
Have you ever wondered how AI search platforms have evolved from simple Retrieval-Augmented Generation (RAG) to sophisticated agentic systems? These days, AI search has advanced beyond mere RAG, transforming into something far more complex and dynamic. In this article, I’ll guide you through how today’s advanced AI retrieval systems determine if your content is showcased or left in the shadows.
About two and a half years ago, I penned an article for Search Engine Land on how RAG represents the future of search. It wasn’t just a reactionary measure from Google in response to ChatGPT, but rather an architecture in development since the REALM paper in August 2020. Observing developments since then, everything has aligned with what I speculated.
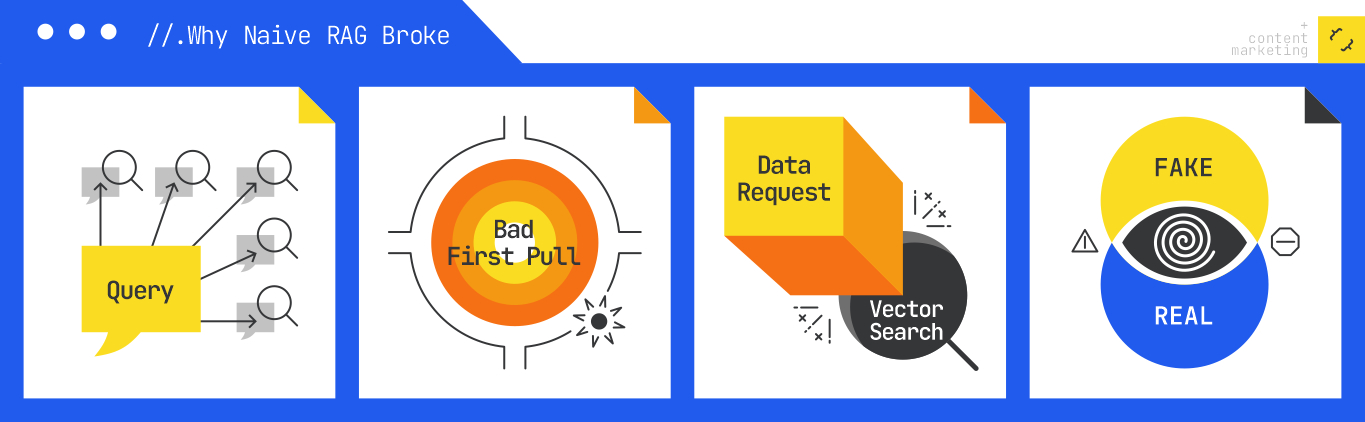
The RAG pipeline of the past, which I outlined as a query transforming to an answer with citations, is already outdated. Major AI search platforms like Google AI Mode and ChatGPT Search have transitioned to a more complex architecture. They now possess planning capabilities, tool-routing options, and iterative retrieval methods that continuously refine results until they reach a suitable conclusion. The one-retrieval-to-answer model is defunct.
