pages with precise, narrow answers are favored over lengthy, broad content.
After reviewing 16,851 queries, AirOps found that pages with well-matched headings and focused content rank higher in citations. Impressively, the top retrieval result was cited 58% of the time, indicating a strong preference for relevance over mere volume.
Why this matters to us. These findings are crucial if we’re aiming to earn more ChatGPT citations. To succeed, we need to prioritize winning retrieval spots, mirroring queries in our headings, and providing highly precise answers.
Key insights. The study emphasized retrieval ranking as a pivotal factor. Top-ranking pages were cited 58.4% of the time, compared to only 14.2% for pages positioned tenth. This highlights the significant impact of retrieval rank on citation frequency.
Another crucial point I noted was the importance of heading relevance. Pages where the heading strongly matched the query were cited 41% of the time, significantly outperforming less matched options.
It also showed that narrowly focused pages outperform comprehensive guides, challenging the typical “ultimate guide” approach many of us might consider effective.
Factors driving citations. From what I gathered in the study, being well-ranked, using query-matching headings, and maintaining content focus are key to earning citations from ChatGPT.
Additional structural insights: While structure like JSON-LD markup offered a slight boost in citations, it wasn’t as critical as I initially thought. Pages with this markup had a citation rate of 38.5% versus 32.0% for those without. Interestingly, articles with 4 to 10 subheadings performed notably well.
Furthermore, content length had diminishing returns. Pages with 500 to 2,000 words performed best in citations, whereas those exceeding 5,000 words were cited less than even the briefest ones.
Freshness matters, but only to an extent. Content published within 30 to 89 days had the best performance in terms of citations, while newer content underperformed slightly, suggesting the need for time to build retrieval signals.
Older content, particularly those older than 2 years, struggled in citations, implying the potential benefits of refreshing existing content if it currently ranks well for target queries.
Understanding the data. AirOps examined 50,553 responses derived from 16,851 unique queries, each run three times. The exhaustive dataset encompassed 353,799 pages across various sectors and query types.
When the March 2026 Google core update hit, I couldn’t help but notice the dramatic shifts it created. Nearly 80% of the top search results were reshuffled. This update really boosted brands and official sites while leaving some aggregators scrambling to catch up.
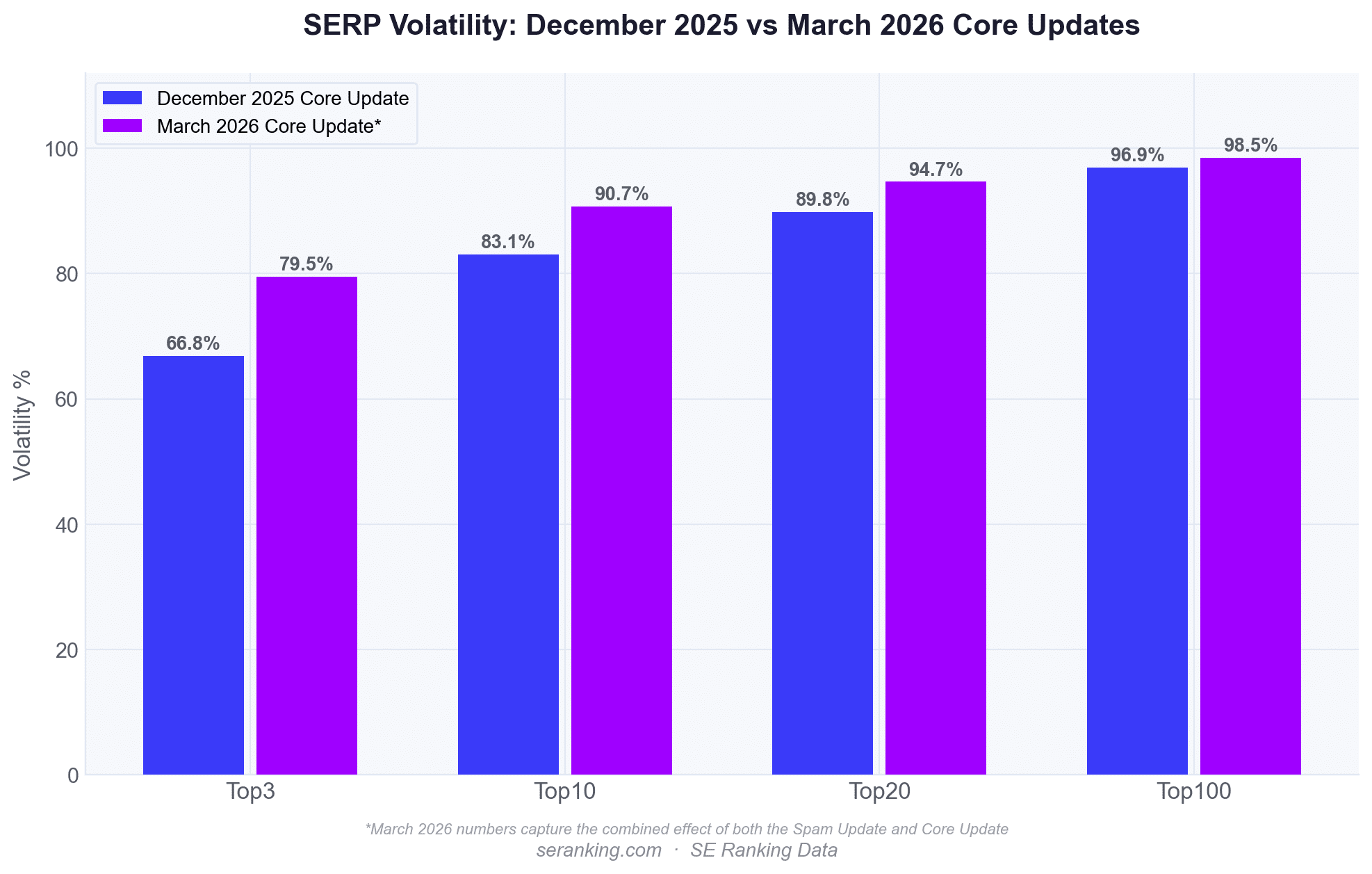
I stumbled upon SE Ranking’s exclusive data, which highlighted how much more volatile the March update was compared to December 2025. Surprisingly, nearly one-in-four top-10 pages disappeared from the top 100 altogether!
