I rely on Google Search Console because it is excellent at collecting search data. The challenge is that it still does not make interpretation easy.
When I open almost any property, I usually find thousands of queries, landing pages, impressions, clicks, rankings, and click-through rates. That volume is useful, but it can quickly become overwhelming when I am trying to answer one simple question: what should I do next?
For years, my workflow was familiar: export the data into Excel or Google Sheets, build pivot tables, apply filters, and start digging for patterns. That approach works, but it is slow. More often than not, I am searching for insights without knowing exactly what I am looking for.
That is where AI makes the workflow more useful. I use it to speed up the hardest part of Search Console analysis: finding meaningful patterns hidden across thousands of rows of search data.
I think of Google Search Console as my source of truth and AI, whether ChatGPT or Claude, as the analyst sitting beside me. GSC shows me what happened. AI helps me explore why it happened, uncover opportunities I might miss, and organize messy data into decisions I can act on.
A quick note on regex
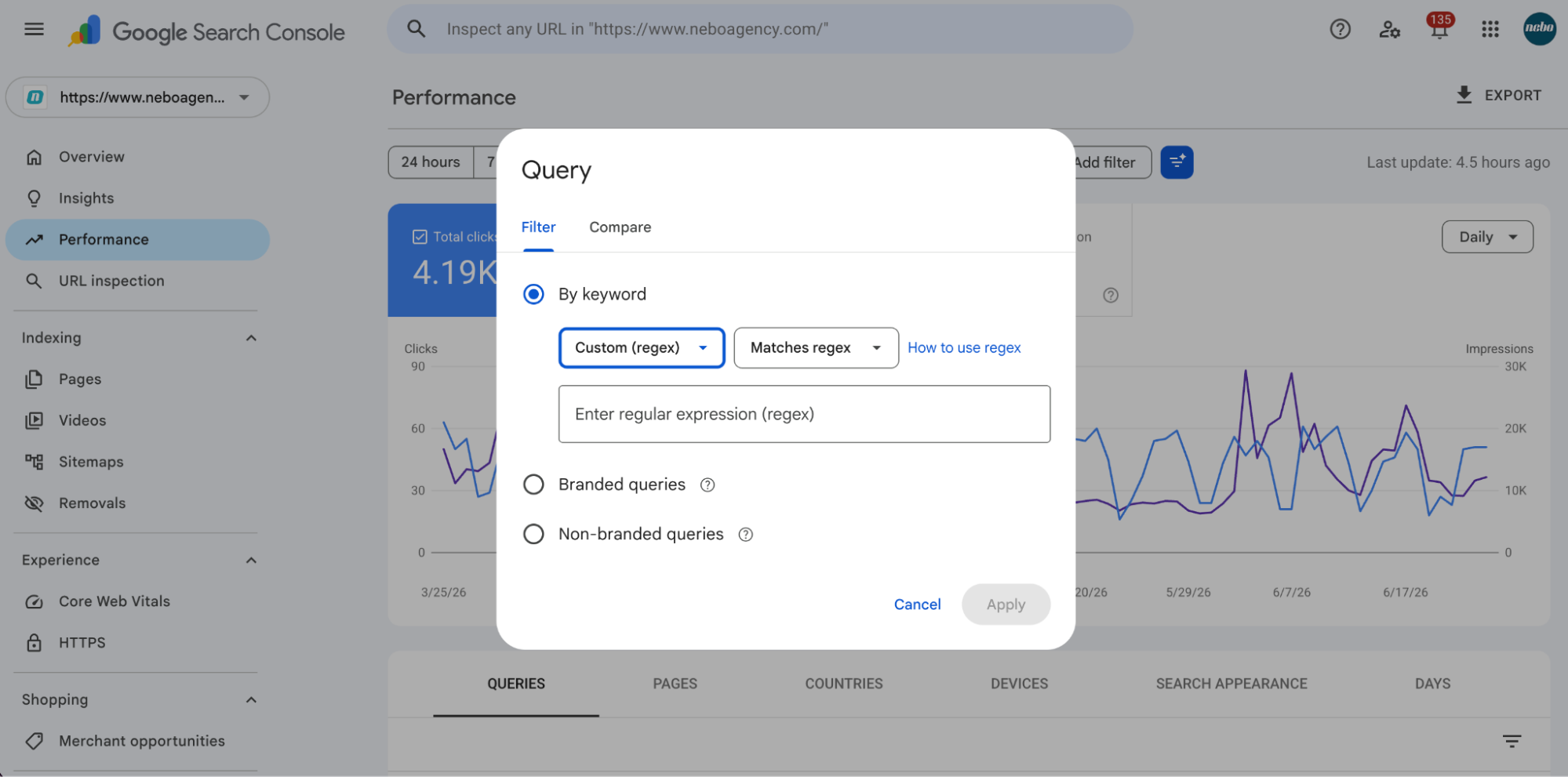
Most of the examples I use start in the same place inside Google Search Console: Performance → Queries → + Add Filter → Query → Custom (regex).
From there, I enter a regular expression to filter query data before exporting it for analysis.
The useful part is that I no longer need to memorize regex syntax. I can ask ChatGPT to write it for me. For example, I might prompt: Create a regex for Google Search Console that matches queries beginning with question words.
ChatGPT may return something like (?i)^(who|what|why|how|can|does|will|should)b.
If I need something more specific, I simply describe the pattern I want. I might ask for a regex that matches queries containing five or more words, identifies comparison searches, or finds branded queries that include product names.
The better I describe the pattern, the better the regex usually becomes.
Here are seven practical ways I combine Google Search Console with AI so I can spend less time sifting through data and more time making decisions.
1. I stop looking only at queries and start looking at intent
Most Search Console analysis still happens at the keyword level. The problem is that people do not really search by keyword. They search with intent.
Instead of reviewing thousands of individual queries one by one, I use regex to isolate investigation-focused searches before exporting the data.
One useful regex is (?i)^(best|top|vs|review|reviews|compare|comparison).
After exporting the filtered query data, I ask Claude or ChatGPT to classify intent. My prompt is usually something like: Categorize these queries into informational, navigational, investigation, transactional, and local intent. Return a CSV with classifications and confidence scores.
This helps me spot patterns that are difficult to see keyword by keyword. Informational traffic may be growing while commercial investigation queries are declining. Transactional queries may rank well but earn weak click-through rates. Comparison searches may be driving impressions without having dedicated content to support them.
When I segment by intent, the next steps become much clearer.
2. I discover questions my audience is already asking
Question-based keyword research is not new, but AI helps me identify themes across hundreds of question-oriented searches much faster.
I start with a regex like (?i)^(who|what|where|when|why|how|can|does|should|will)b.
Then I export the results and ask Claude or ChatGPT: Group these questions into common themes and identify unanswered topics.
A Google Search Console query filter highlights how regex can narrow SEO performance data, helping marketers turn thousands of search terms into focused insights.
Instead of manually reviewing hundreds of questions, I can quickly see broader patterns around pricing concerns, product comparisons, implementation challenges, and industry-specific use cases.
This becomes more than a content exercise. I can use these themes to improve FAQs, support resources, sales enablement materials, and AI Overview optimization.
The best opportunities are often not hidden in one query. They are hidden in clusters of related questions.
3. I find queries likely to trigger AI Overviews
Google does not give me a filter for queries likely to trigger AI Overviews, but I can build a useful approximation.
I start by isolating common informational and comparison patterns with a regex like (?i)^(what is|how to|best|vs|difference between|guide to).
Then I export the matching queries and ask Claude or ChatGPT: Review these queries and group them by the content format needed to answer them effectively.
The themes often fall into definitions, tutorials, comparisons, or expert recommendations.
This helps me see where my content may need to shift from simply ranking for keywords to becoming the best available answer. Increasingly, those are not always the same thing.
4. I track emerging trends earlier
Traditional keyword research can be reactive. By the time a trend is obvious in keyword tools, competitors may already be building content around it.
Google Search Console can help me identify shifts earlier, as long as I know how to look for them.
Instead of searching for individual keywords, I use ChatGPT to build regex around broader concepts. For example, I might prompt: Create a Google Search Console regex to identify searches related to AI agents, copilots, assistants, automation, and autonomous workflows.