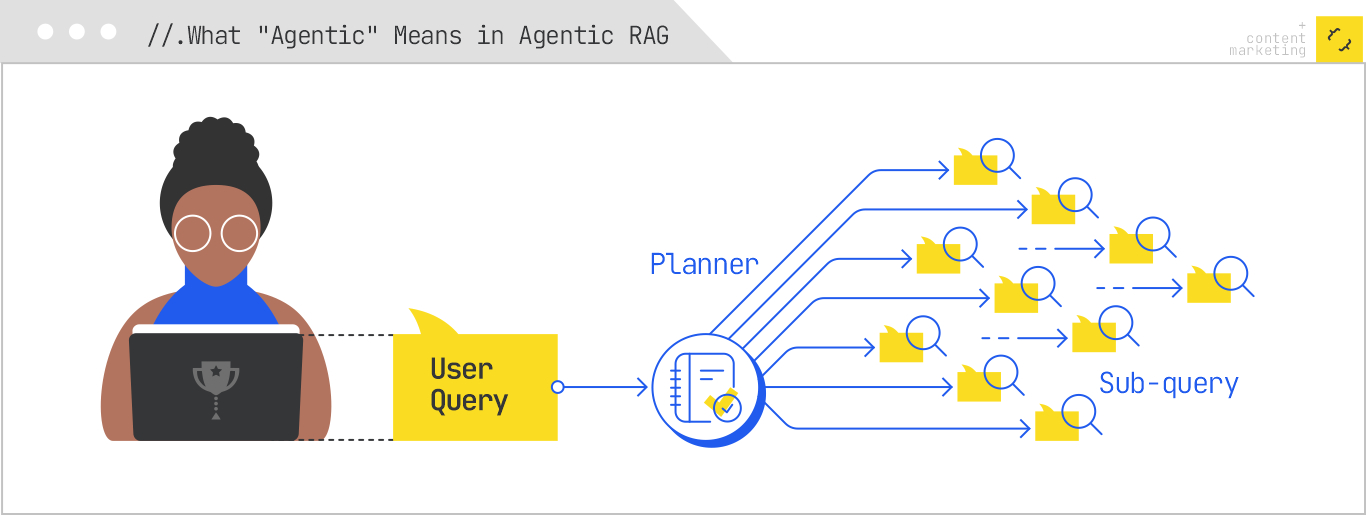
This sophisticated approach is what we now refer to as agentic RAG, a framework that’s become the industry standard. If your content strategy still relies on single-shot retrieval, you’re optimizing for a non-existent system. What’s more, in agentic RAG, you can’t witness the gatekeeping process—only the final outcome shows if your content made it.
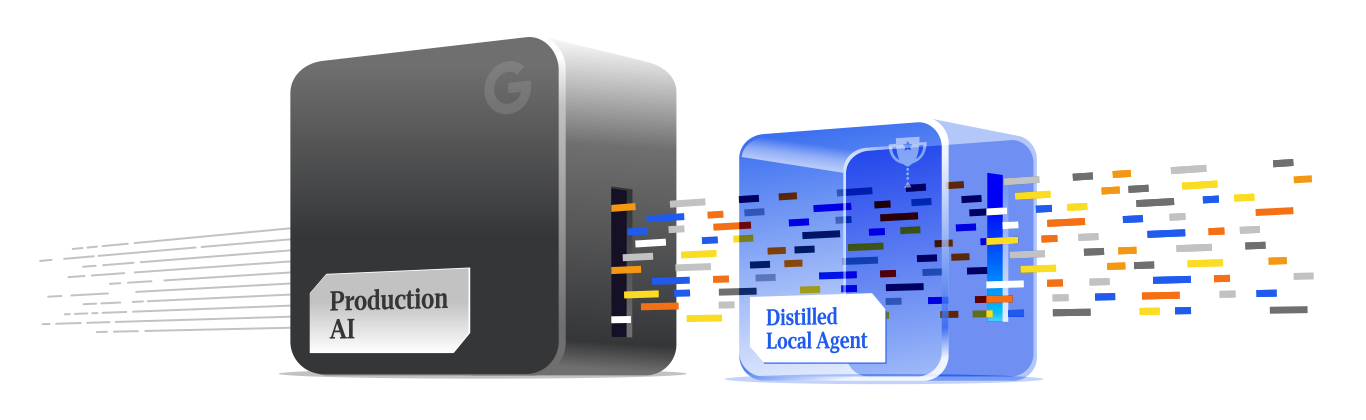
By the time you finish reading, you’ll have a functional understanding of agentic RAG, the patent evidence showing its application by companies like Google, insights into what each major platform is doing, and concrete tactics to enhance your content strategy. You’ll also gain my important takeaway of the year: the future hinges on model distillation.
The October 2023 perspective is still relevant. Passage-level retrieval remains essential to relevance, and knowledge graphs work in tandem with LLMs. Search systems aim to lower what are known as Delphic costs, minimizing the effort users expend to find answers. Google’s guiding principle has always seen traffic as a means rather than an end. This aspect of my argument needs no change.
