
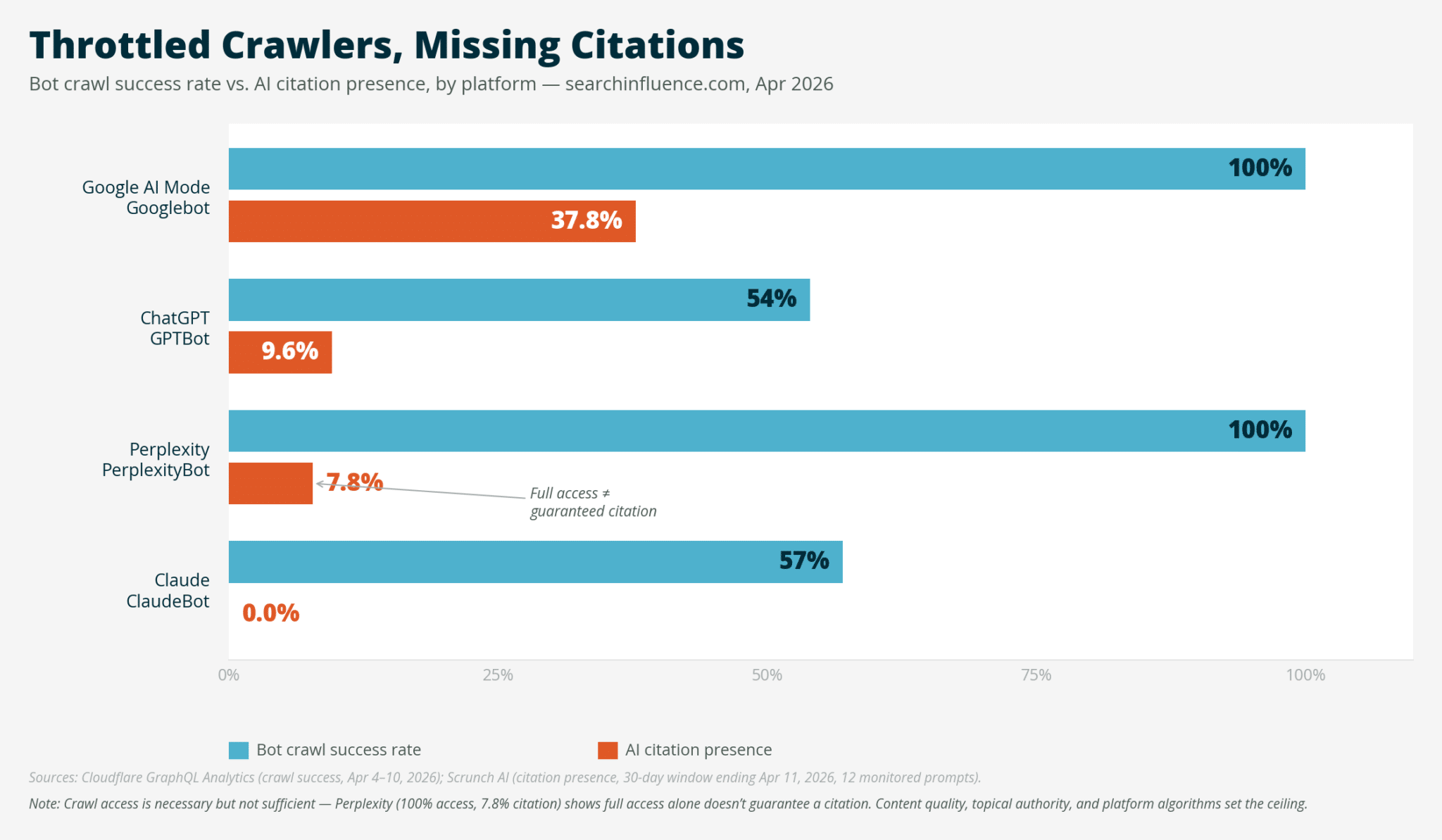
When I first looked at my SEO data, everything seemed perfectly fine. All metrics from Google Search Console, traffic, and indexing were normal without any red flags. But then, I decided to dig deeper using Scrunch, our AI citation monitoring tool, to examine the platform presence for searchinfluence.com over the past 30 days.
Here’s what I found: Google AI Mode showed a presence of 37.8%, Copilot at 22.2%, Google Gemini at 16.3%, ChatGPT at 9.6%, and Perplexity at 7.8%. Alarmingly, both Claude and Meta AI were at 0.0%.
Two platforms had zero presence. Given that every crawler reads the same site, differences in content quality or topical authority couldn’t explain this discrepancy. The only factor that varied was crawler access.