The output may look like (?i)(ai agent|agentic|copilot|assistant|automation).
This same approach works for new technologies, product categories, competitors, industry buzzwords, and changing customer concerns.
Once I filter and export the data, I let AI look for emerging themes. A prompt I like is: Review these queries and identify emerging themes, new terminology, and shifts in search behavior. Highlight which topics appear to be gaining traction, recommend whether they deserve a new content asset or an update to an existing page, and identify any patterns that could influence our content strategy.
Instead of only confirming that a trend exists, AI helps me decide whether the trend is meaningful enough to act on and what the next move should be.
5. I surface conversion intent inside informational traffic
One of the most overlooked opportunities in Search Console is finding bottom-of-funnel signals inside queries that appear informational at first glance.
I might ask ChatGPT: Create a regex for searches that indicate evaluation, comparison, pricing, alternatives, migration, implementation, or vendor selection intent.
An example output is (?i)(cost|pricing|price|vs|alternative|compare|implementation|migration).
I apply that regex to the query report, export the filtered data, and then ask Claude or ChatGPT to analyze it.
My prompt usually looks like this: Review these Google Search Console queries and identify recurring buying signals. Group them into themes such as pricing, comparisons, implementation, and vendor evaluation. Recommend which existing pages should better address this intent, and identify opportunities to improve content through stronger CTAs, internal links, comparison tables, FAQs, or supporting resources.
A visual metaphor for AI turning messy Google Search Console queries into clear SEO decisions, separating qualified intent from irrelevant traffic signals.
I often find that pages created for top-of-funnel education are already attracting visitors who are evaluating solutions. In that case, the best opportunity may not be creating a new page. It may be improving the page that already earns the visit, so users can take the next step without breaking the informational experience.
Sometimes the biggest content opportunity is recognizing the conversion intent already reaching the pages I have.
6. I find audience-specific opportunities
One of my favorite ways to uncover new content opportunities is filtering queries by industry, audience, or customer segment. It quickly shows me whether my content is resonating with the audiences I intended to reach or revealing opportunities I had not considered.
I start by asking ChatGPT to create a regex based on the audience segments that matter most to the business.
For example, I might prompt: Create a Google Search Console regex that identifies queries related to healthcare, manufacturing, retail, education, financial services, government, and nonprofit organizations.
An example output is (?i)(healthcare|hospital|medical|manufacturing|factory|retail|education|school|financial|bank|government|public sector|nonprofit).
After applying the filter and exporting the results, I ask Claude or ChatGPT: Analyze these queries and group them by audience segment. Identify which industries show the strongest search demand, what recurring questions or pain points each audience has, and recommend opportunities for new content, landing pages, case studies, or internal linking that would better serve those audiences.
The differences can be valuable. Healthcare searches may consistently focus on compliance, while manufacturing queries may revolve around implementation. Retail searches may reveal entirely different use cases than financial services searches.
7. I uncover striking-distance opportunities at scale
Every SEO knows the classic advice: look at keywords ranking in positions 5-15 to identify opportunities within striking distance.
The challenge is doing that at scale. A report with hundreds of queries where a site is close to stronger rankings can become overwhelming fast.
I take the regex patterns above a step further. I apply the filters that match my goals, then narrow the report to positions 5-15 before exporting the queries.
Then I ask my AI analyst: Identify recurring themes across these queries and recommend page-level optimizations rather than keyword-level optimizations.
Instead of getting tiny recommendations for individual keywords, I often uncover larger opportunities. A page may be missing subtopics, comparison details, stronger internal links, or use cases that would make it more complete.
The result is usually fewer optimizations, but more meaningful ones.
Turning Search Console data into decisions
As an SEO, I do not have a data shortage. I have a prioritization problem.
Google Search Console remains one of the richest sources of insight into how people discover a business. The difficult part is turning thousands of rows into something actionable.
That is where AI fits into my workflow. It helps me uncover patterns, organize information, and surface opportunities I might otherwise miss. It is not a replacement for SEO strategy, experience, or critical thinking.
The real advantage is not writing better regex or exporting cleaner spreadsheets. It is spending less time searching for insights and more time acting on them.
Because data does not improve SEO. Better decisions do.
I can publish consistently, follow SEO best practices, and still watch competitors outrank me. When that happens, I usually find that the issue is not content quality alone. It is content coverage. Competitors are answering questions my audience is already asking, while my site is not fully part of that conversation yet.
That is where I use content gap analysis. It helps me identify the topics competitors rank for that I do not, then decide which opportunities are actually worth pursuing.
Finding gaps is rarely the hard part. SEO tools make that fairly easy. The real challenge is making sense of thousands of keywords across several reports and deciding what deserves attention first.
My workflow combines competitor data, first-party search data, and AI so I can prioritize content opportunities around business impact instead of search volume alone.
I bring my SEO data together before analyzing it
In this workflow, I use Semrush to identify competitive opportunities, Google Search Console to validate where my site already shows signs of authority, and Google Analytics to add business context. Then I use Claude to bring those datasets together, group related opportunities, identify patterns, and help me decide what belongs on the content roadmap.
I follow this process in one of two ways.
I export reports directly from the platforms and upload them to Claude.
If I have connected those platforms through MCP (Model Context Protocol, a standard that allows AI models to connect securely to data sources), I let Claude pull the data directly without manual exports. The workflow changes, but the analysis does not.
Here is the process I use to turn a pile of SEO data into a prioritized content plan.
Step 1: I choose the right competitors
A content gap analysis is only as useful as the competitors I compare myself against. That sounds obvious, but it is one of the easiest places to go wrong.
If I compare my site to Amazon, Reddit, or Wikipedia, I will end up with thousands of keyword “opportunities” that were never realistic in the first place. My goal is not to find every site ranking for my target keywords. My goal is to find businesses competing for the same audience.
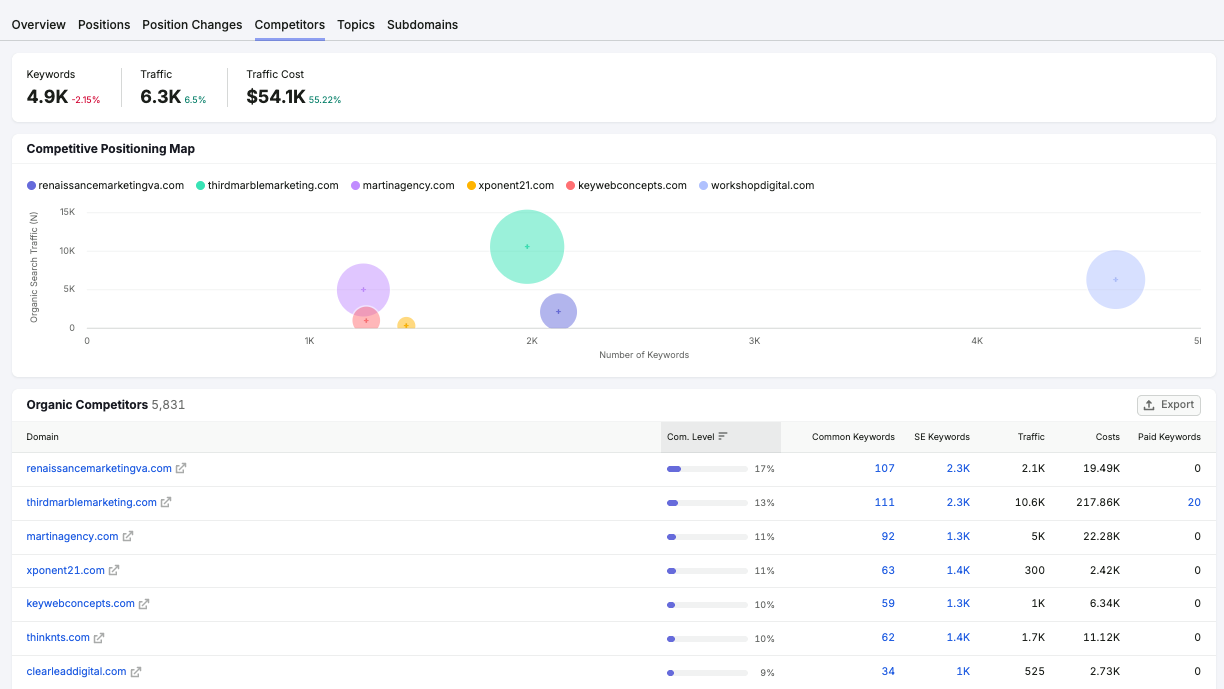
I usually start with Semrush’s Organic Competitors report. Instead of relying only on a list of known competitors, I use this report to find domains that compete across many of the same keywords. From there, I narrow the list to three to five sites that closely match the business and target audience I am analyzing.