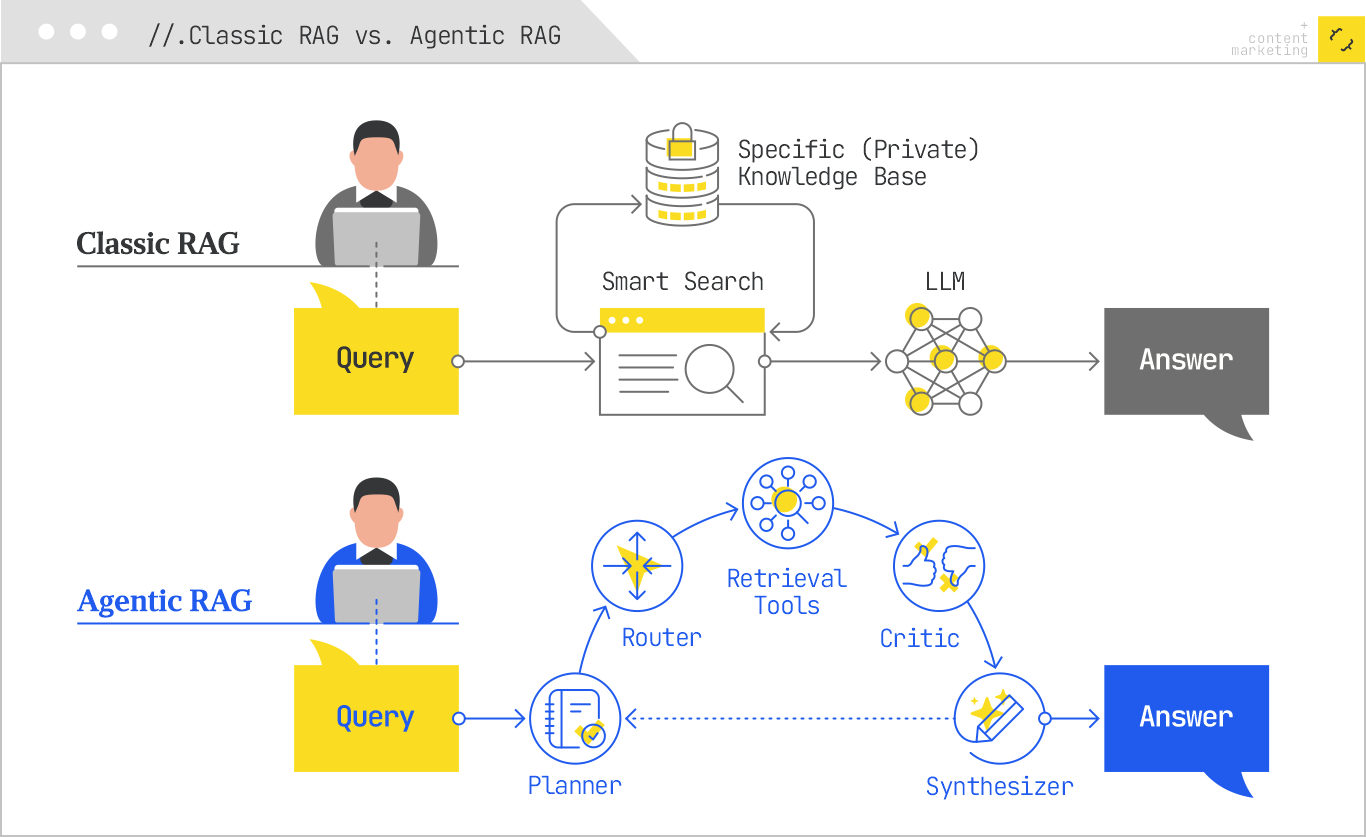
What has evolved is the structure of the retrieval pipeline. Back in 2023, RAG was straightforward and linear. A query was encoded, top passages were retrieved, and an answer was generated. If your content was within the top set of results, you had visibility; if not, you were invisible. This framework served its purpose at the time.
Today’s pipelines boast abilities absent from linear models: planning, tool usage, multi-hop iteration, and reflection. Rather than being a single occurrence, retrieval now involves up to twenty sub-retrievals orchestrated by a central agent, which refines its foundation of evidence continuously before finalizing an answer.
My earlier writing hinted at these upgrades without naming them precisely.
The word “agentic” is used liberally, but its structural definition is specific. Understanding agentic RAG requires grasping four properties each system must embody to wear the label.
1. Planning involves restructuring the user query into a research plan, breaking it down into sub-queries, pre-selecting tools, and strategizing retrieval sequences. The system doesn’t just respond; it plans each step with precision.
