I recently delved into a fascinating study on Google Discover headline formats, looking at a staggering 3.4 million articles. The results were eye-opening and showed that a simple headline rewrite often doesn’t yield the expected lift.
You might have come across these bold statements before:
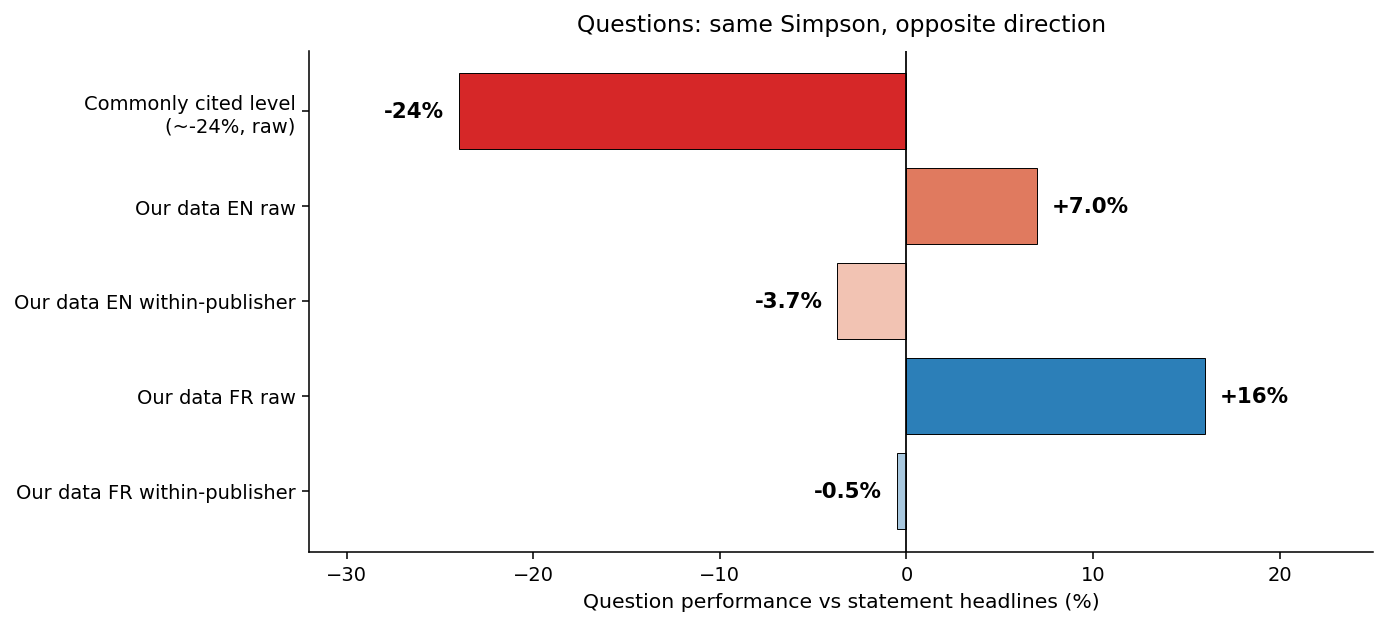
- Quote-led headlines outperform plain declarative ones by nearly 29%.
- Question headlines underperform both, sometimes by 24%.
- Format drives the result: Rewrite a statement as a quote, or add that magic word, and you should expect a real lift.
To put these claims to the test, I examined 1,674,518 English articles and 1,690,295 French articles from the 1492.vision Discover corpus. That’s quite a hefty sample size!
What I found was a deeper flaw than just numbers. It turns out that all three claims treat headline format as a leverage point for visibility. However, the data clearly shows that the impact of a headline’s format mainly reflects the publisher’s audience and the specific Discover surface used.
One striking analysis was Simpson’s paradox. An anomaly that, once noticed, appeared across the entire dataset.
Here’s what we’re really measuring:
Rather than clicks from Discover, our metric is hits per article: how often an article appears across the 1492.vision fleet. This serves as a proxy for visibility.
The dataset was limited to editorial articles, excluding platforms like YouTube because they have different headline norms. We’ll dive back into these at the end, as they bring more clarity than anything else.