I do not worry if a few familiar names do not make the cut. Business competitors and organic search competitors are not always the same.
I also filter out sites that can distort the analysis, including large marketplaces like Amazon, community-driven sites like Reddit or Quora, reference sites like Wikipedia, local directories, review sites, and publishers that do not directly compete with the business.
There are exceptions. If I am analyzing a publisher, comparing against other editorial sites makes sense. The key is choosing competitors that create the type of content I am realistically trying to outperform.
A Semrush competitor analysis view turns organic search data into a clear map of rival domains, traffic potential, keyword overlap, and content gap opportunities.
Before I move forward, I sanity-check the competitor list with stakeholders. Sales or product teams may know about newer competitors or strategically important niches that do not yet show up clearly in Semrush.
Once I have settled on the right competitors, I am ready to find the gaps that matter most.
Step 2: I gather and prepare the data
With the competitor list finalized, I collect the data Claude will analyze. Whether I upload exports or connect through MCP, the goal is the same: bring together competitive rankings, my site’s search performance, and engagement data so I can separate meaningful opportunities from noisy keyword lists.
I like to pull data from three core sources.
Semrush: I find the gaps
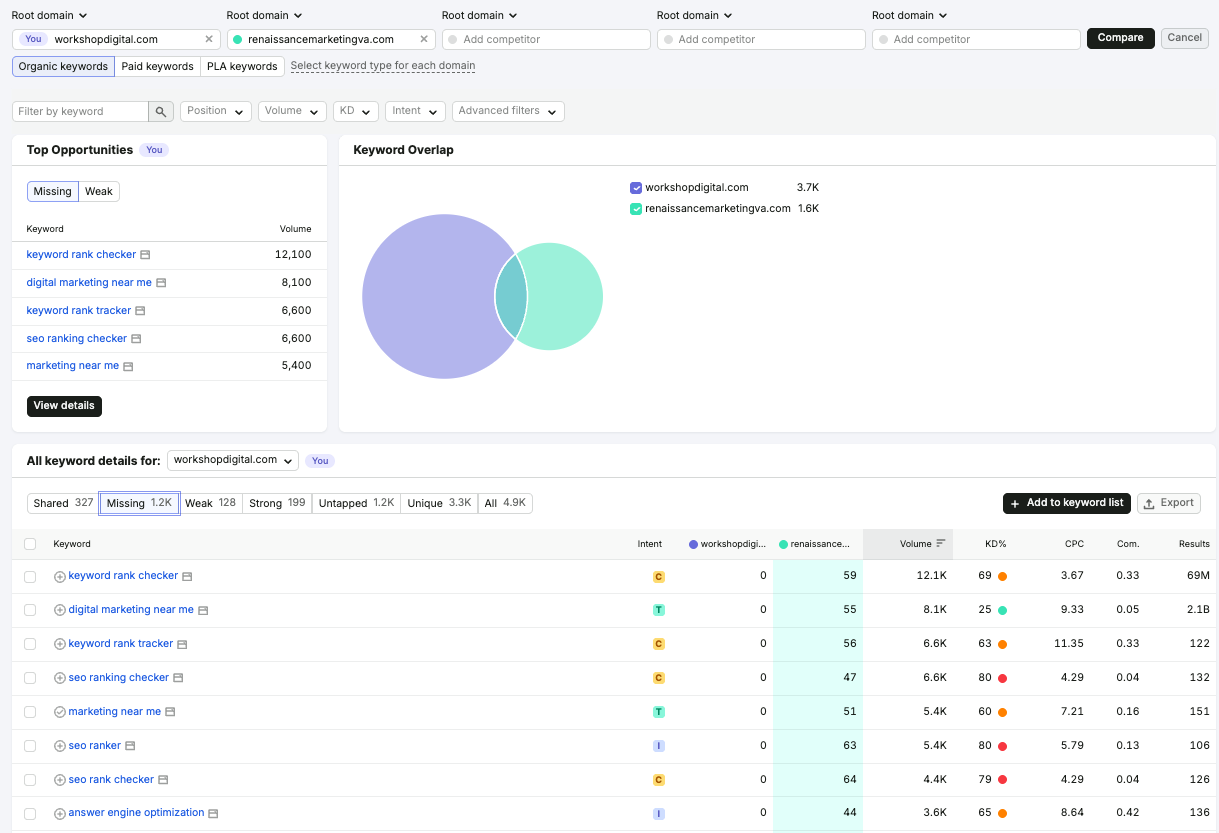
I start with Semrush’s Keyword Gap tool using the competitors selected in Step 1.
From there, I pay close attention to three buckets: keywords competitors rank for and I do not, keywords where I rank but competitors rank higher, and keywords where I rank but competitors do not.
The first bucket often points to missing topics or content hubs. The second bucket can reveal quicker wins, especially when my site already appears on Page 1 or Page 2. The third bucket shows existing strengths that I should protect and continue building around.
Google Search Console: I validate the opportunity
Next, I check Google Search Console before assuming every missing keyword deserves a new page.
For example, Semrush may show that I do not rank for a keyword, but GSC might reveal that I already receive impressions for closely related queries. That tells me Google has started associating my site with the topic, even if rankings have not caught up yet.
Those “almost there” topics often deserve a higher priority than topics where I would be starting from scratch.
In GSC, I look for queries with high impressions and average positions between 8 and 20, existing pages ranking for related terms, and long-tail queries that reveal additional search intent.
Google Analytics: I add business context
Search volume is only part of the story. Engagement metrics help me answer a more important question: if I improve visibility for this topic, is it likely to support business goals?
A Semrush content gap analysis view reveals where a competitor ranks and the analyzed site does not, turning keyword overlap data into a practical roadmap for SEO content opportunities.
I review metrics such as organic sessions, engagement rate, average engagement time, key events or conversions, and landing page performance.
If a related content hub already drives engaged visitors or conversions, expanding that topic may be a smarter investment than chasing a completely new keyword with higher search volume.
I clean the data before handing it to Claude
If I am manually downloading the data and uploading it to Claude, I clean it first. Claude is excellent at finding patterns, but it can only work with the data I provide. Cleaner data leads to cleaner topic clusters and better recommendations.
I remove duplicate keywords, competitor-branded terms, careers queries, login queries, support queries, locations or product lines outside the business, keywords with clearly different search intent, and high-intent commercial keywords that are too broad to compete for.
For a manual workflow, I export Keyword Gap data from Semrush, query data from Google Search Console, and landing page performance data from Google Analytics, then upload the files to Claude. For a connected MCP workflow, I ask Claude to retrieve the Keyword Gap report, GSC query data, and GA4 landing page metrics directly from connected accounts.
Step 3: I ask Claude to find the story in the data
At this point, I should have a clean dataset that combines competitive keyword gaps, Search Console performance, and Google Analytics data.
This is where the workflow becomes much more useful. Instead of scrolling through thousands of rows looking for patterns, I ask Claude to organize the data into something I can actually build a strategy around.
The mistake I see most often is asking AI to “cluster these keywords.” That usually produces clusters based on keyword similarity alone. That can be useful, but it does not tell me what to do next.
Instead, I ask Claude to think like an SEO strategist. I give it context about the business, including products or services, target audience, primary business goals, content priorities or constraints, and the exported or connected data from Semrush, GSC, and Google Analytics.
Then I ask Claude to organize opportunities by search intent, funnel stage, business relevance, existing authority signals from GSC, user engagement from GA4, recommended content format, and internal linking opportunities.
Rather than returning a spreadsheet of grouped keywords, I want Claude to produce topic clusters with a clear recommendation for each one.
