
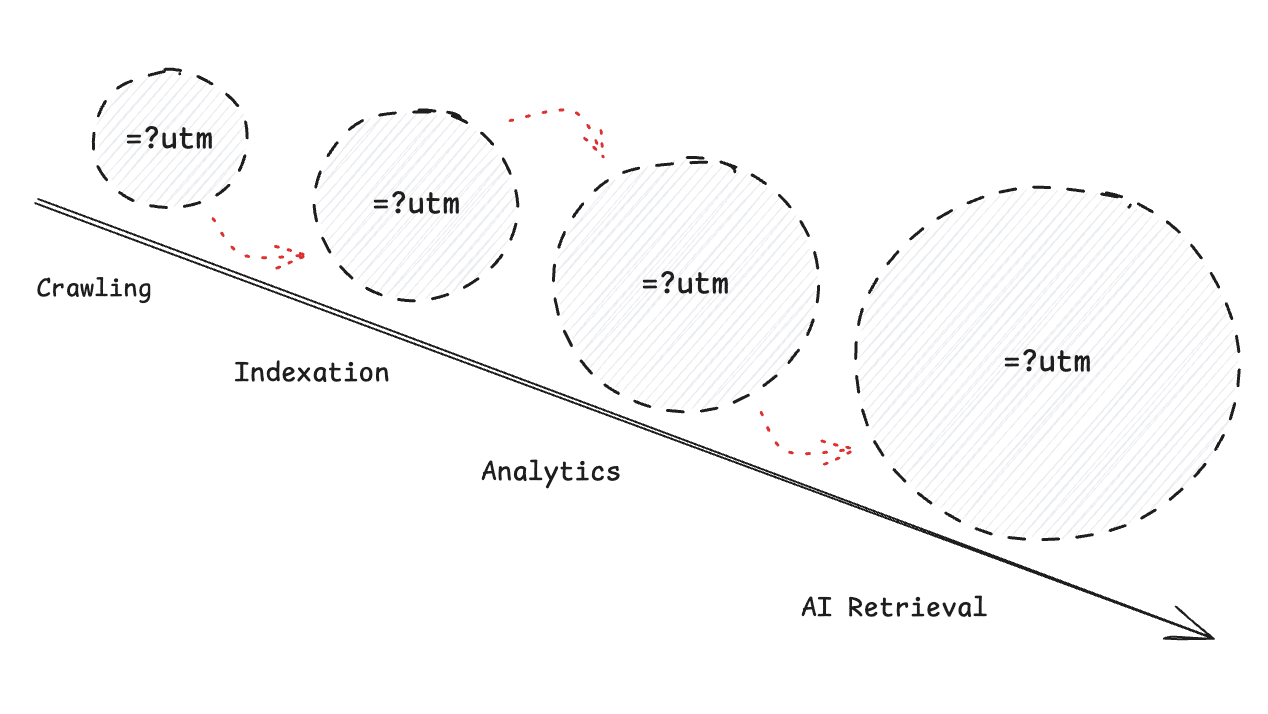
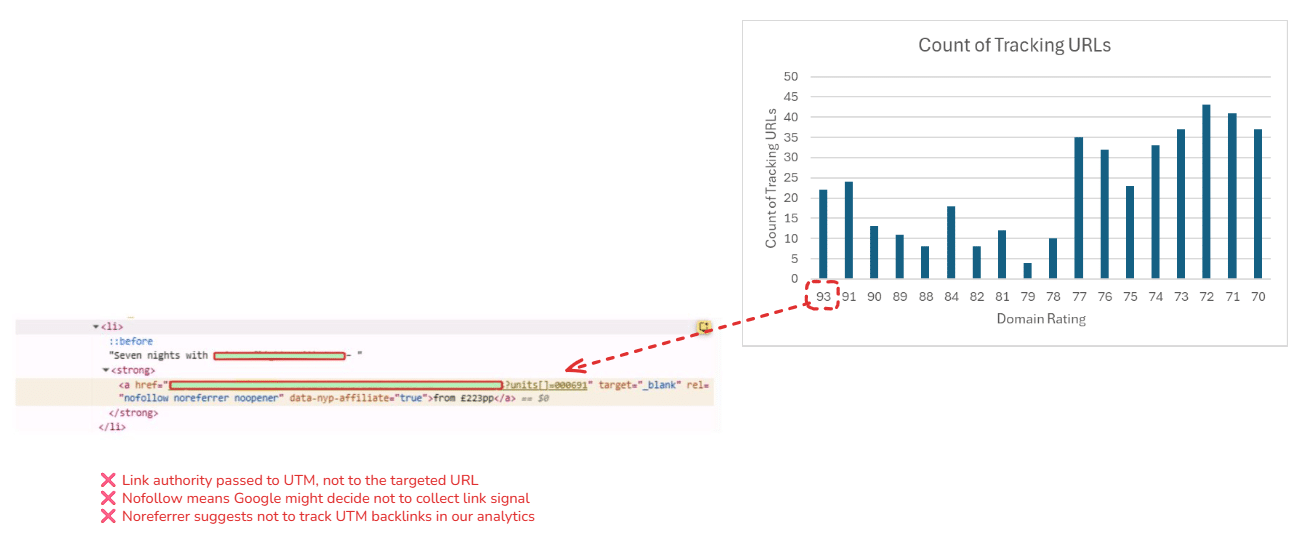
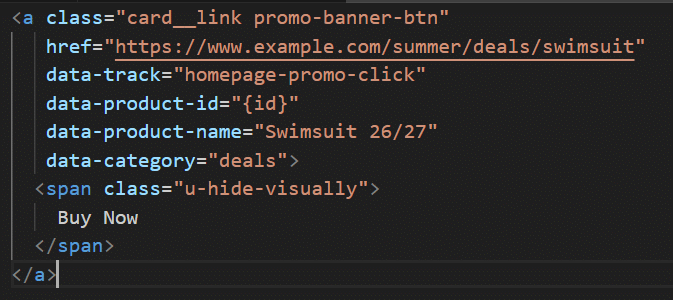
Internal links are powerful for boosting SEO, but using tracking parameters can be detrimental. Let me share how you can clean up your internal links to enhance your site