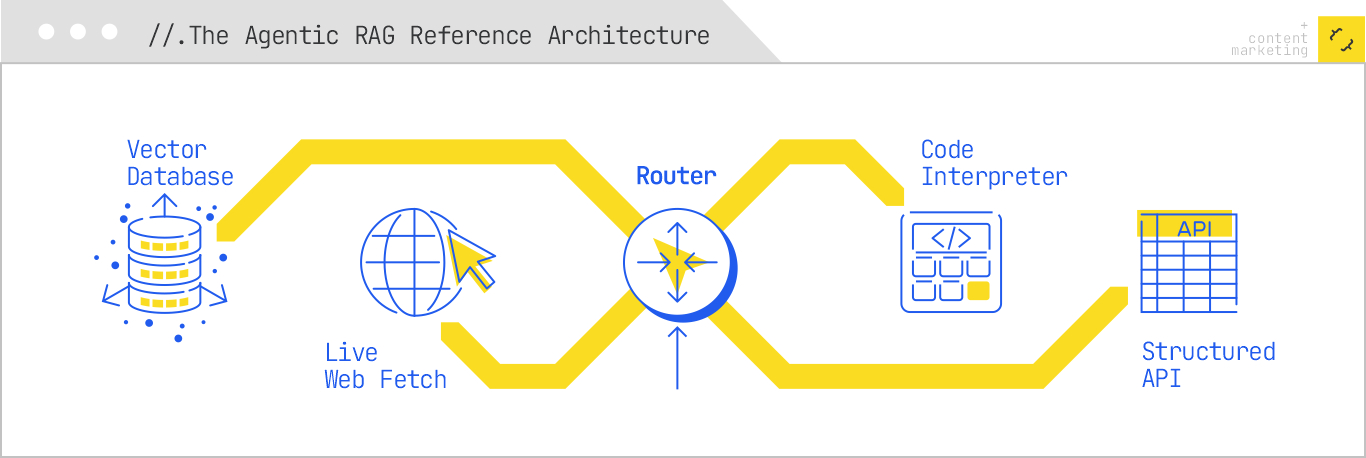
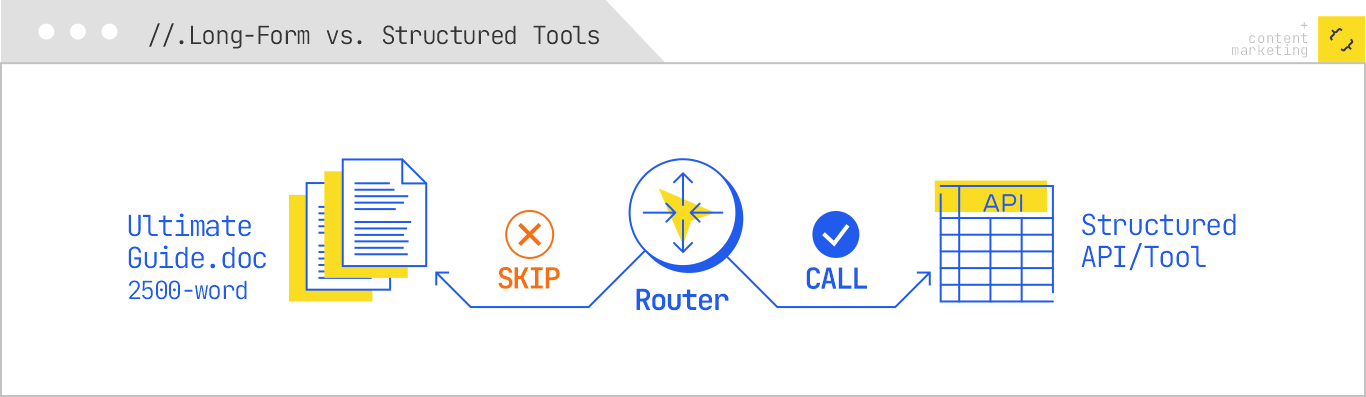
2. Tool usage extends beyond basic retrieval to include inquiries through APIs, code execution, live web browsing, and more. The agent selects the best method for each task, weaving these tools into cohesive outputs.