For example, one cluster might be labeled Technical SEO Audits and include supporting keywords, estimated opportunity, existing pages that could be updated, whether a new page is needed, internal linking recommendations, a priority score, and the reasoning behind the recommendation.
A content gap workflow turns scattered SEO signals into topical clusters, showing where AI search visibility, privacy-first analytics, and technical SEO need deeper coverage.
Another cluster might reveal that several competitor keywords can be addressed by expanding an existing guide instead of publishing three separate articles. That is the kind of insight that is hard to spot manually but much easier for AI to surface.
I separate quick wins from long-term investments
Not every opportunity belongs on the same roadmap. As part of my prompt, I ask Claude to classify each cluster into quick wins, new content opportunities, and authority plays.
Quick wins are existing pages that can be refreshed, expanded, or better optimized. New content opportunities are topics that deserve dedicated content because the site has little or no visibility. Authority plays are larger subject areas that may require multiple pieces of content and ongoing investment to compete effectively.
This simple step helps me move from an overwhelming keyword list to a roadmap with both short-term wins and long-term initiatives.
I do not skip the human review
Claude can organize information remarkably well, but it does not know the business the way I do.
Before moving on, I ask whether the topic supports business goals, whether multiple search intents are being combined into one cluster, whether existing content could already satisfy the need, whether the opportunity is realistic given authority and resources, and whether I would actually assign the topic to a writer.
If the answer is no, I refine the cluster or remove it.
The goal is not to accept every AI recommendation. The goal is to spend less time organizing data and more time making strategic decisions.
The biggest prompt lesson is simple: I do not ask Claude to organize keywords. I ask it to recommend what my content strategy should be based on the data I have provided.
Step 4: I score and prioritize the opportunities
Once Claude has grouped the keywords into topic clusters, the next step is deciding what deserves attention first.
This is where many content gap analyses fall apart. Teams naturally gravitate toward the biggest search volumes, but volume is only one piece of the puzzle. A topic that attracts qualified visitors and supports business goals is often a better investment than a high-volume keyword that is difficult to rank for or unlikely to convert.
I score each opportunity across several criteria before I build a roadmap.
A prioritized content gap roadmap turns scattered SEO data into clear next moves, ranking quick wins by impact, effort and AI visibility.
Business relevance
I start with a simple question: if this content performs well, does it help the business?
Topics aligned with products, services, or the customer journey should carry more weight than informational topics with little commercial value.
Existing authority
Next, I look at signals from Google Search Console. If my site already earns impressions or ranks on the second page for related queries, Google has likely established some level of topical authority.
In those cases, improving an existing page or expanding a content hub may produce results much faster than starting from scratch.
Search demand
Search volume matters, but I do not let it dominate the scoring model.
A collection of related long-tail queries with moderate demand can sometimes generate more qualified traffic than one broad keyword.
Ranking difficulty
I review the current search results before committing to a topic. I look at whether authoritative brands dominate the first page, whether the intent is informational, commercial, or transactional, what types of content are ranking, and whether I can realistically create something more useful or complete.
This quick reality check keeps me from chasing opportunities that are not practical.
Estimated effort
Finally, I consider the work involved. Some opportunities require a light refresh of an existing article. Others call for a new content hub supported by multiple pages.
Both can be worthwhile, but they should not carry the same priority when resources are limited.
I let Claude apply the framework
Once I define the scoring criteria, Claude can evaluate every topic cluster consistently.
For example, I may ask Claude to score each opportunity on a five-point scale for business relevance, existing authority, search demand, ranking difficulty, and content effort. Then I ask it to calculate an overall priority score and explain why each recommendation received that score.
A tactical SEO refresh brief turns AI-assisted content gap analysis into page-level priorities, surfacing validation lessons, effort estimates, and the biggest opportunities.
The explanation is just as valuable as the number. If I disagree with a recommendation, I can adjust the weighting, add more business context, and ask Claude to score the opportunities again.
By the end of this step, I have more than a list of content ideas. I have a prioritized content strategy that shows what to tackle next, what can wait, and what is not worth pursuing.
Step 5: I turn priorities into page-level recommendations
Once I have prioritized the opportunities, the next step is figuring out exactly what to change.
Rather than handing a team a ranked list of topics, I ask Claude to generate page-level recommendations for the highest-priority opportunities. This is where connected data becomes especially valuable.
Because Claude has access to Semrush research, Google Search Console performance, Google Analytics metrics, and my prioritization framework, it can evaluate each page in context instead of treating every recommendation the same.
For each priority page, I ask Claude to produce a recommendation that explains why the page was selected, the primary keyword cluster, current rankings and impression data, supporting evidence from GSC and competitor research, recommended updates, estimated effort, expected impact, and priority level.
One of the biggest advantages of this approach is validation.
Before recommending a refresh, Claude can compare URL-level Search Console data against the original analysis. Sometimes what looks like a strong opportunity turns out to be misleading. A keyword may have inflated impression counts, a URL could have been mislabeled in an export, or the page may not be as close to ranking as it first appeared.
Catching those issues before assigning work can save hours of unnecessary effort.
The recommendations also make stakeholder conversations easier. Instead of saying, “I think we should update this page,” I can point to the supporting data, explain why it is a priority, estimate the effort involved, and tie the recommendation back to the larger content strategy.
I treat these recommendations as implementation plans rather than full content briefs. They help SEO and content teams understand what should change, why it matters, and where to focus first. Writers can then use those recommendations to create or update content with confidence.
Step 6: I measure whether the gap is closing
Publishing the content is not the finish line. It is the start of the next round of analysis.
Rows of illuminated data cabinets and paper files stretch into the distance, capturing the pressure on marketers to turn fragmented customer data into a smarter performance engine.
I begin with Google Search Console, tracking whether target queries are gaining impressions, improving in average position, and generating more clicks. When I refresh an existing page, I compare performance before and after the update to see whether the changes actually moved the needle.
Next, I look at Google Analytics. Better rankings do not always translate into better business outcomes, so I review organic traffic alongside engagement and conversion metrics. If an updated page attracts more visitors but fails to keep them engaged or contribute to conversions, I know it is time for another round of optimization.
If I am using Claude through MCP, I can also ask it to compare performance over time and summarize what changed. I might ask which refreshed pages improved the most, which content clusters gained the most visibility, which recommendations drove the strongest business results, and which opportunities still need attention.
Instead of comparing reports month after month, Claude can quickly surface significant changes and point me toward the pages that deserve attention.
I do not treat content gap analysis as a one-time exercise. Competitors publish new content, search behavior shifts, and my own site authority evolves. I like to repeat this workflow every quarter, or more often in fast-moving industries, so I can keep finding new opportunities and stay ahead of competitors.
The tools will continue to improve, but the repeatable workflow is what creates the advantage.
I build a repeatable content gap analysis process
A content gap analysis helps me prioritize opportunities worth pursuing instead of chasing every possible keyword.
Semrush helps me uncover competitive gaps. Google Search Console shows where I already have momentum. Google Analytics adds the business context that rankings alone cannot provide. Claude brings those datasets together, helping me identify patterns, prioritize opportunities, and create actionable recommendations in a fraction of the time it would take manually.
Whether I upload reports or connect my tools through MCP, the workflow stays the same. I gather the right data, validate the opportunities, let AI organize the information, and apply my own expertise to decide what comes next. That is the part AI cannot replace.
The biggest advantage is not simply having better prompts or faster analysis. It is having a repeatable process that helps a team make smarter content decisions every quarter.
Prompt template: My prioritized content gap roadmap
Here is the prompt I use after I have gathered the data, whether I have uploaded exports from Semrush, Google Search Console, and Google Analytics or connected those tools to Claude through MCP.
“You are an experienced SEO strategist helping me perform a content gap analysis.
I’ll either provide exported reports from Semrush, Google Search Console, and Google Analytics, or you’ll access those tools through connected MCP integrations.
My goal is to identify the highest-impact content opportunities based on competitor visibility, existing authority, business value, and implementation effort.
Here’s my business context:
– Company: – Industry: – Products/services: – Target audience: – Primary business goals: – Geographic focus: – Any strategic priorities or constraints: – Tone of voice: [Insert brand voice adjectives here (e.g., authoritative, conversational, technical)].