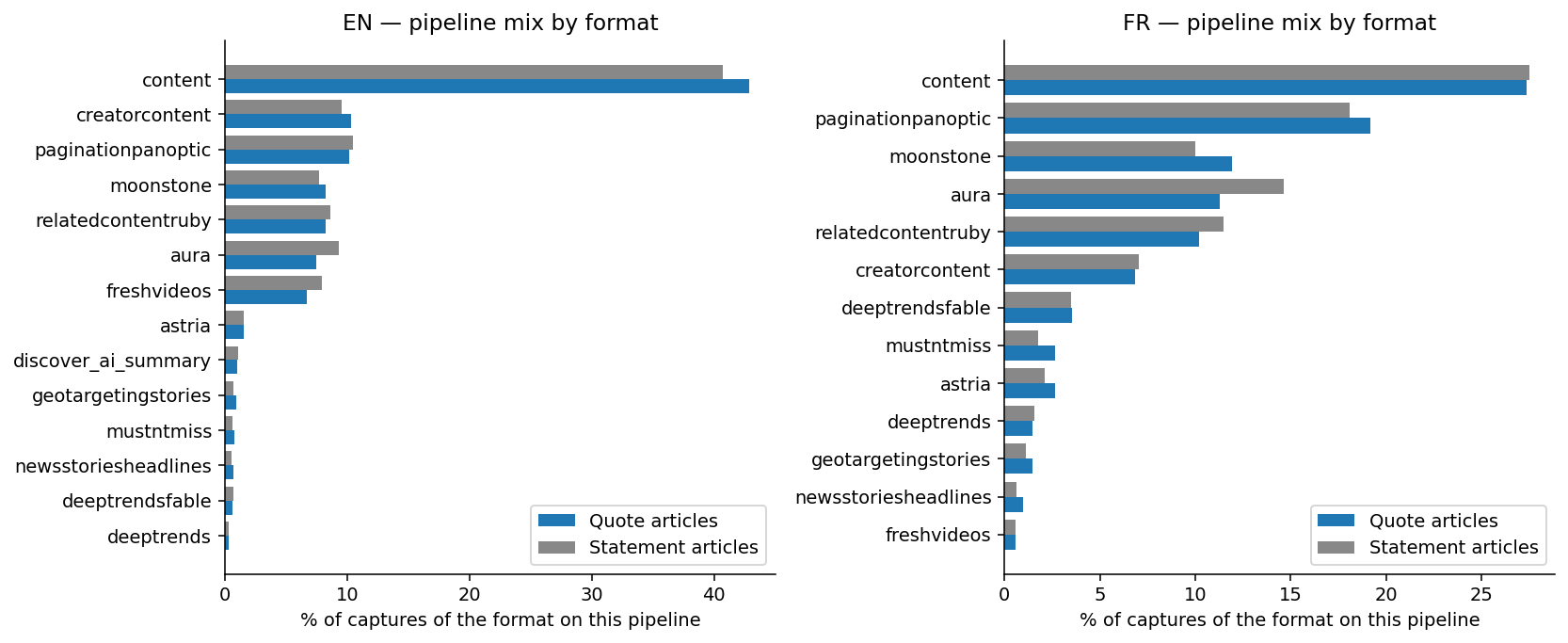
Why is volume important? The crux of the argument depends on slicing this vast dataset by publisher, Discover surface, topic, and language while still keeping enough data in each segment for valid insights. This is where the real difference between numbers and insights, and between a genuine format effect and a statistical illusion, lies.

