
I recently discovered that Google Ads now includes an auto-apply setting for its experiments feature, which is activated by default. This means that once an experiment determines a winning variant, it can automatically implement that change without waiting for manual review. A real time-saver, but there’s more to consider.
Here’s how it works: as advertisers, we can select between two modes when evaluating results – directional outcomes or statistical significance with varying confidence levels of 80%, 85%, or 95%. However, it’s reassuring to know there’s a safety net; if any chosen success metric performs significantly worse during testing, the system won’t proceed with automatic changes.
Why it matters to me. Experiments are incredibly powerful within a Google Ads account, allowing us to test ideas without risking the existing campaign’s performance. While automating the application of results could streamline testing phases, this process eliminates a crucial checkpoint where we often catch unintended outcomes that might impact active campaigns.
The potential pitfall. One limitation is that experiments currently accommodate only two success metrics. This might mean that a third, important metric could suffer unnoticed if it’s not one of the chosen ones, as the system’s guardrails only protect what we’ve explicitly instructed Google to watch, not every significant factor.
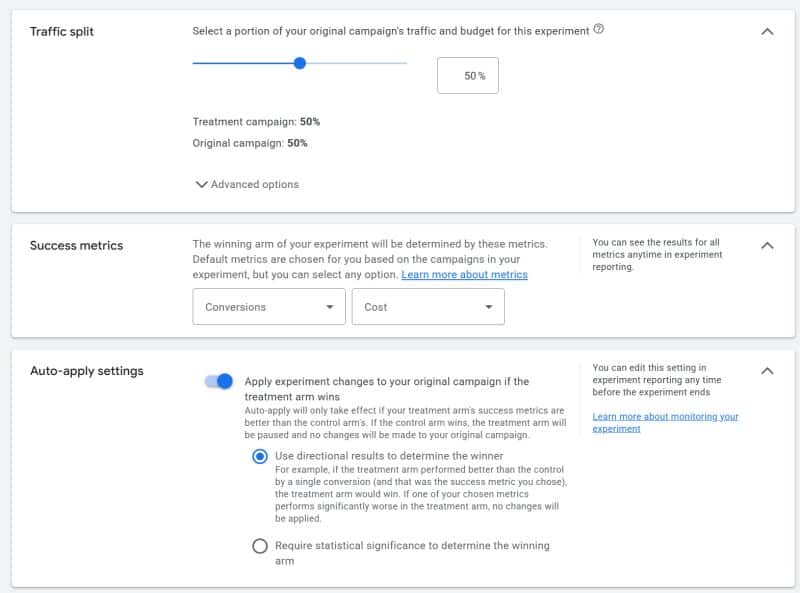
The takeaway. While the auto-apply feature serves as a helpful shortcut for straightforward tests, when conducting significant experiments, it’s worth going the extra mile for manual review. It’s best to let the experiment play out fully, ensure accuracy and thoroughness, and examine all data before making a final call.
First observed by professionals. This update did not go unnoticed; it was first picked up by Google Ads specialist Bob Meijer, who shared his insights on LinkedIn.
Inspired by this post on Search Engine Land.

Leave a Reply