The data breakdown. I saw increased volatility across all ranking tiers.
In the top 3, 79.5% of URLs changed positions, a notable jump from December’s 66.8%. Similarly, 90.7% shifted in the top 10, compared to 83.1% earlier.
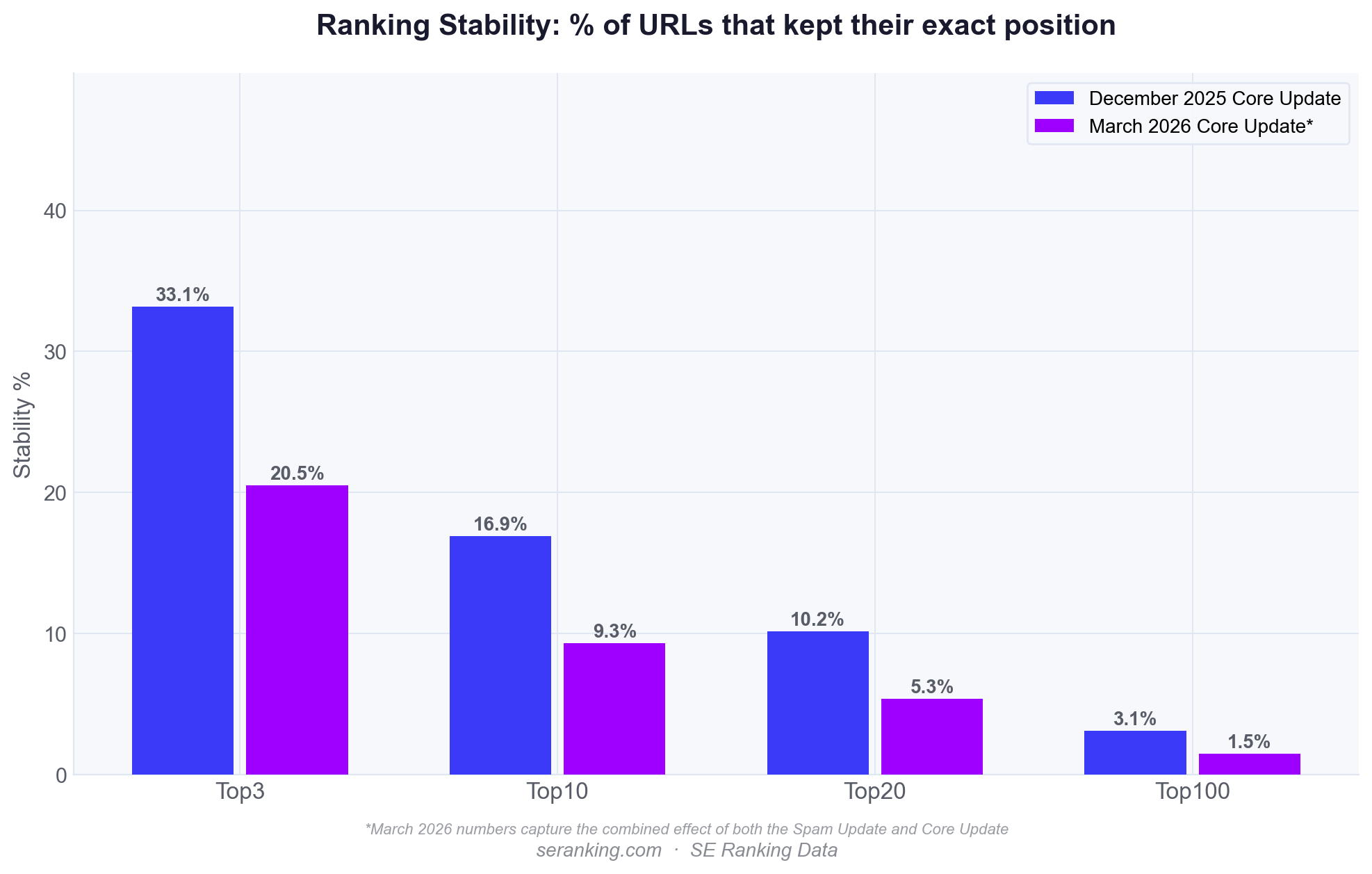
Stability? Well, it took a nosedive. Only 20.5% of top 3 URLs stayed put, down from 33.1%, and in the top 10, stability fell to 9.3%, down from 16.9%.
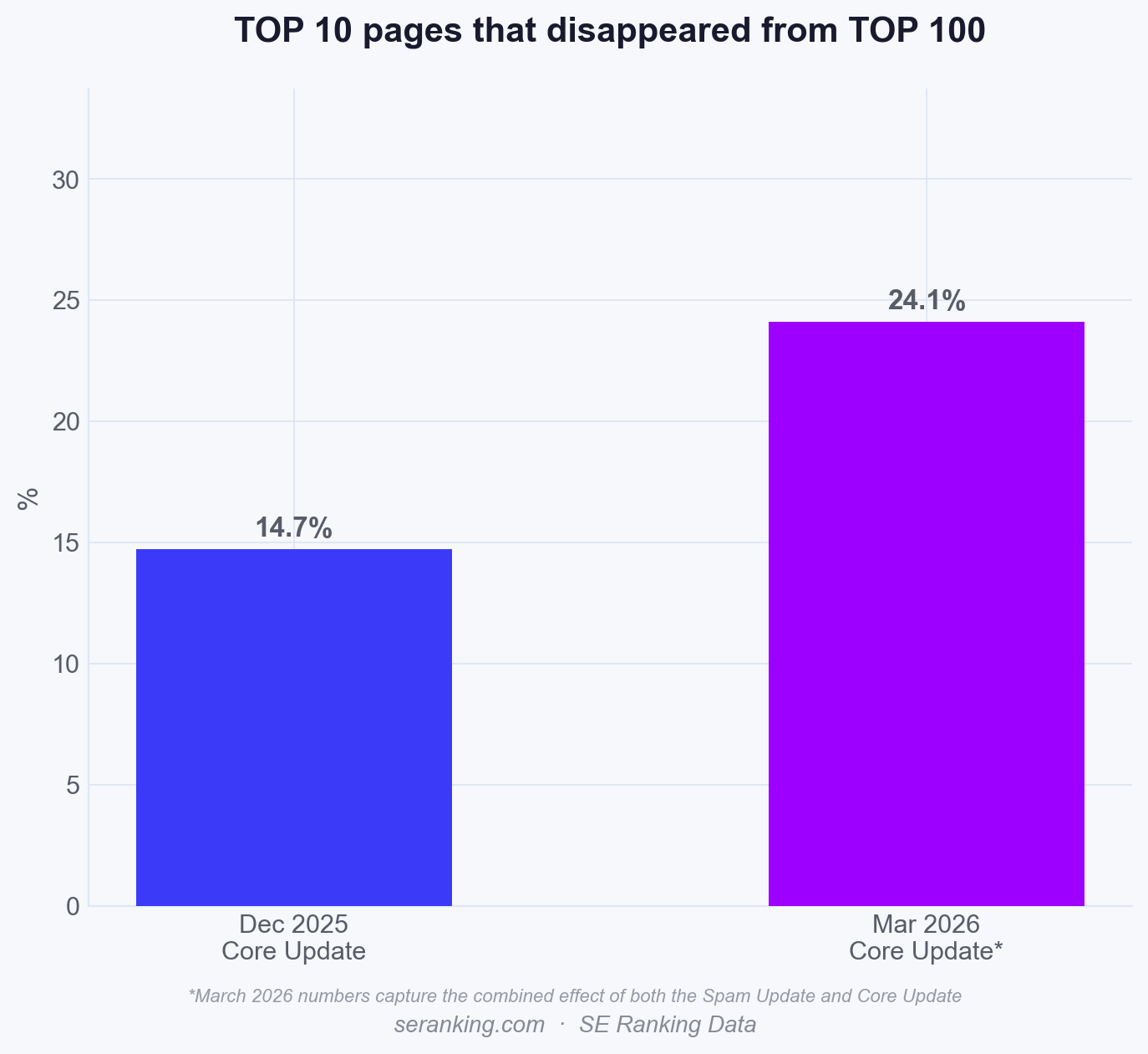
Then there’s the churn: about 24.1% of pages in the top 10 vanished from the top 100, a significant rise from the 14.7% observed in December.
It’s (sort of) complicated. As I delved into it, I realized the core update began just a day after a significant spam update concluded, which made pinpointing the source of changes tricky. However, most disruption seemed to stem from the core update, with the spam update adding more chaos.
Diving deeper. Aleyda Solis’ analysis, using Sistrix data, revealed notable shifts from intermediary sites towards stronger, more authoritative sources. Sites that gained included:
– Official and institutional sites.
– Specialist and niche sources.
– Established brands.
– Dominant platforms.
On the flip side, aggregators, directories, and comparison sites saw declines.
Winners and losers. Solis pointed out interesting shifts: dictionary and language sites fell while major platforms rose; job aggregators lost visibility, whereas employer-specific sites like USAJobs gained.
Institutional sites saw fantastic gains on data-driven queries, with travel and real estate platforms shifting toward primary destinations. Health results were reordered with more emphasis on clinical and specialist sources.
Interestingly, YouTube experienced the most substantial visibility drop in this dataset.
Why it matters. From what I gathered, Google’s March update seems to have raised the ranking bar significantly. Strong brands and data-rich sources fared well, while intermediary sites are now more vulnerable.
I recently learned that Google’s first core update of 2026 has finally wrapped up after a 12-day rollout. Now, it’s time to understand its impact and refine our content strategies accordingly.
Google confirmed the conclusion of this update at 06:12 PDT through their Search Status Dashboard. The changes began on March 27, affecting search rankings globally.
Google described this as “a regular update designed to better surface relevant and satisfying content for searchers from all types of sites.”
Initially, Google estimated that the update would take up to two weeks, starting on March 27 and concluding on April 8, lasting exactly 12 days and 4 hours.
This update was the first of the year following the March 2026 spam update and the February 2026 Discover update. Core updates generally result in noticeable changes in search results due to broad alterations to Google’s ranking systems.