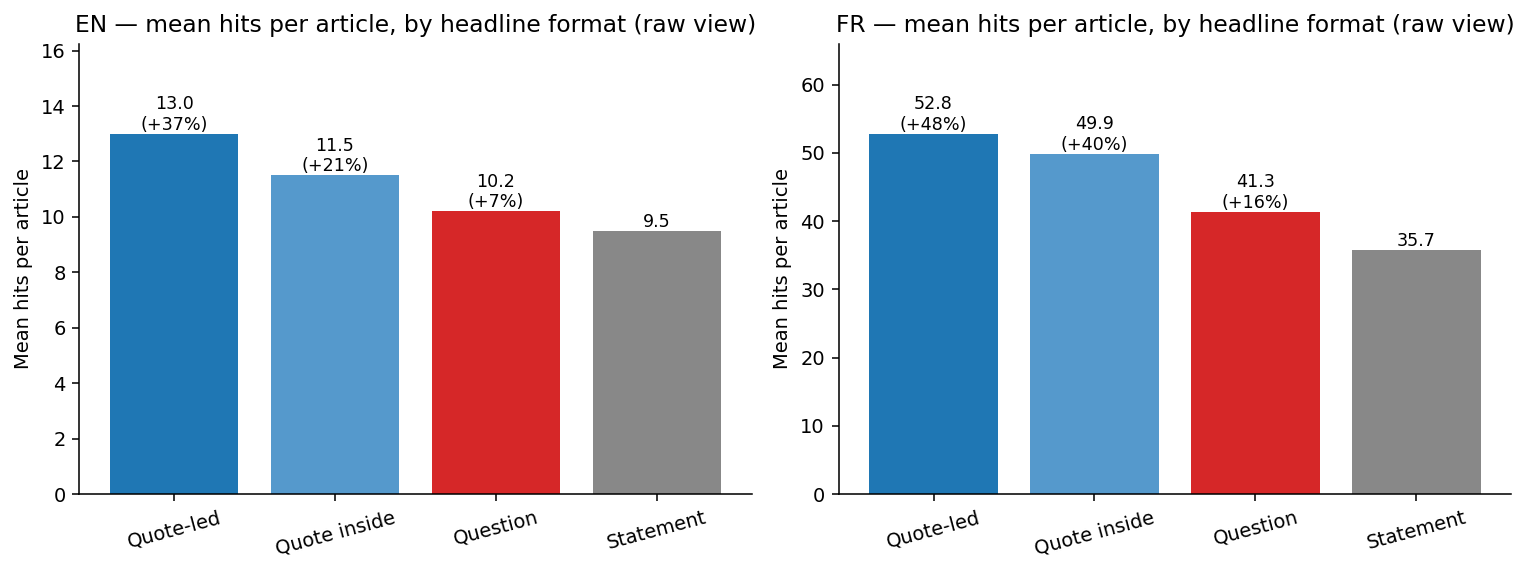
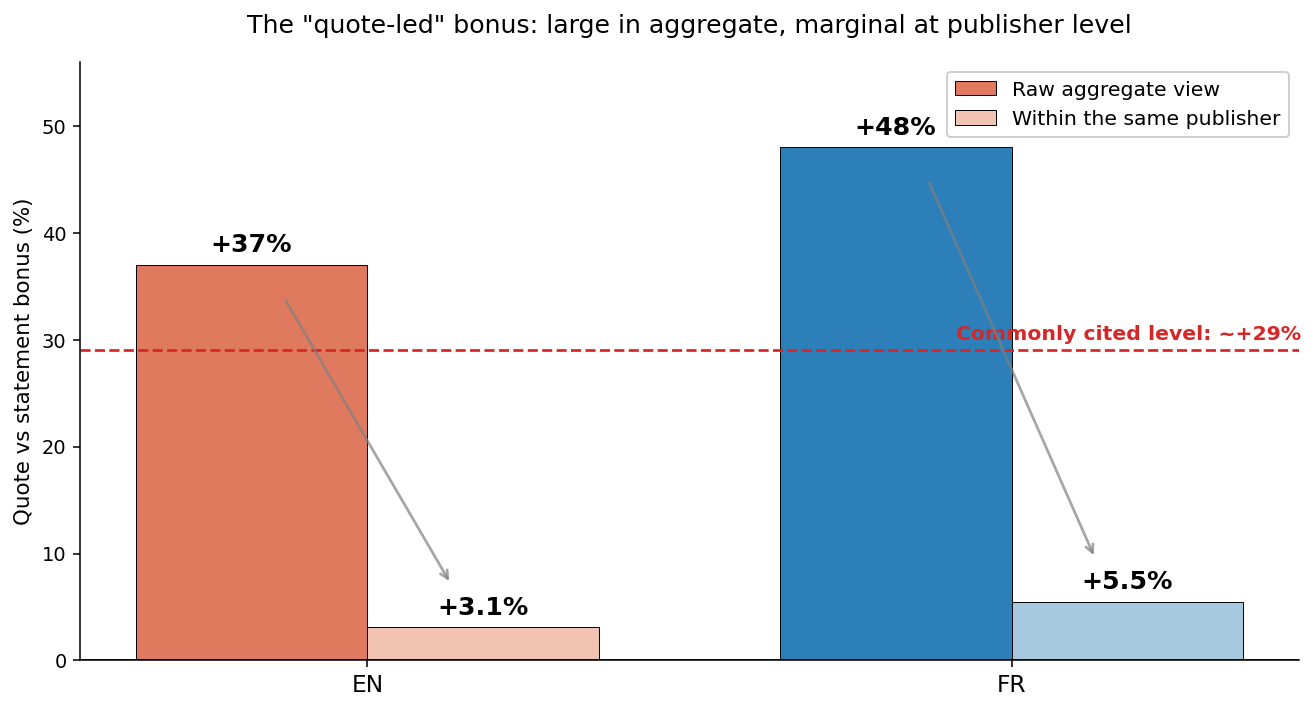
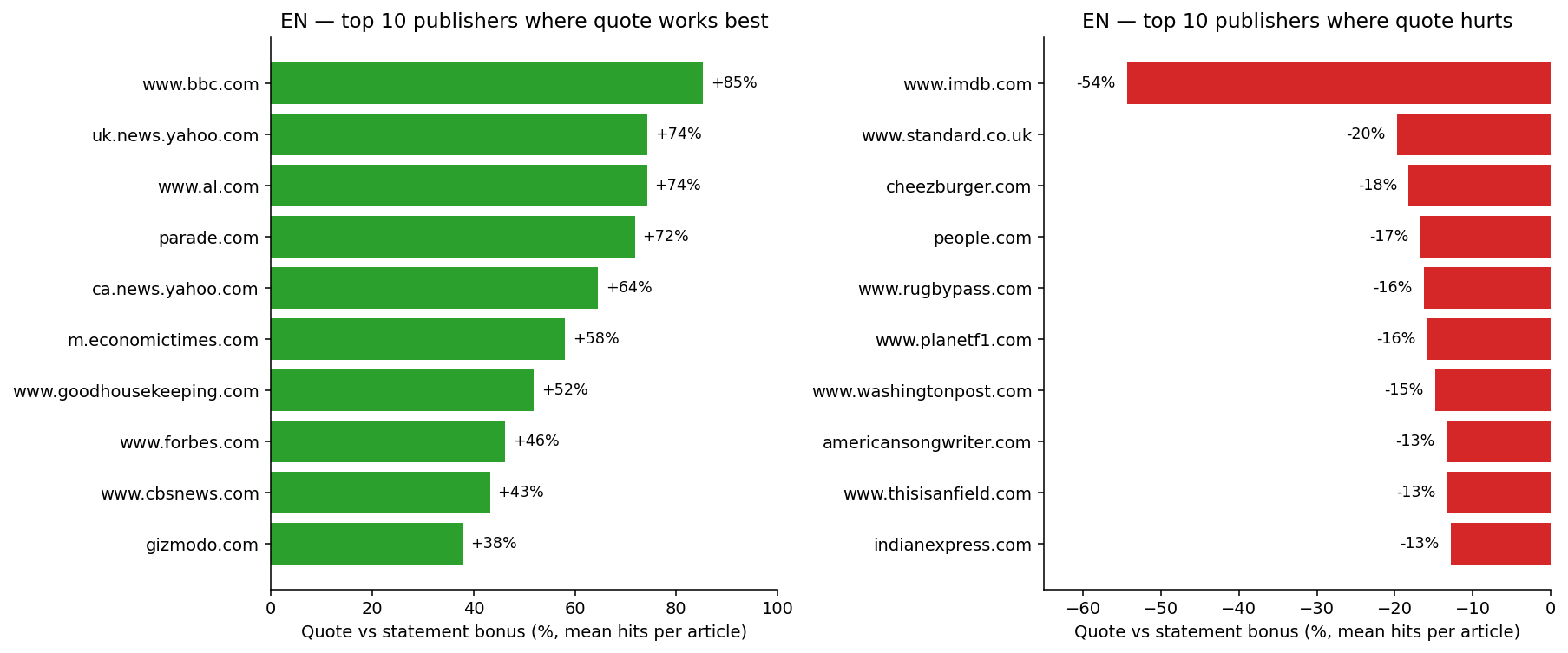
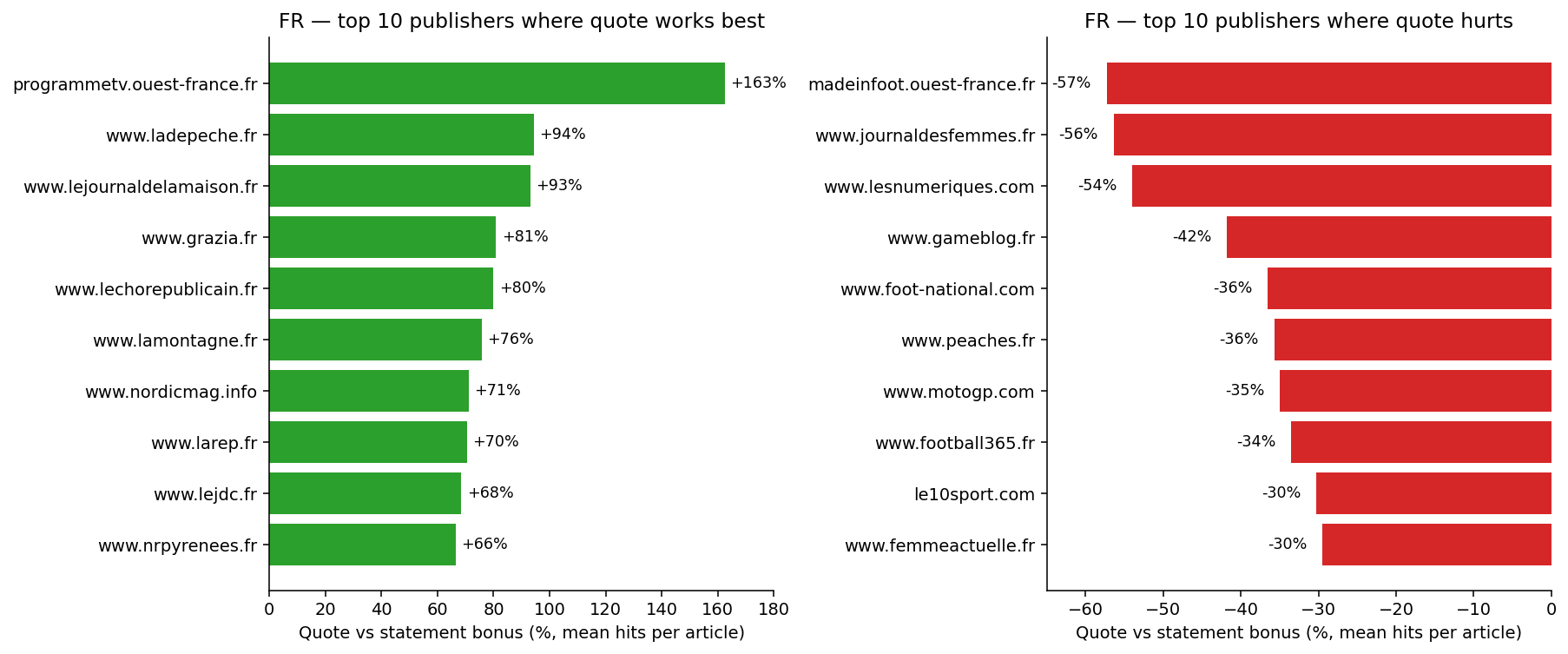
Here’s a sneak peek: when you pool all publishers together, a clear gradient appears with quote-led headlines leading the pack and statements trailing.
The frequently cited +29% is actually a conservative estimate for editorial pieces: quote-led headlines achieve a +37% lift in English and +48% in French. Even questions don’t lag behind as much as expected since they outperform statements to some extent (+7% EN, +16% FR).