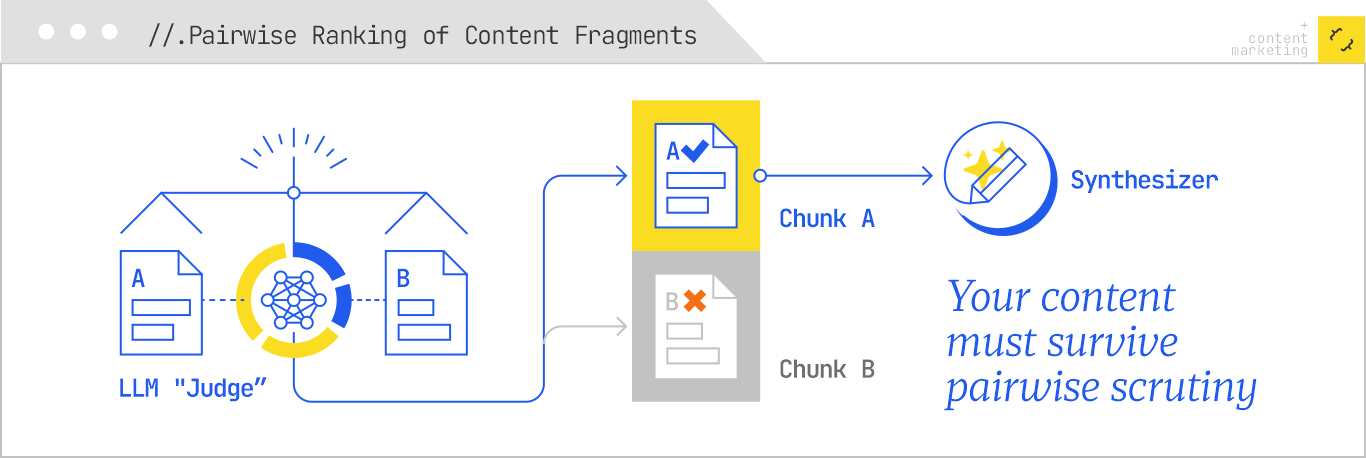
3. Iteration or multi-hop retrieval is where the agent refines its findings by visiting the source multiple times, continually improving the evidence base.
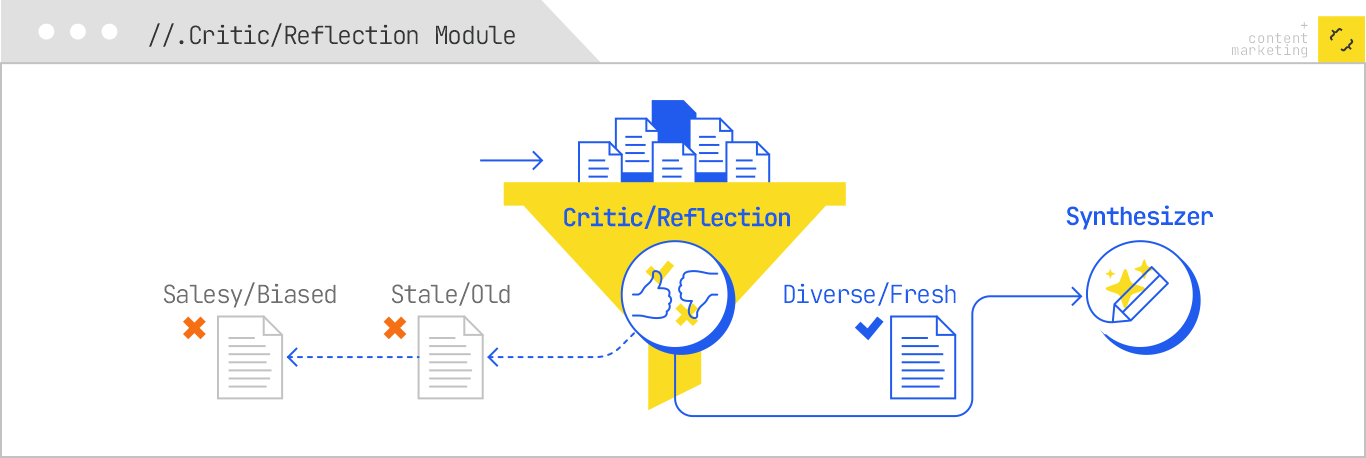
4. Reflection involves the agent critiquing its own output, determining its sufficiency and quality, and retrieving more information if needed to resolve discrepancies or improve source diversity.