If you’ve been affected by these changes, it’s important to remember Google’s standing advice: drops in rankings are not necessarily indicative of issues with your site.
Recovery is often tied to future updates rather than immediate fixes. Try to focus on creating helpful, reliable, and people-first content.
With the rollout complete, I can now evaluate its impact with greater confidence. It’s time to analyze changes in rankings and traffic, pinpoint key changes, and adjust our content to align with what this update favors.
Here’s a brief timeline of recent core updates for reference:
I’ve been contemplating how even when content ranks well on search engines, it can still falter when it comes to AI retrieval. These AI systems assess pages very differently, based not just on their rank, but also on how information is extracted, embedded, and structured.
There’s an intriguing disconnect between traditional ranking and being successfully parsed by AI. A webpage can comply with excellent SEO guidelines and still miss the mark with AI-generated responses and citations.
In many situations, content quality isn’t the issue. It’s about whether the information can be reliably extracted after being segmented and embedded by AI systems.
This challenge is becoming increasingly common as search engines view pages as complete entities, but AI systems dive into the raw HTML to extract meaning from fragments rather than entire pages.
Crucial insights can get lost if they’re not appropriately structured or if they rely too heavily on visual rendering or inference.
This leads to a divergence between what’s visible in search and what’s accessible via AI, where content might exist in an index but lacks substantial meaning for AI retrieval.
The visibility gap is something I’ve been grappling with: Understanding the difference between ranking versus retrieval is key.
As search winds its processes around rankings, AI systems engage with fragments operated within a different representation of similar information. It’s here the visibility gap takes shape.
A page might rank high, but if its embedded content is incomplete or poorly organized, then the AI retrieval process becomes unreliable.
Treat retrieval as an entirely unique visibility factor. It doesn’t override SEO, but increasingly defines whether content can be effectively surfaced, summarized, or cited when AI filters come into play.
Another structural issue arises when content never even becomes accessible to AI. Many AI crawlers only parse raw HTML without executing JavaScript or client-side rendering. This creates blind spots, especially for JavaScript-heavy sites where the core content may appear in Google’s index but remains invisible to AI.
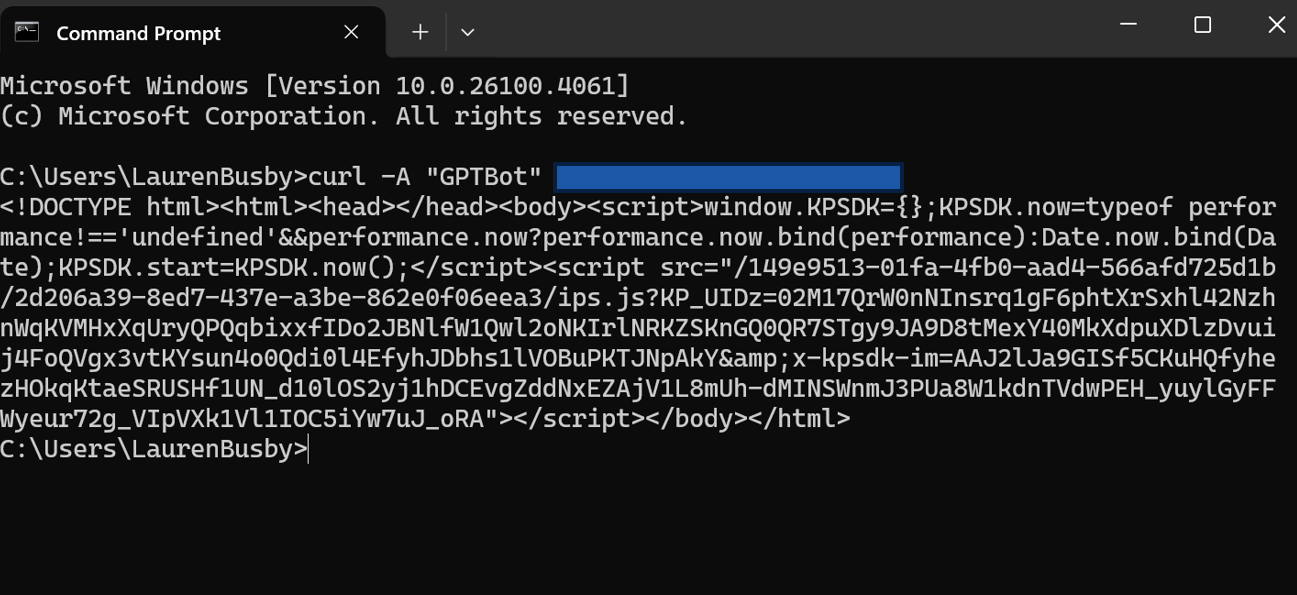
Testing if your content appears in initial HTML is quite straightforward. Simply inspect the HTML response at fetch time rather than the version rendered in a browser.