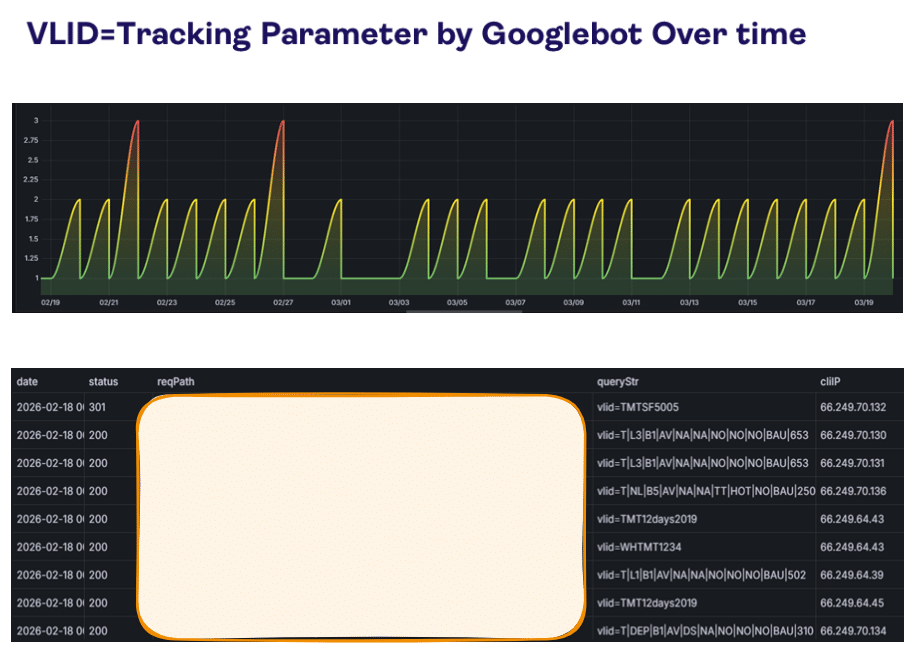

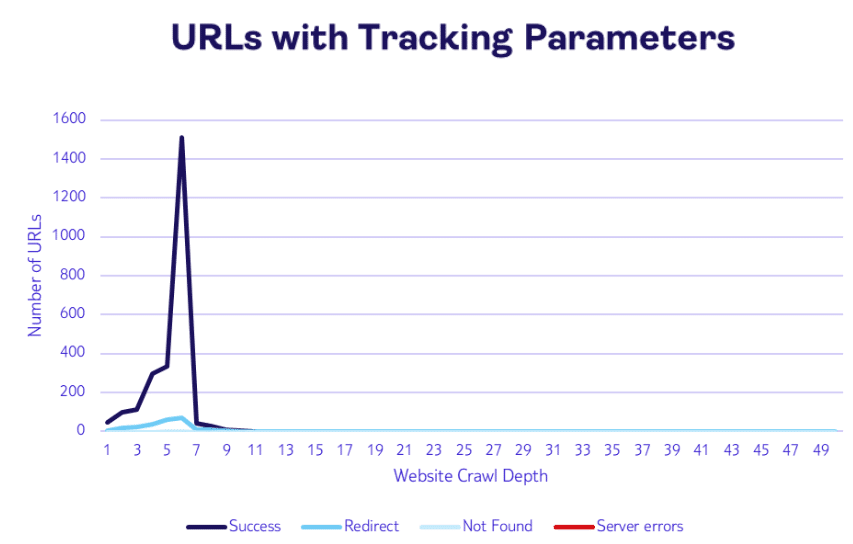
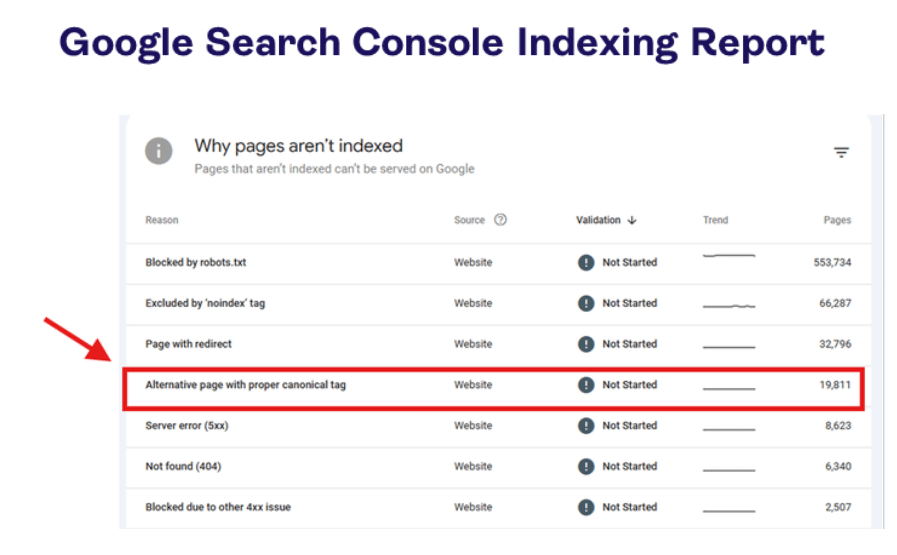
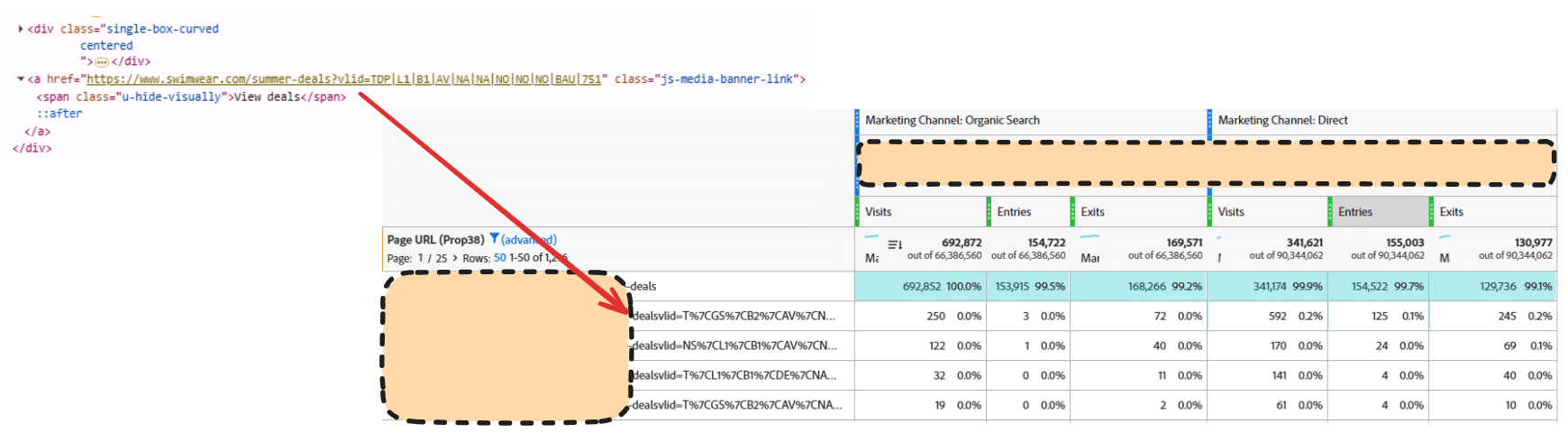

Inspired by this post on Search Engine Land.

FAQs