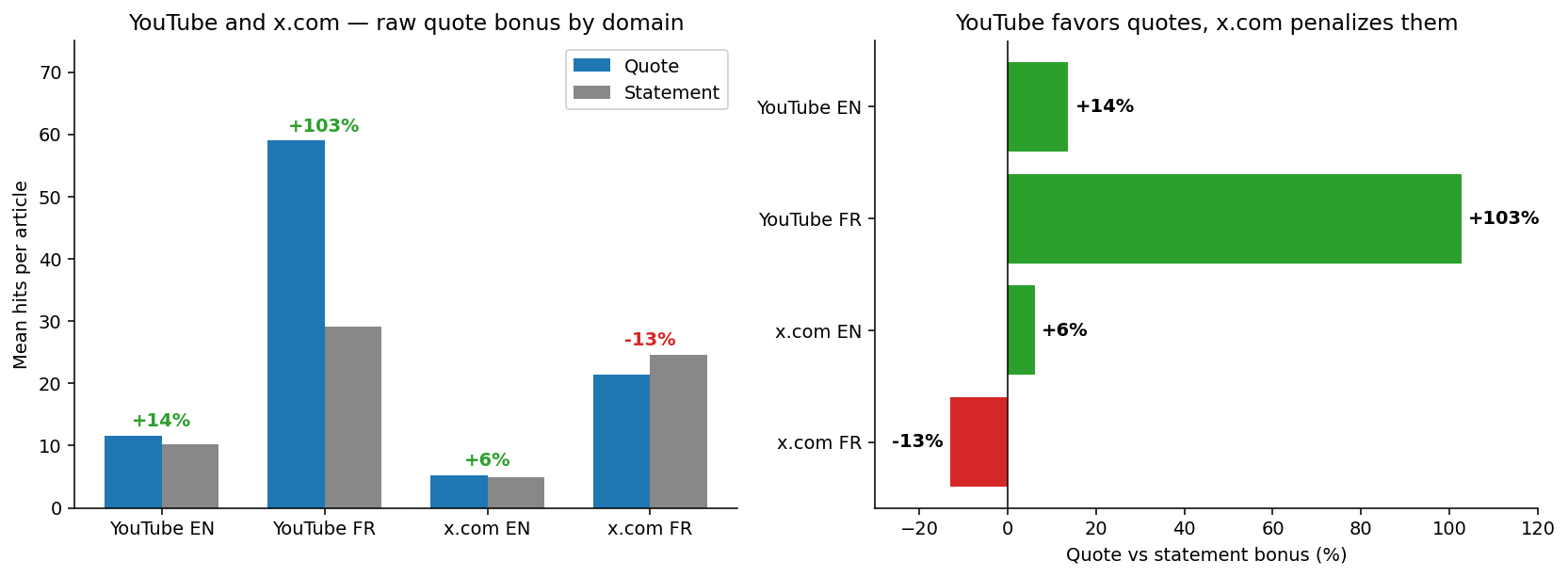
Though claim 1 appears understated and claim 2 misguided at the aggregate level, these are the observations on which most headline advice leans. Let’s delve further to understand what the data is really revealing.
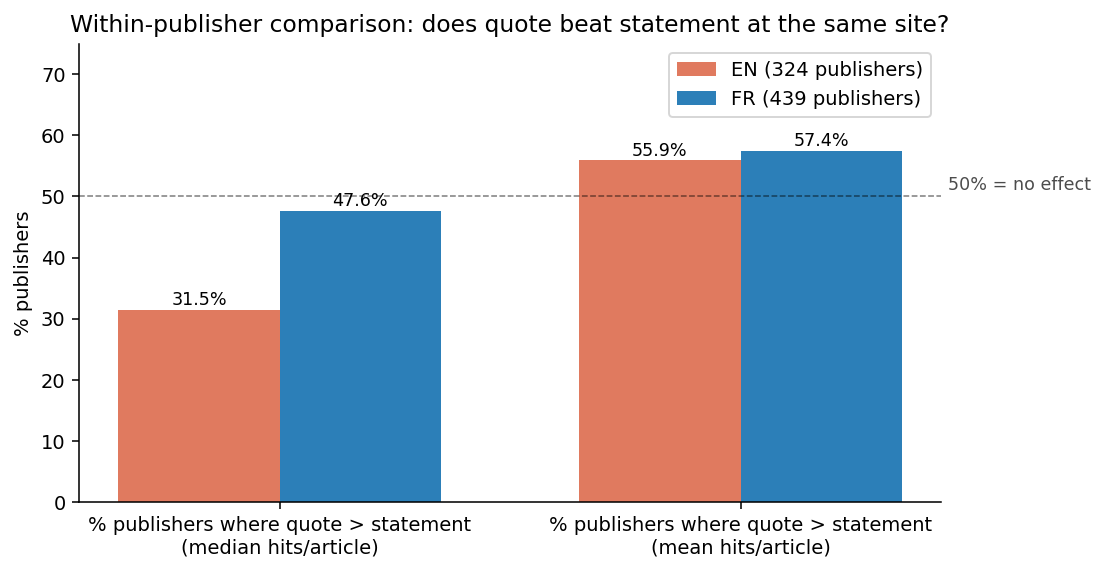
Let’s shift to the hidden aspects, starting with publishers. The raw comparison isn’t effectively between quotes and statements. It’s more about one set of publishers versus another because the publishers employing quotes often differ from those who don’t.