Using the available data, complete the following tasks.
1. Identify content gaps
Organize keywords into these categories: – Competitors rank and we don’t. – We rank below competitors. – We rank and competitors don’t.
Highlight any content gaps, opportunities to consolidate pages, or keyword cannibalization issues.
2. Validate the opportunities
Use Google Search Console data to determine: – Which topics already receive impressions. – Which pages rank between positions 8 and 20. – Which existing URLs have the strongest chance of improving with optimization.
Use Google Analytics data to determine: – Which pages drive meaningful engagement. – Which pages contribute to conversions. – Which content hubs are worth expanding.
3. Create strategic topic clusters
Group related opportunities by: – Search intent – Business relevance – Funnel stage – Recommended content type – Internal linking opportunities
Don’t cluster based only on keyword similarity. Focus on topics that should become part of the same content strategy.
4. Prioritize every opportunity
Score each topic cluster using: – Business relevance – Existing authority – Search demand – Ranking difficulty – Estimated effort
Assign each opportunity a priority (High, Medium, Low) and explain why.
Separate recommendations into: – Quick wins – New content opportunities – Long-term authority investments
5. Recommend next steps
For every high-priority opportunity, recommend whether we should: – Refresh an existing page – Consolidate multiple pages – Create a new page – Build a pillar page with supporting content
Include supporting evidence for every recommendation.
6. Deliver the results
Create: – An executive summary – Prioritized topic clusters – A scored opportunity table – Page-level recommendations for the highest-priority URLs – A phased implementation roadmap (30, 60, and 90+ days)
If you find conflicting data between Semrush, Google Search Console, and Google Analytics, explain the discrepancy and recommend which source should guide the decision. The output should both be HTML and a Google Sheet.
Before presenting your final recommendations, validate your own analysis. If reviewing Search Console or Analytics data changes your original recommendation, explain why and update your prioritization accordingly.”
This prompt is only a starting point. I add business context, editorial guidelines, and scoring criteria that are unique to the organization I am analyzing. The more context I give Claude, the more useful and actionable its recommendations become.
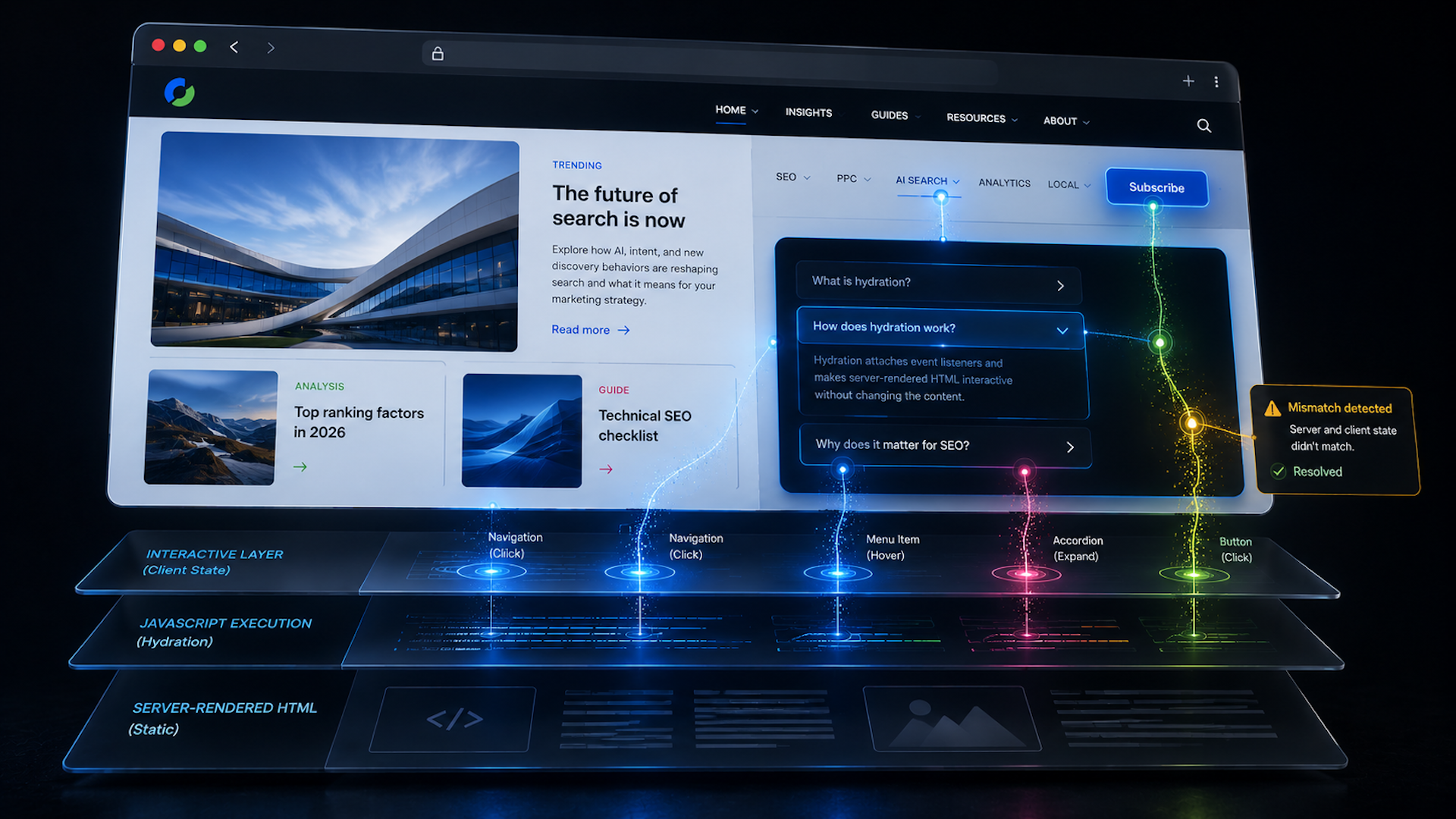
When I work on a site built with a framework like Next.js, Nuxt, SvelteKit, or a similar JavaScript framework, I pay close attention to hydration. It is the step that turns server-rendered HTML into an interactive page, but it is often explained in a way that does not connect clearly to SEO.
I think hydration is easier to understand when I separate content from behavior. The content may already be visible, but the page may not be fully usable until the browser finishes connecting that content to the JavaScript behind it.
What I mean by hydration
Hydration is the process where JavaScript in the browser takes over the static HTML that was built on the server. The server sends a complete page first, and then the framework attaches the logic that makes buttons, menus, forms, filters, and other interactive pieces actually work.
Here is how I usually explain the sequence. First, the server builds the page and sends fully formed HTML to the browser. I can see the content quickly, but the page is not interactive yet. Then the framework loads, walks through the existing HTML, attaches event listeners, and reconnects the visible markup to the application logic. Once that is done, the page behaves like a normal interactive app.