Running requests with AI user agents like “GPTBot” reveals if your site returns blank HTML even if it appears fully populated to users, highlighting its absence in initial responses.
Tools like Screaming Frog can validate this at scale. Disabling JavaScript rendering can reveal what AI systems see—if your essential content only displays with JavaScript, it can be indexed by Google’s search but not by AI retrieval systems.
Keep in mind that even with content returned, excessive code and scripts can hinder extraction by AI systems. Cleaner HTML results in more reliable embeddings, enhancing AI visibility.
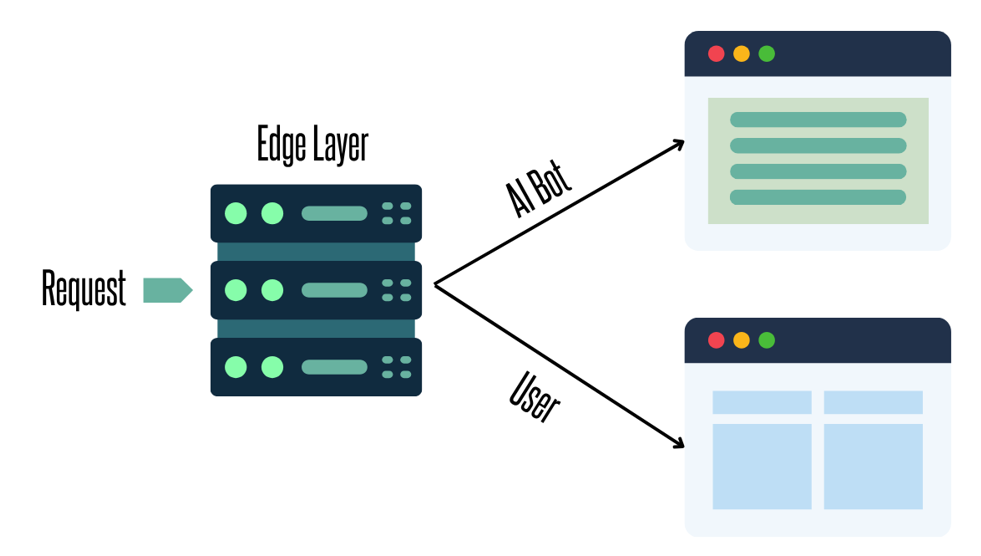
To tackle this, deliver fully rendered HTML when AI systems fetch your content. Pre-rendering can often fix these retrieval issues, ensuring content is present in initial responses.
Delivery can be managed effectively at the edge layer, providing AI crawlers with complete pages instantly. Human users receive a dynamic version while AI sees what it needs to extract meaning.
If pre-rendering isn’t viable, focus on ensuring primary content is accessible in a clean initial HTML response, even without script execution.
Columns laden with excessive markup can interfere with proper extraction, diminishing the content’s value.
The next structural failure to consider is when content is optimized for keywords rather than the entities AI seeks. Traditional SEO applies keyword relevance, but AI retrieves based on entity relationships.
Without clear definition, entity signals can weaken, causing pages to underperform in retrieval even if they rank well for queries.
AI evaluates sections independently once extracted, making the consistency of header tags essential to maintaining coherence.
Ensuring sections have a single, defined purpose allows for better embedding when isolated from larger context.
Finally, conflicting signals or metadata can dilute the semantics retrieved by AI, creating noise and ambiguity.
SEO doesn’t have to mean choosing between ranking and retrieval anymore. Both must be prioritized to succeed in today’s landscape.