Some media, like celebrity-focused outlets, regional newspapers, and sites attuned to trending topics, gravitate towards quotes, and naturally earn more Discover hits compared to entities that prefer factual presentations.
This is a prime example of Simpson’s paradox: a strong trend at the aggregate level that fades or reverses when segmented into groups.
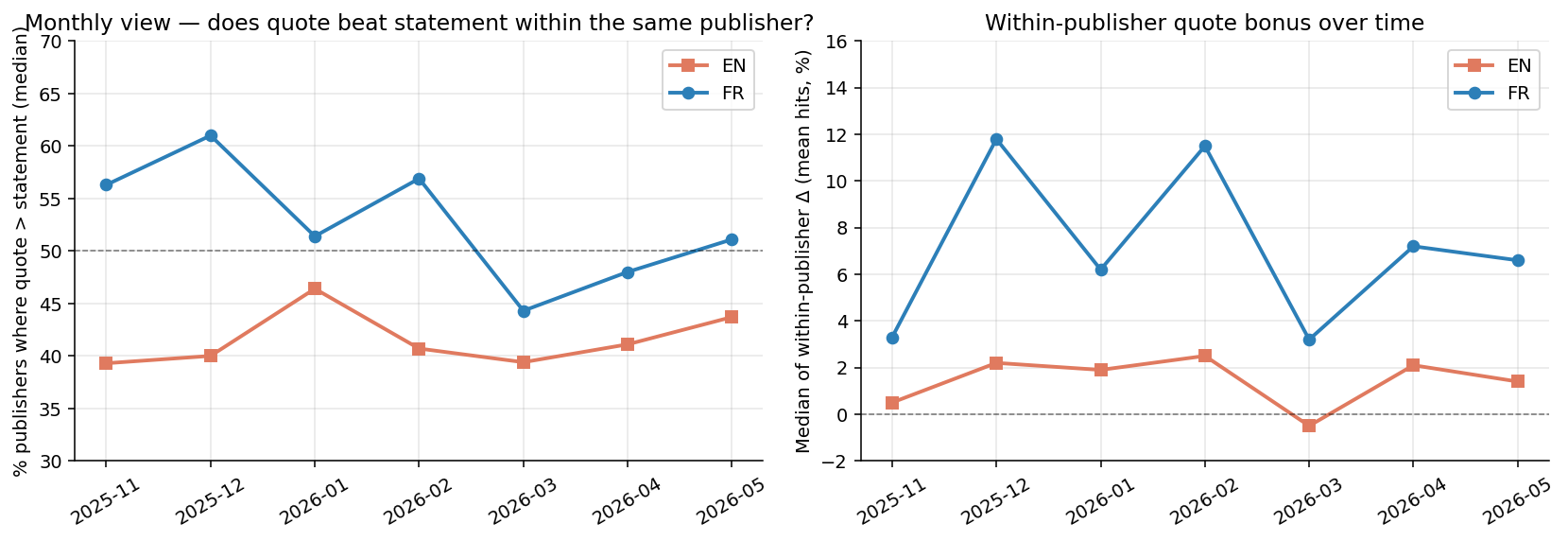