What does the post say about tracking parameters in internal links?
It notes that tracking parameters in internal links can be detrimental to your site and its SEO. The article also suggests cleaning up internal links to improve indexing and overall site performance.
How does the article suggest improving internal linking?
It recommends cleaning up internal links to enhance your site’s indexability and user experience. The goal is to reduce tracking parameters that can interfere with crawling and ranking.
What related concepts are mentioned in the post's visuals?
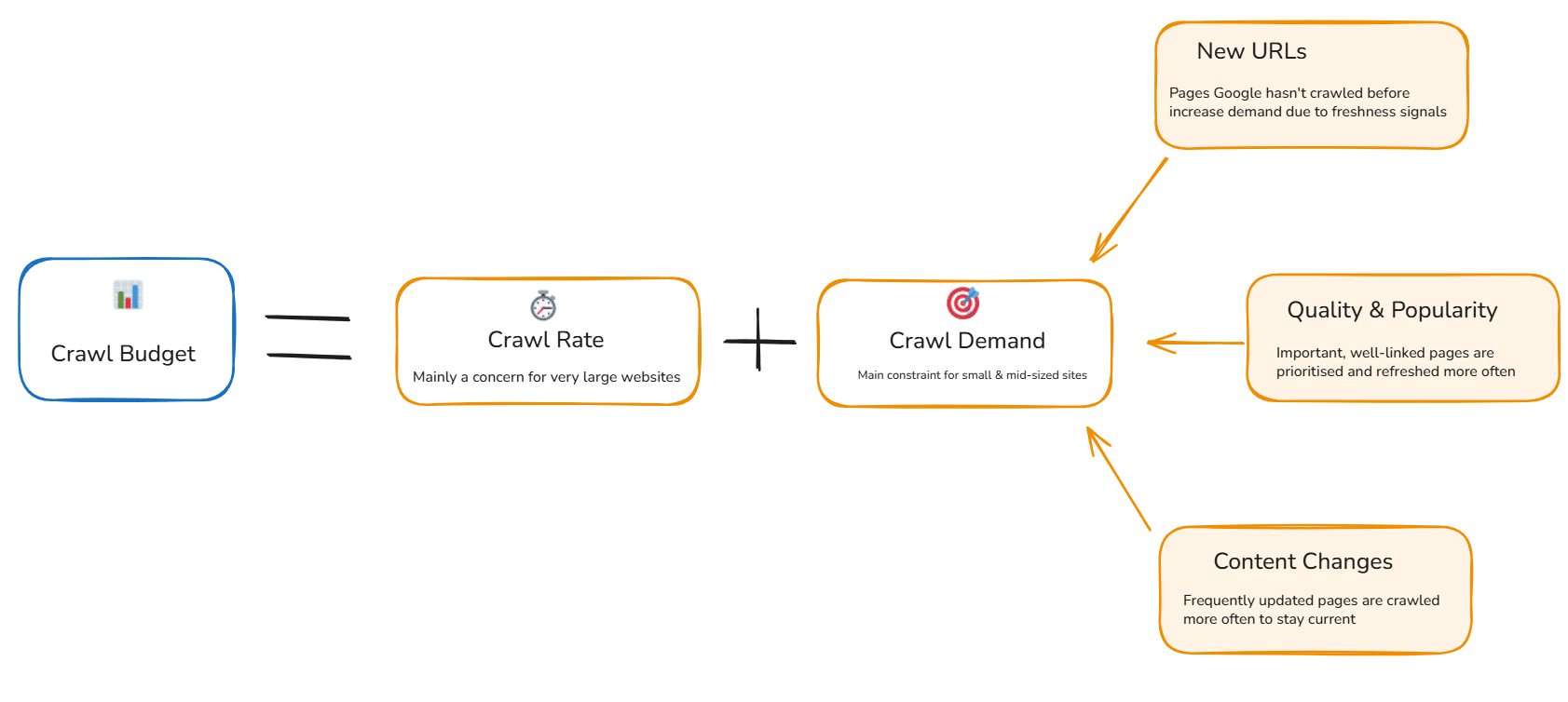
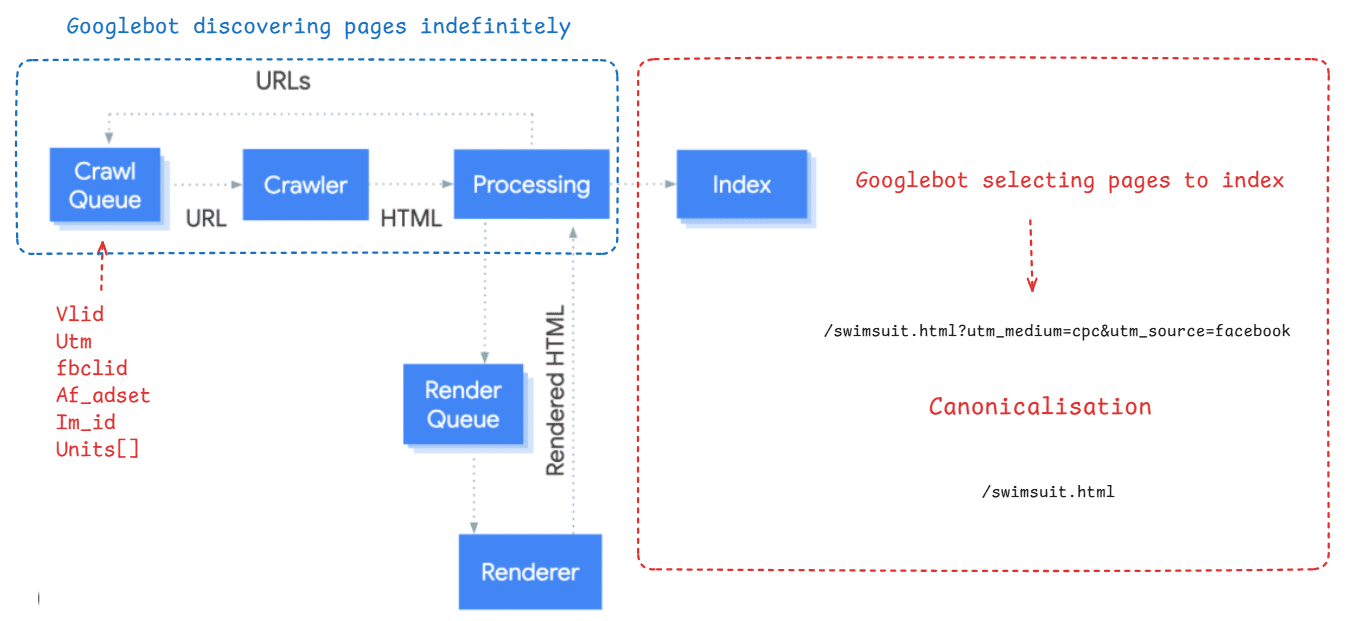
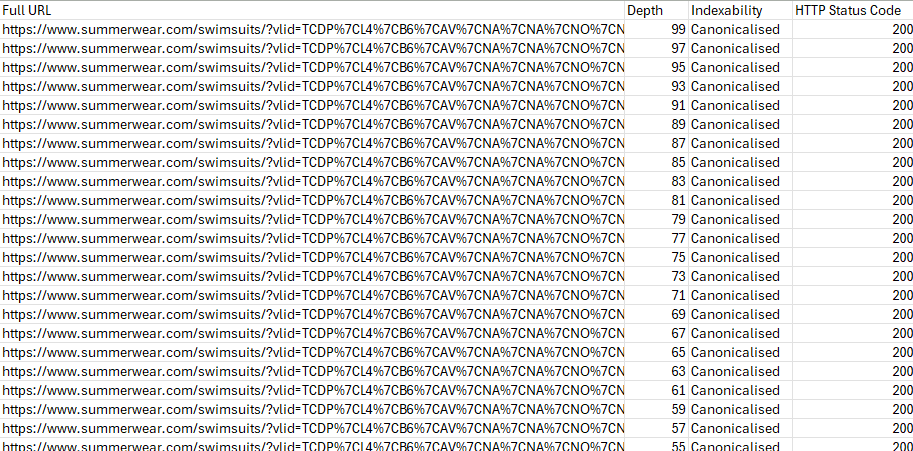
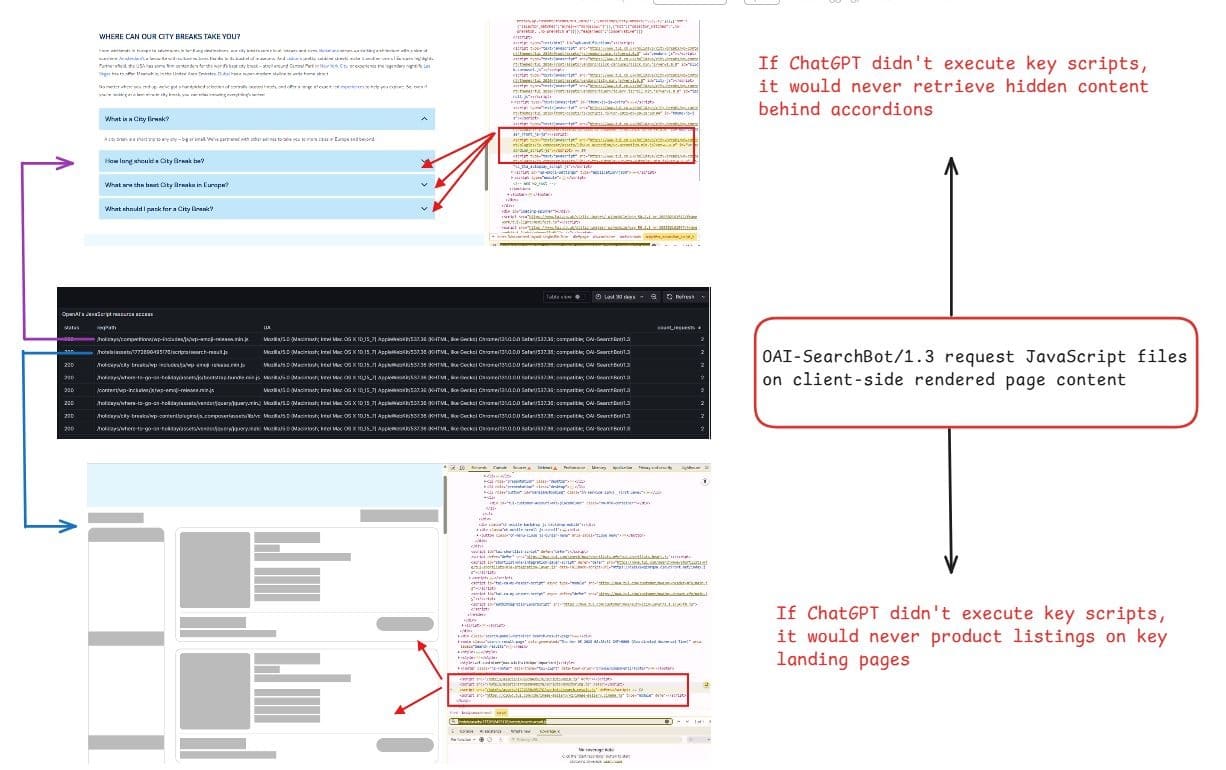
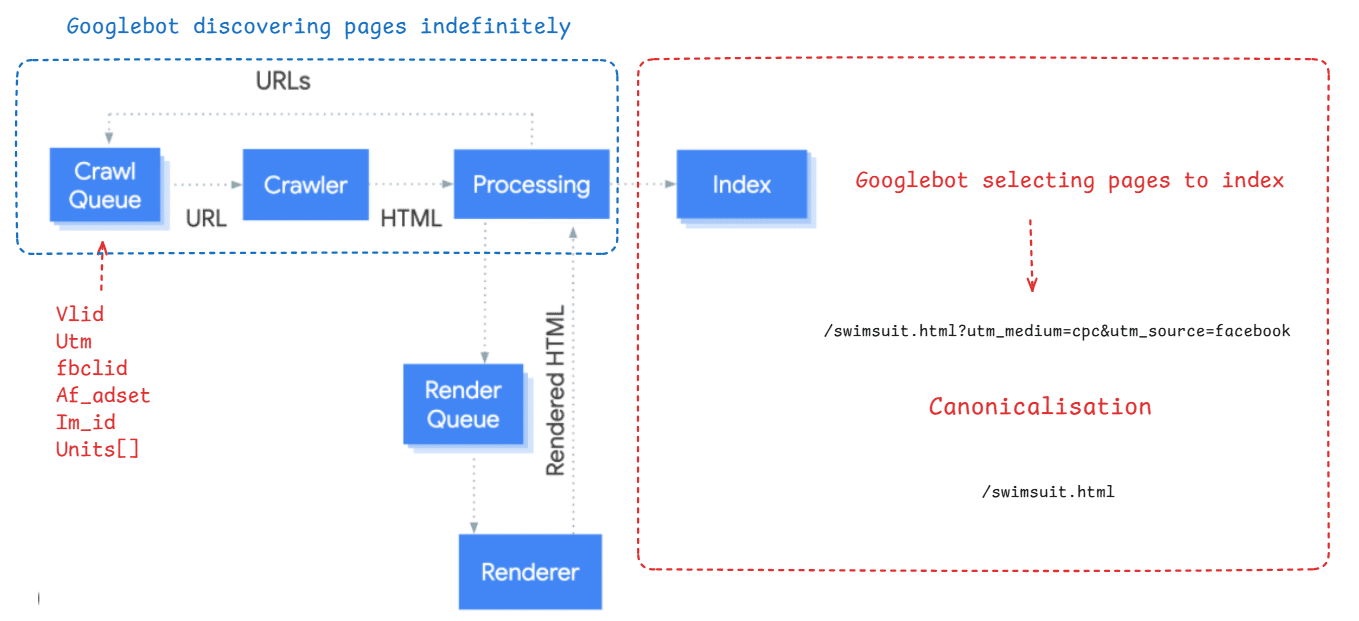
The post includes diagrams about crawl budget, Googlebot indexing, and canonicalization. These visuals illustrate how tracking parameters can affect indexing and crawl efficiency.
Is the post inspired by external content?
Yes, it notes inspiration from a Search Engine Land article about tracking parameters in internal links. The original post is linked in the article.
What topics do the included images cover?
The images discuss topics like crawl budget, Googlebot indexing, and canonicalization. They also reference tracking parameters and related concepts such as UTM and fbclid.
Leave a Reply