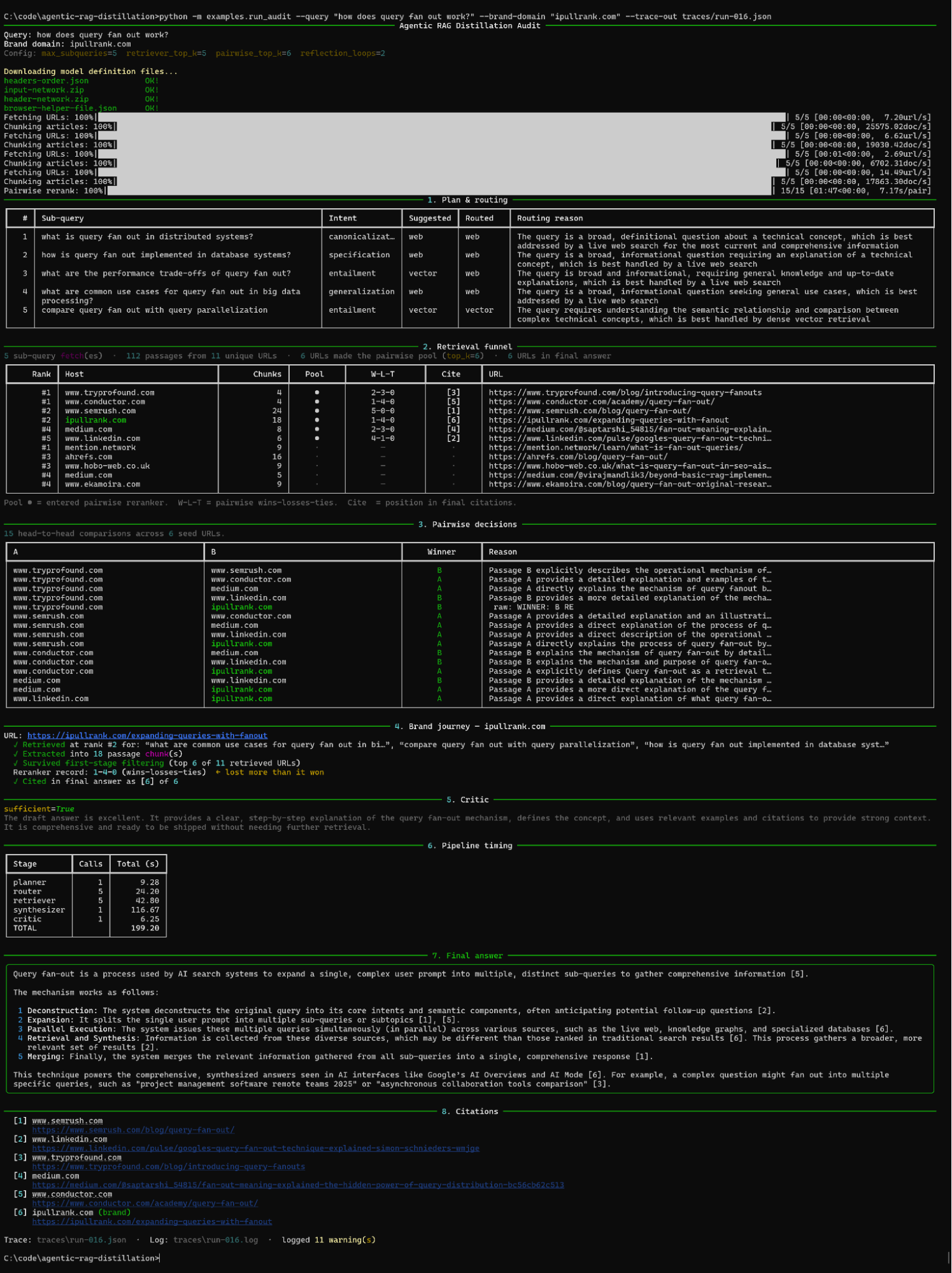
These are the qualities that set agentic RAG apart and what make it the new default for AI search platforms.

Drawing a contrast between the classic RAG and agentic RAG, imagine the former as a direct process and the latter as a comprehensive loop where steps can be revisited until the solution is optimal. This is what my content needs to withstand.