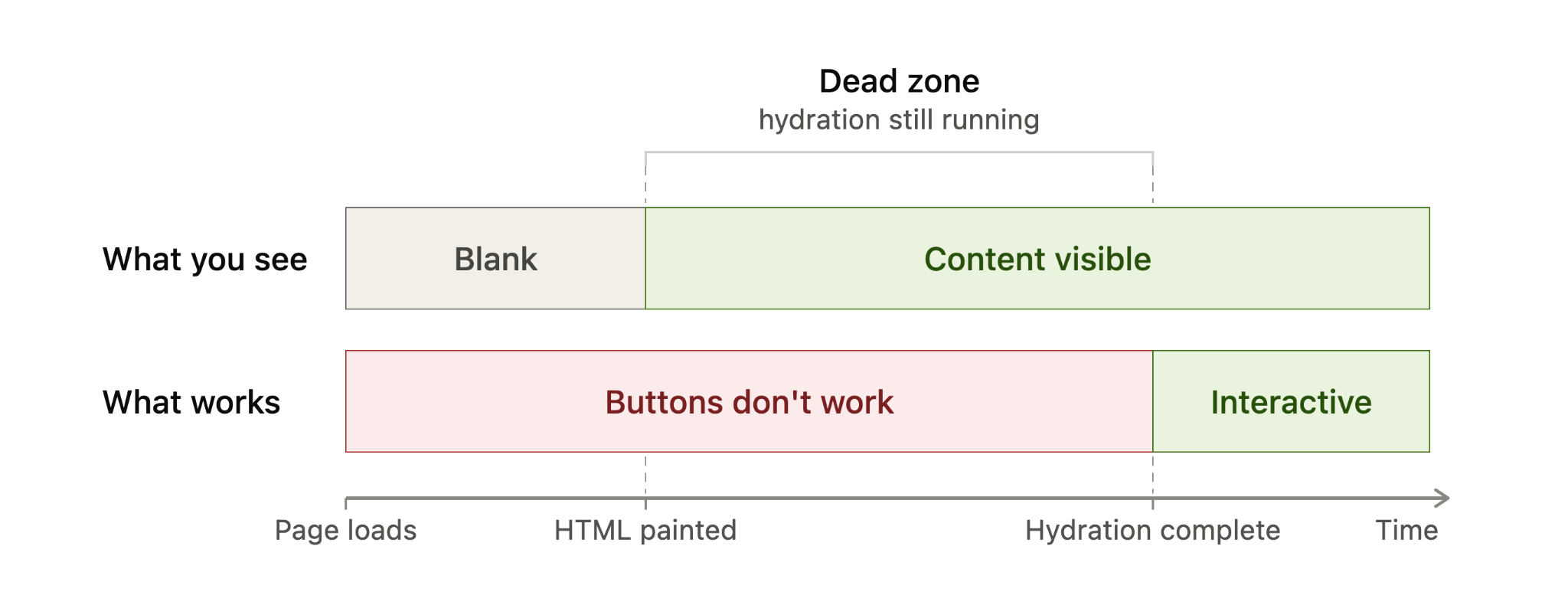
This is why server-rendered HTML can feel fast at first. It can paint quickly and often helps with first impressions and Largest Contentful Paint (LCP). The tradeoff is that, with traditional hydration, the page may appear ready before it is actually usable.
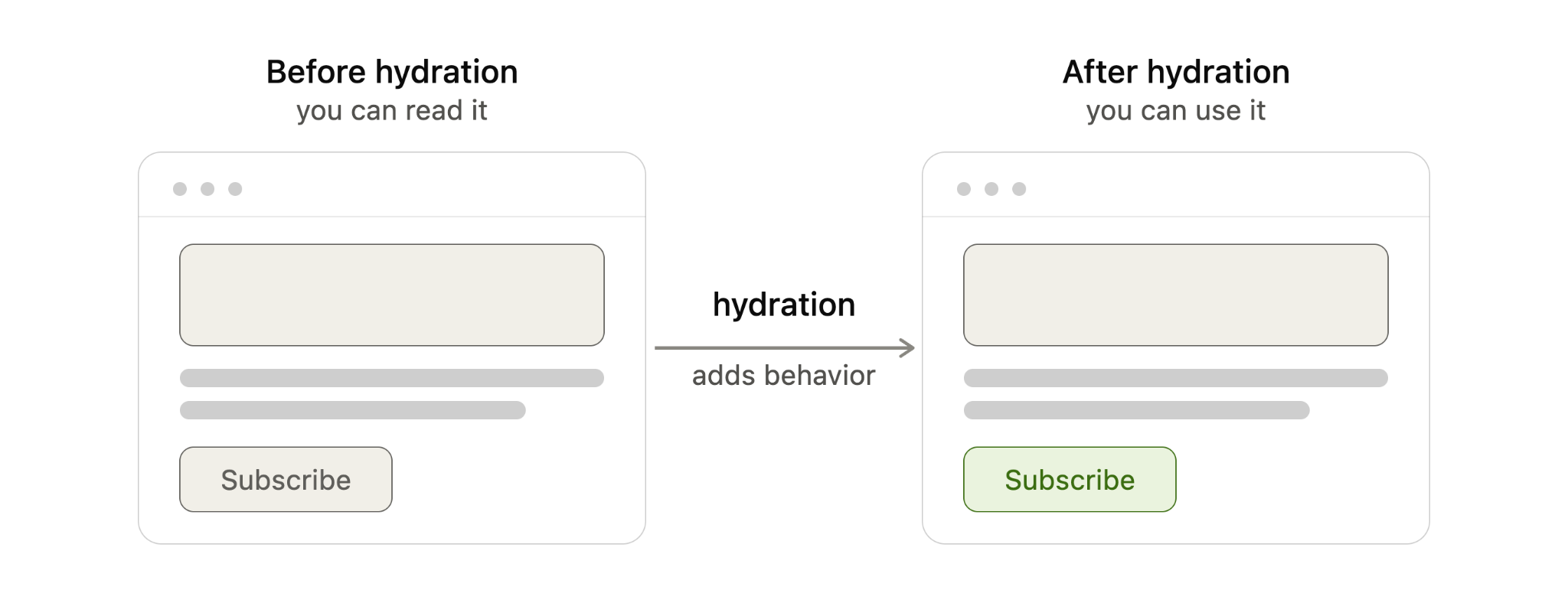
Hydration adds interactivity, not content
The most important distinction I keep in mind is this: hydration does not add the main content to the page. The text, images, and layout should already be present in the server-rendered HTML. Hydration only adds behavior by wiring that HTML to the JavaScript that responds to clicks, typing, taps, and other user actions.
A hydration timeline shows the gap between content appearing and a page becoming usable: HTML is visible first, but buttons only work after hydration completes.
Put simply, before hydration I can read the page. After hydration, I can use it.
I also avoid confusing hydration with the rendering pattern itself. Server-side rendering (SSR), static site generation (SSG), and client-side rendering (CSR) describe where and when the page is built. Hydration describes what happens after server-rendered or statically generated HTML reaches the browser and needs to become interactive.
From an SEO perspective, that distinction matters. When a page uses SSR or SSG correctly, the core content is already in the initial HTML. Google can discover and index that content from the HTML before depending on a JavaScript render step, which is generally more reliable than sending a mostly empty client-rendered shell.
When I see hydration become an SEO problem
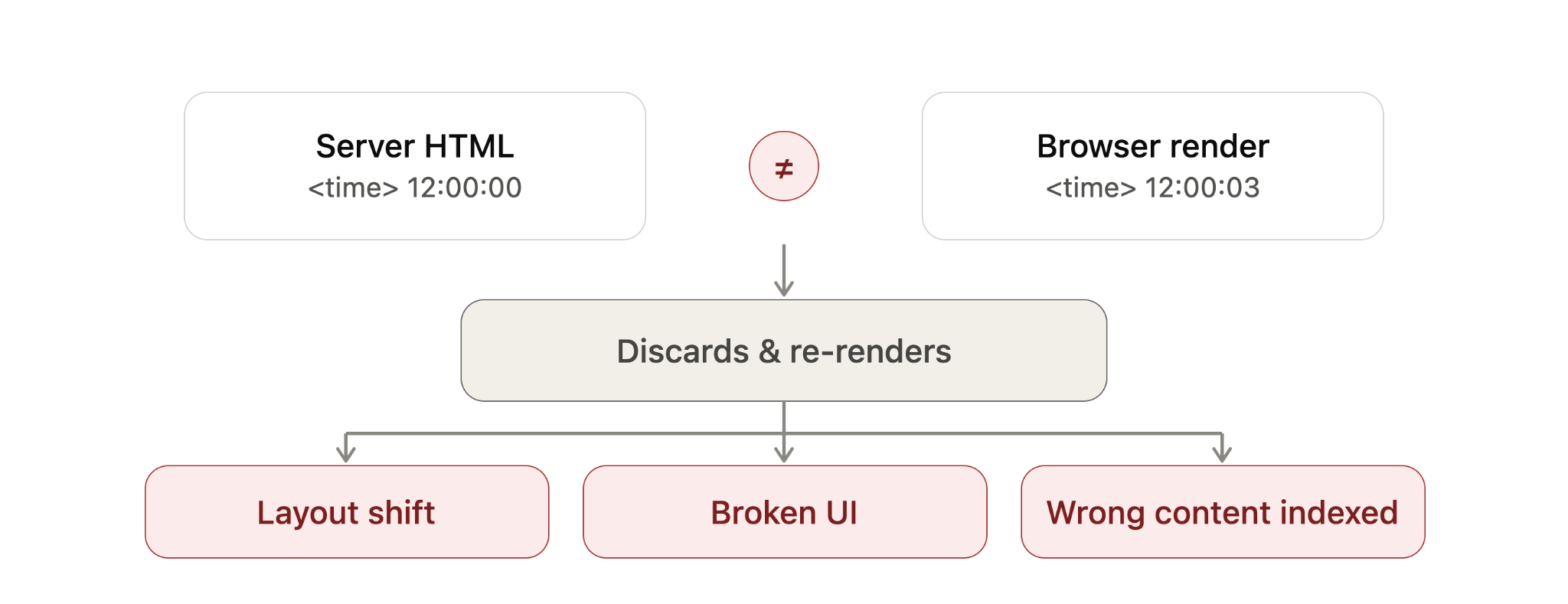
Most of the time, I do not treat hydration itself as an SEO problem. It becomes a problem when hydration breaks, usually because the HTML created on the server does not match what the framework expects to create in the browser.
