I’ve discovered that server logs hold a treasure trove of information for large websites, often uncovering technical SEO issues before they impact rankings. They offer insights into how search engines interact with our site, where we might be wasting crawl budget, server response times, and the accessibility of critical pages.
Unlike Google Search Console or third-party SEO tools, server logs capture every single request made by search engines to our infrastructure. It’s surprising how many organizations overlook analyzing them, thus missing out on valuable technical SEO data.
SEO teams often place their trust in tools like Google Search Console, Bing Webmaster Tools, and various third-party crawlers, which rely on data samples, delayed reporting, or simulated crawls. Server logs, however, document direct interactions between crawlers and our infrastructure, which is crucial for websites with a vast number of URLs.
Logs record every server request, and when used for SEO purposes, the most revealing entries come from search engine bots like Googlebot and Bingbot. These records create a detailed history of how our site gets crawled over time.
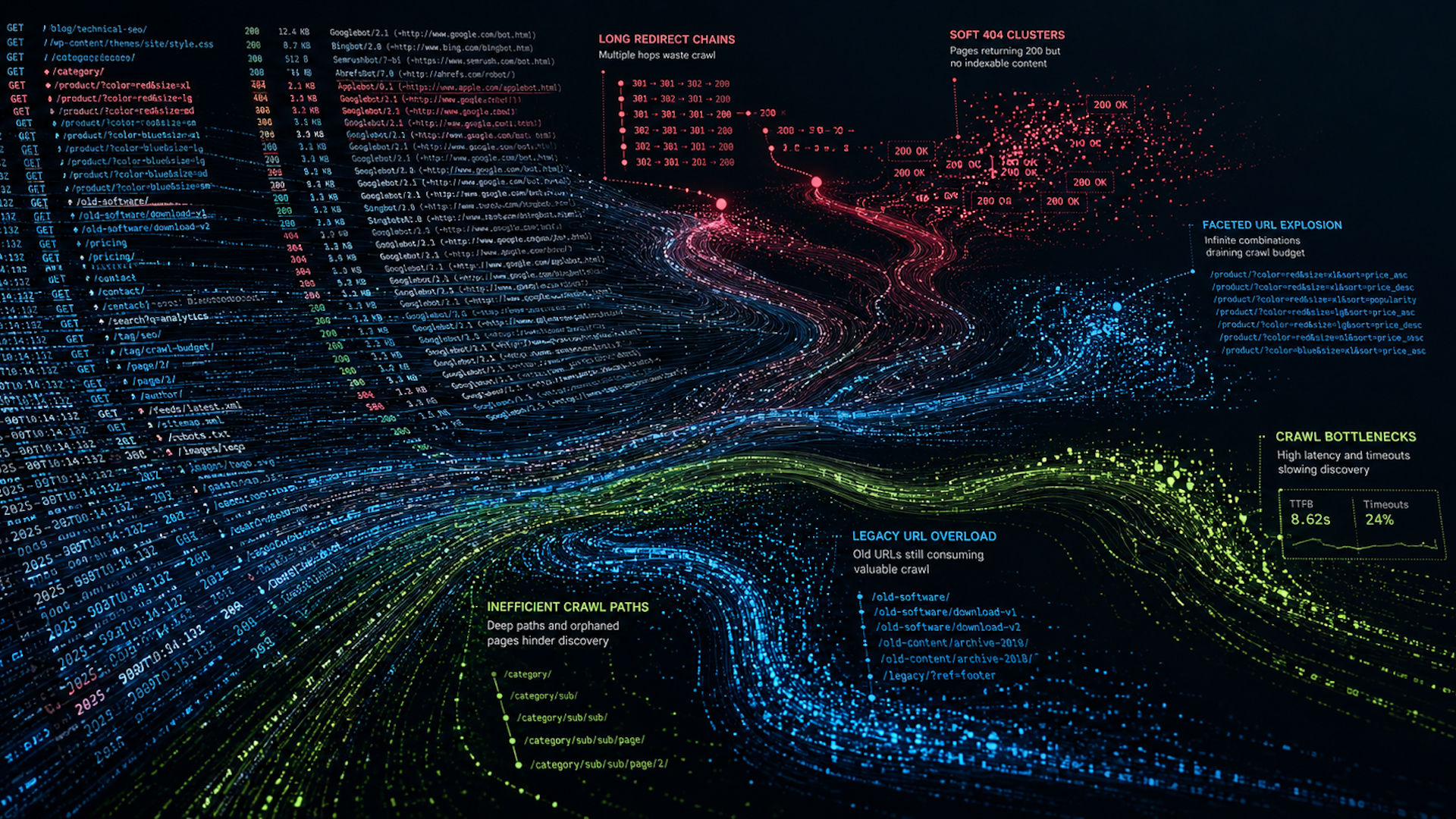
Most technical SEO problems start as crawl inefficiencies. I’ve seen scenarios where search engines request a page but receive unexpected responses, or they follow complex redirect chains, contributing to delays and inefficiencies.
Server logs clearly expose these inefficiencies. For instance, on large ecommerce platforms, logs might show that crawl resources are wasted on parameterized URLs, while important product pages are overlooked.
Retaining logs over time provides historical visibility into trends related to migrations, infrastructure changes, and platform redesigns. This ongoing visibility is something Google Search Console does not offer.

For instance, large sites often compete internally for crawl attention, and search engines don’t treat all pages equally. Logs can reveal if our valuable category pages are getting the right amount of attention or if outdated URL structures are still consuming resources.
Without these logs, many crawl inefficiencies might remain hidden. The crawl data in logs also assists us in understanding which sections of our site need optimization for better crawl efficiency and response timing, influencing SEO and even our infrastructure.
It’s amazing how log file analysis can differentiate between temporary issues and persistent infrastructure problems, helping us focus our efforts where it truly matters.
Having extensive log data enables us to monitor site migrations effectively, understanding crawler behavior pre- and post-deployment to ensure a smooth transition.
Operating without retaining server logs is like flying blind. Logs bridge the gap that many SEO tools cannot fill, providing a comprehensive view of crawler behavior and interactions with our web infrastructure.
Inspired by this post on Search Engine Land.

Leave a Reply