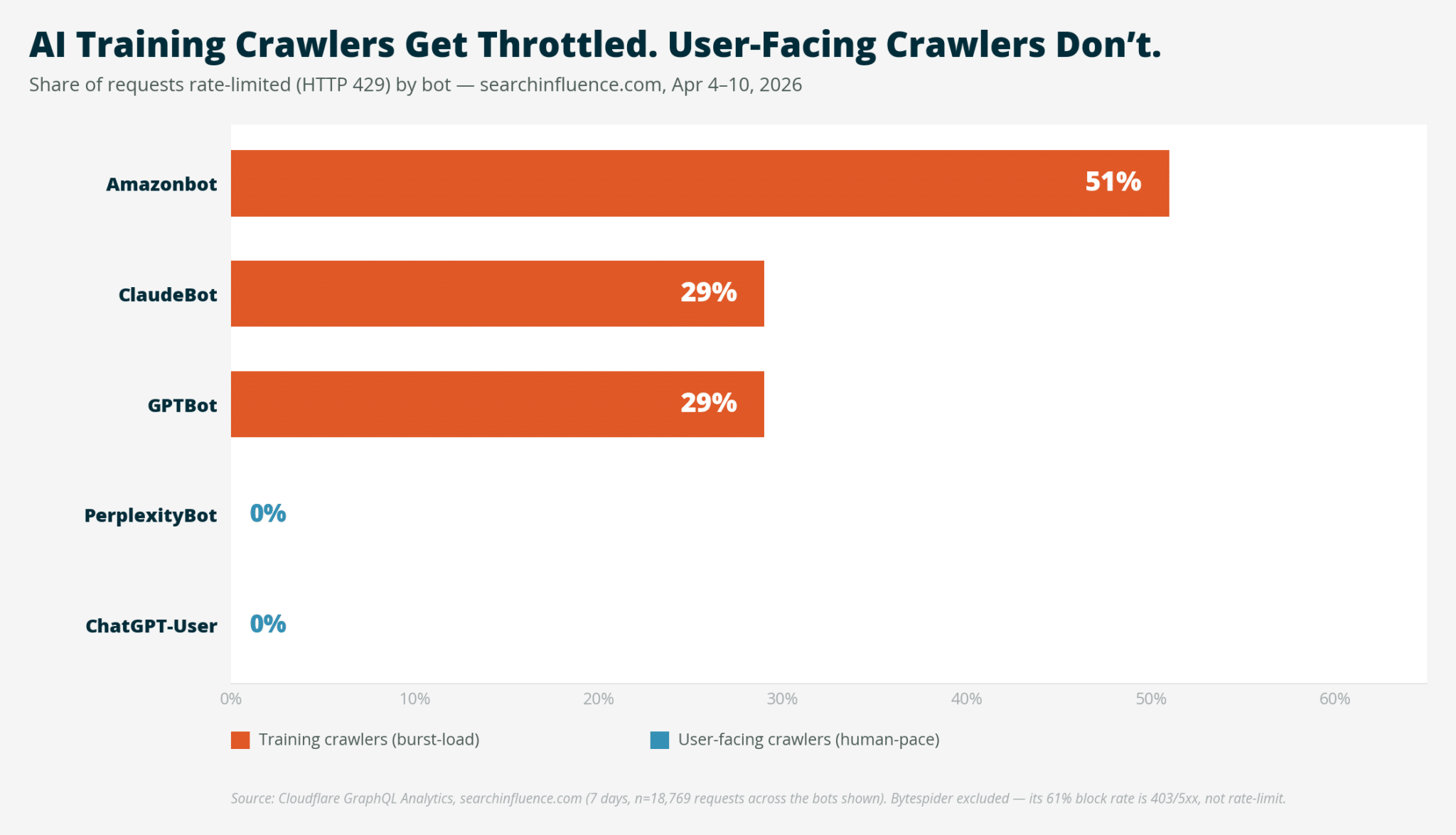
To understand this further, I analyzed seven days of Cloudflare logs and discovered 29,099 bot requests, with 65.8% involving AI bots. The requests rate-limited with HTTP 429, or “too many requests,” were interestingly varied by bot user-agent.
Training crawlers that make bulk requests are throttled, while user-facing crawlers that mimic human pacing during live queries aren’t. For example, ClaudeBot made 20,583 crawl requests for each referral returned.