That kind of mismatch can happen when content depends on browser-only APIs such as localStorage, when a value changes between server and client rendering such as new Date(), when a third-party script or browser extension changes the DOM before hydration finishes, or when invalid HTML causes the browser to rewrite the structure before the framework can attach to it.
Before hydration, a server-rendered page can be read but not used; after hydration, JavaScript adds behavior so elements like the Subscribe button respond.
When the two versions do not line up, the framework may throw away the mismatched section and re-render it in the browser. The exact behavior depends on the framework, but the SEO and performance risks are similar.
For example, if a <time> value is generated with new Date(), the server may output one value while the browser generates another. That mismatch can force a re-render, even though the page appeared to load correctly at first.
I worry about this because it can hurt the page in several ways. A re-render can make the page feel sluggish, which can affect Interaction to Next Paint (INP). It can shift the layout, which can affect Cumulative Layout Shift (CLS). It can also break user actions if event listeners fail to attach properly, leaving buttons, menus, or forms unresponsive.
In severe cases, Google may read the raw server HTML before JavaScript finishes rendering and then index content that visitors never actually see after the page re-renders. That is the scenario I want to avoid most: search engines and users experiencing different versions of the same page.
The fix is usually not an SEO trick. It is a development fix. I want the underlying mismatch removed by using valid HTML, avoiding browser-only logic during server rendering, stabilizing values that change between server and client, and controlling third-party scripts that alter the DOM too early.
When server HTML and browser-rendered content disagree, hydration may discard and rebuild the page, creating layout shifts, broken UI and potential SEO indexing problems.
How I spot hydration problems on a live site
Hydration errors are usually easier to catch in development than on a live site, but I still look for a few practical signals. I start with the browser’s Developer Tools console and check for hydration warnings, JavaScript errors, or framework-specific mismatch messages.
Then I watch the page load carefully. If content flickers, shifts, disappears, reappears, or stays unresponsive for longer than expected, I treat that as a sign worth investigating.
I also use Google Search Console’s URL Inspection tool on important templates to see how Google renders the page. For larger sites, I prefer crawling with JavaScript rendering enabled in tools like Screaming Frog or Sitebulb so I can compare rendered output against raw HTML at scale.
How I think about different hydration approaches
Modern frameworks handle hydration in different ways, and I think of those differences as a balance between performance, interactivity, and how much JavaScript must run in the browser.
Full hydration means the entire page hydrates in one pass. It is straightforward, but it usually ships the most JavaScript and asks the browser to do the most main-thread work. Next.js Pages Router is a common example of this model.
A glowing Google search bar cuts through streams of digital data, capturing the fast-moving world of search, shopping visibility, and SEO innovation.
Partial hydration hydrates only the interactive pieces, often called islands. Static sections remain plain HTML and do not need client-side JavaScript. Astro’s islands architecture is a well-known example of this approach.
Progressive hydration hydrates the page in pieces over time. A framework may hydrate sections as they scroll into view or as browser resources become available. Angular’s incremental hydration follows this general pattern.
React Server Components take a different path by letting some components render entirely on the server and ship no client-side JavaScript for those server-only parts. In those cases, there is nothing for the browser to hydrate for that portion of the page. Next.js App Router uses this model.
Resumability goes further by trying to skip hydration entirely. Instead of re-running components on load, the page resumes from the state the server already produced. Qwik is the main example here, although I still view it as newer and less battle-tested than some of the older patterns.
When I compare these techniques, I look at what hydrates, how much JavaScript ships, and how much work the browser must do. Full hydration touches the entire page and usually ships the most JavaScript. Partial hydration touches only interactive components and ships less. Progressive hydration spreads the work over time. React Server Components reduce hydration for server-only parts. Resumability aims to avoid hydration altogether.
What this means for my SEO work
I do not assume hydration is bad for SEO. In most cases, it is simply part of how modern server-rendered and statically generated sites become interactive.
What I do watch closely is whether the server HTML and the browser-rendered version agree. If they do, hydration is usually a performance and user experience consideration. If they do not, hydration can become a visibility problem, especially when Google indexes a version of the page that users never see.
Newer frameworks reduce some of this risk by shipping less JavaScript and doing less work in the browser, but they do not remove the need for careful implementation. For me, the practical takeaway is simple: make sure the important content is present in the initial HTML, keep server and client output consistent, and test how search engines actually render the page.
I’m seeing Google Search Console get a useful new reporting layer for social and video content through what Google calls platform properties. This gives me a way to understand how my content on Instagram, TikTok, X, and YouTube is performing in Google Search.
The big change is that I can now connect supported social or video accounts to Search Console and see how people find that content through Google. Instead of only analyzing websites I own or manage directly, I can begin looking at search visibility for content hosted on third-party platforms.
Google said this update makes it possible to track which search terms lead people to Instagram, TikTok, X, and YouTube content in Search, along with how audiences interact with those posts. I’ll be able to review this data inside the performance report, insights report, and achievements sections of Google Search Console.
A Google Search Console dropdown highlights the new platform property flow, with the rustybrick X profile appearing as a selectable property for reporting.
In the performance report, I can review total clicks, impressions, and other key metrics. I can also filter and sort the data to see which posts and queries are driving the most traffic, and if I want to analyze it somewhere else, I can export the data.
In the insights report, I can get a higher-level view of recent traffic trends, top-performing posts, and the ways people are discovering my account through Google Search.