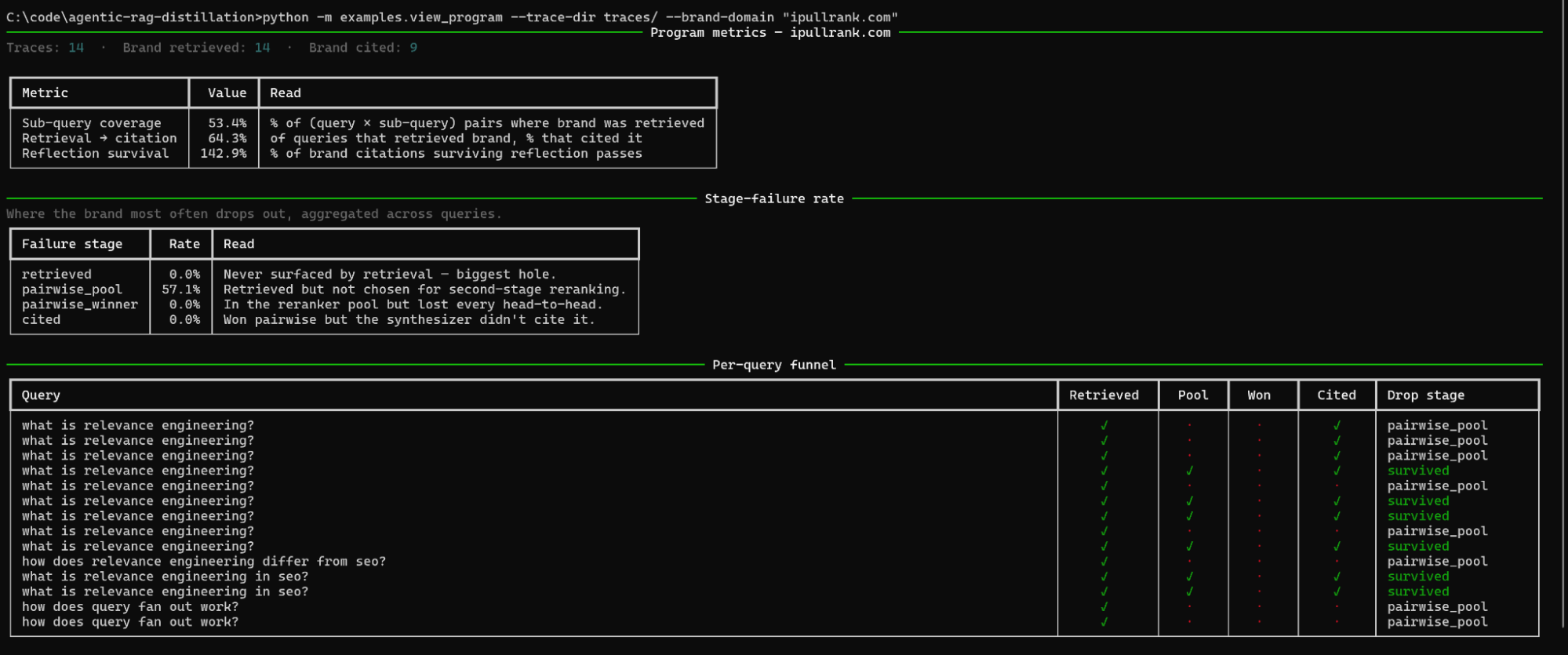
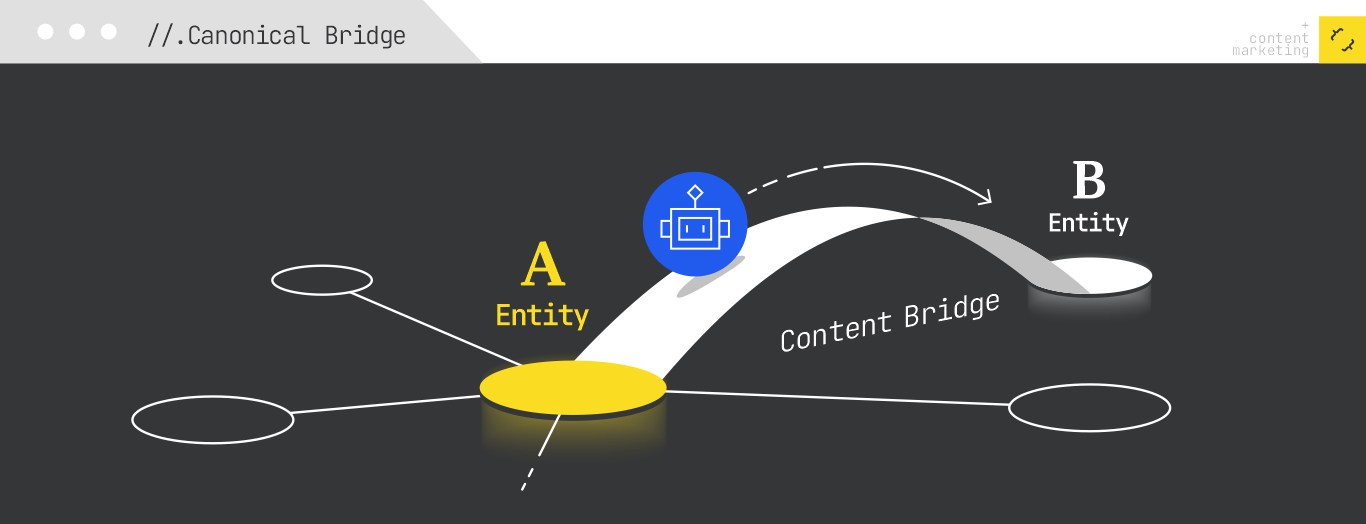
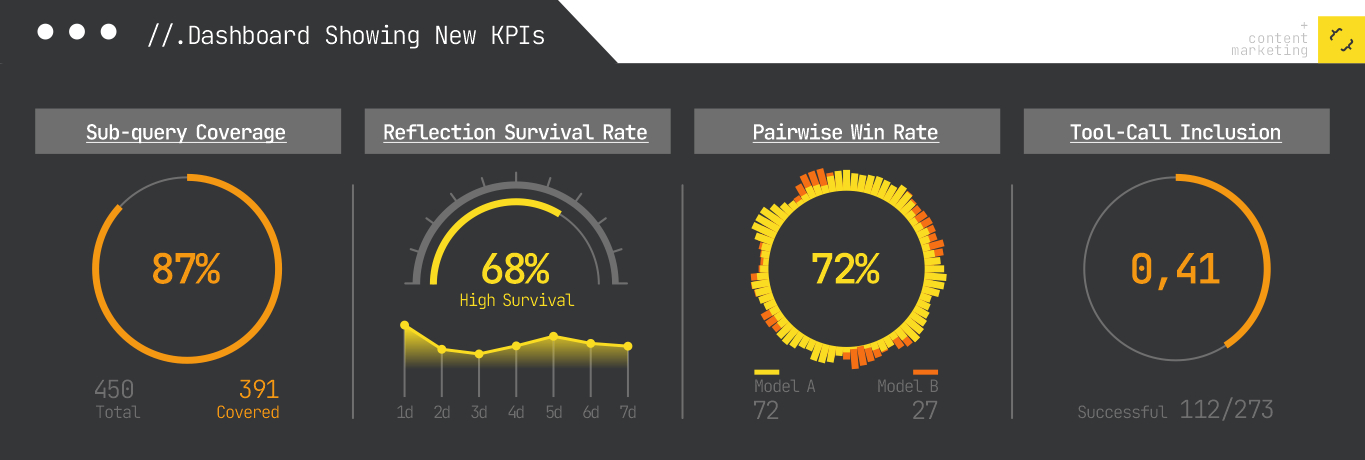
The six shifts required for effective content engineering in the realm of agentic RAG are clear. I need to optimize for a spectrum of sub-retrievals, present well-structured and cohesive passages, leverage bridge entities, offer tool-callable content, and ensure freshness within my content.

The path forward involves navigating measurement’s increasingly complex landscape with the aid of model distillation. By understanding the full lifecycle from internal query generation to external execution, I can effectively target content positioning and citation strategy.
Engaging with this agentic environment demands observation, adjustment, and perpetual calibration. The choice is simple: evolve to survive and thrive or remain static and risk obscurity.
Inspired by this post on Search Engine Land.

Leave a Reply