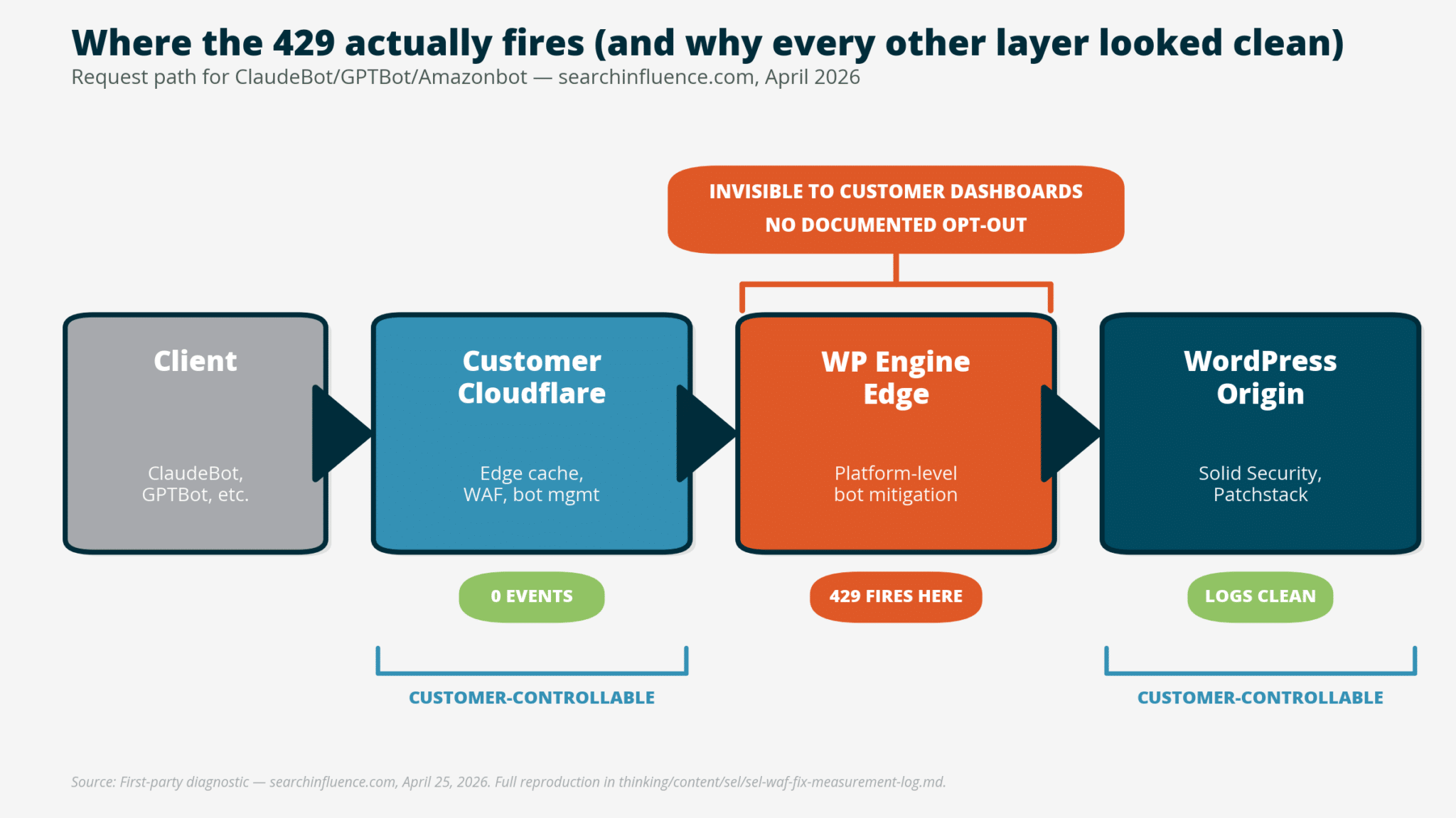
My assumption was that the 429 errors originated from Cloudflare, perhaps due to a web application firewall (WAF) or security plugin interference. I went down a rabbit hole investigating multiple layers. It was time-consuming and ultimately unnecessary.
The truth emerged when I performed a reproduction test using curl requests, revealing that the block was based on user-agent, not path or rate. The realization hit when I discovered the x-powered-by header: WP Engine hosted our site, and the block came from their platform infrastructure.
I then tested other AI bot UAs and crafted a fingerprint for each, discovering that the blocklist was outdated. While some bots were blocked, others like Common Crawl passed through unaffected.
In conclusion, while WP Engine’s firewall, documented on their support page, was intended as a security measure, it wasn’t transparent to customers. Identifying these blocks requires specific diagnostic steps, and the process taught me much about managed hosting’s hidden layers.
Inspired by this post on Search Engine Land.

Leave a Reply