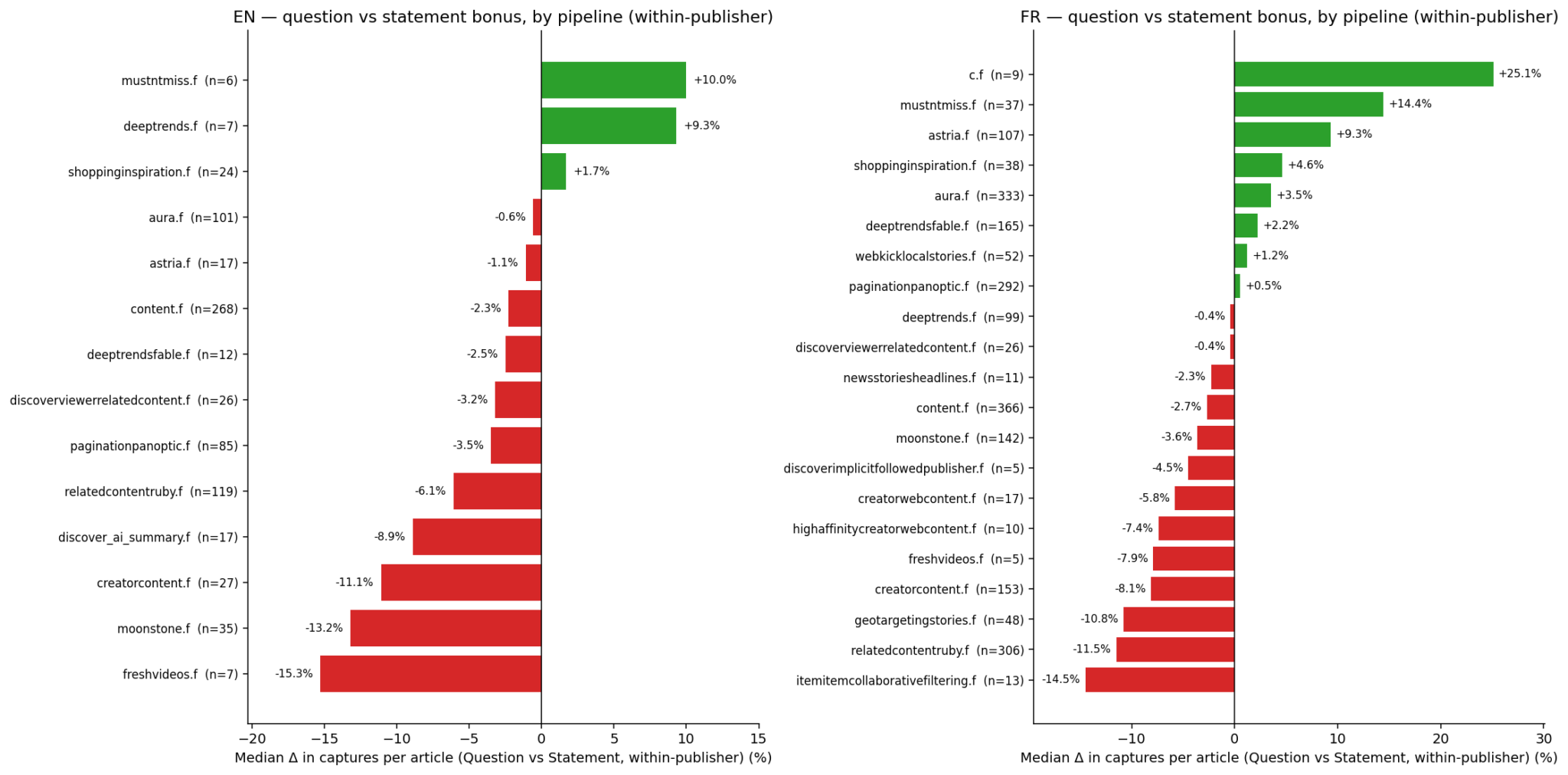
To focus on the format itself, publishers must each be their own baseline: comparing quotes with statements within the same publishing entities while controlling for audience and topic diversity.
So, the question is, how does each format fare on its own? Let me walk you through the rest of this journey as we unpack these layers.
Inspired by this post on Search Engine Land.