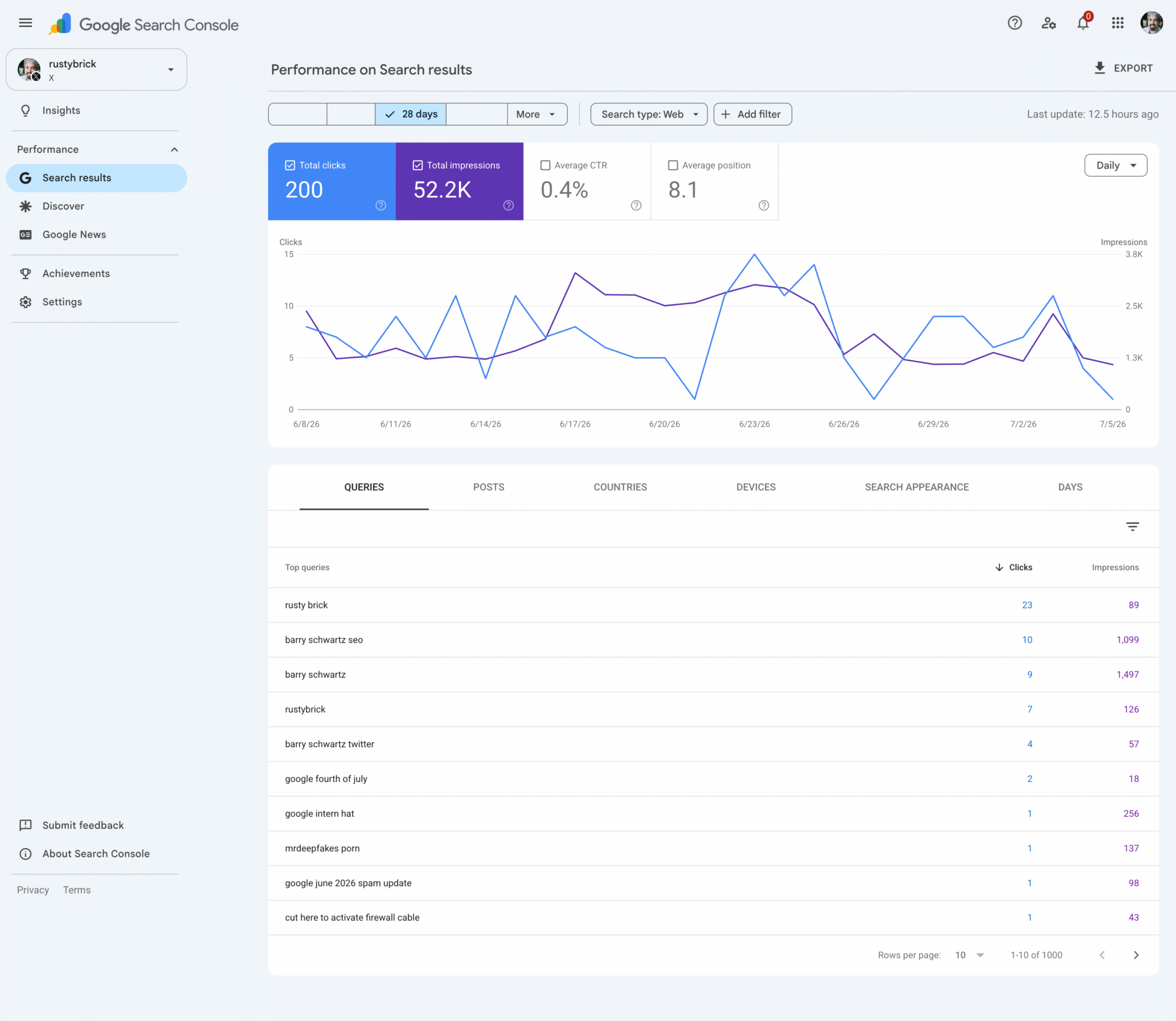
A Google Search Console platform property view shows how an X profile appears in Search, pairing 28-day click and impression trends with the queries driving visibility.
The achievements section adds another useful angle by helping me track growth milestones, such as reaching a new threshold for total clicks from Google Search over the last 28 days.
This feels similar to the social channel details that previously appeared in Search Console insights, but platform properties look like a more direct way to verify and analyze these accounts.
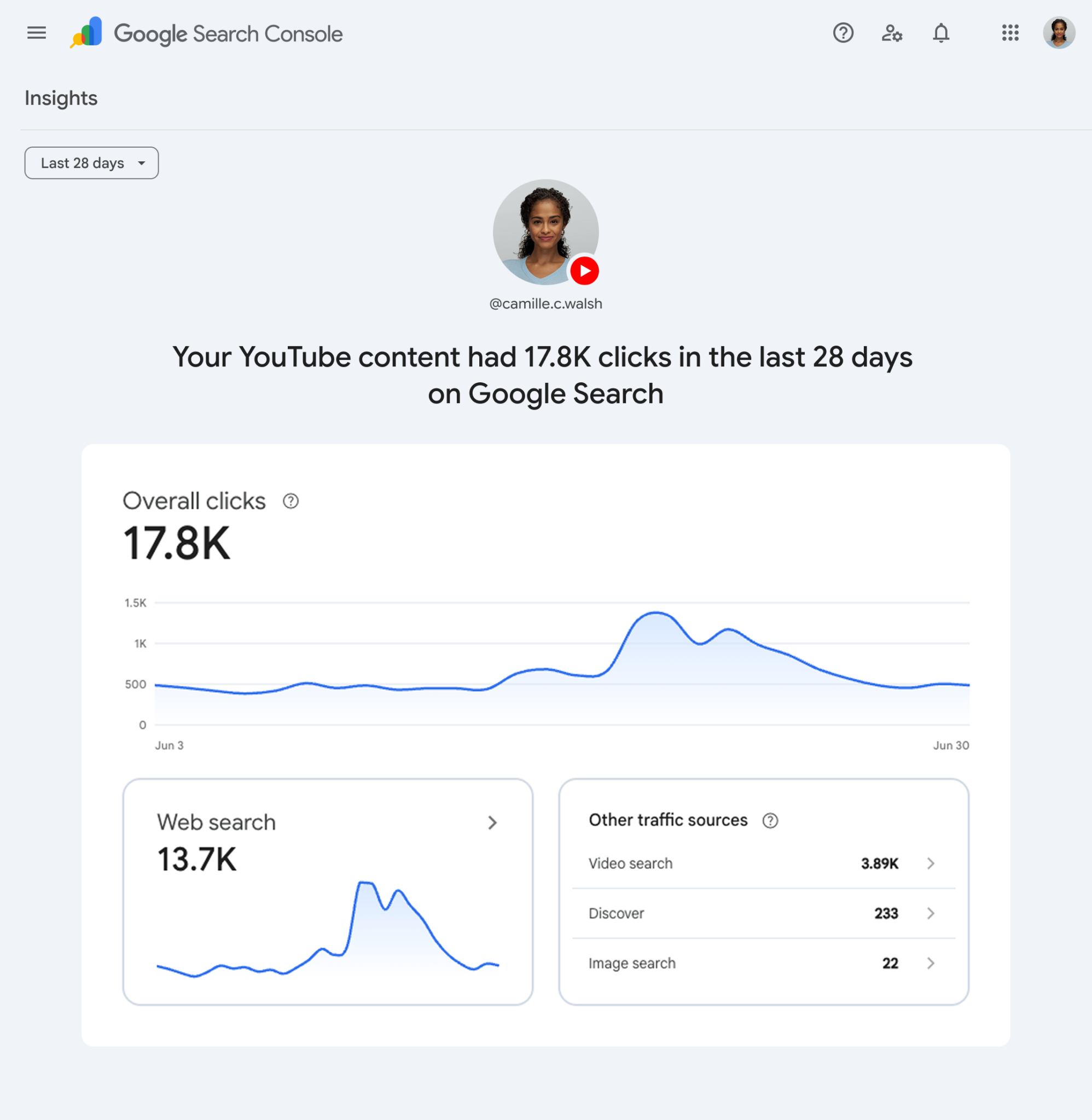
A Google Search Console Insights view highlights how YouTube posts are gaining visibility in Search, with 17.8K clicks and traffic broken down by web, video, Discover, and image search.
To set this up, I need to verify a platform property inside my Google Search Console account. I can start by opening Search Console, going to the Search Console verification page, or using the property selector dropdown anywhere in Search Console and choosing “Add property.”
From there, I select one of the currently supported platforms: Instagram, TikTok, X, or YouTube. Then I follow the onscreen verification steps to securely authorize the connection.
A glowing Google search bar cuts through streams of digital data, capturing the fast-moving world of search, shopping visibility, and SEO innovation.
Google said platform properties will roll out gradually over the coming weeks, so I may not see the option in my account right away. For setup details, Google points users to its help center documentation. The help document had briefly appeared a few weeks earlier before being removed, so this release makes the feature official.
What stands out to me is the access this gives marketers, creators, and SEOs. Google has not traditionally given us a clear way to see how our content performs on domains or properties we do not own. With platform properties, I can finally start seeing how my social and video content performs in Google Search, even when I do not have developer access to those platforms. That opens up a much better view of search-driven visibility beyond my own website.
I can finally say the page indexing report inside Google Search Console has been updated after a frustrating three-week delay. Instead of showing data stuck on June 11, 2026, the report is now displaying data through June 29, 2026.
The delay. I previously noted that the page indexing report had been frozen at June 11, which made it much harder to understand what Google was seeing across a site.
Now, as of Friday, July 3, the report is showing much fresher data, with updates running through June 29.
Page indexing report. I use this report to see which pages Google can find and index on a website. It also helps surface indexing issues Google may have run into while crawling the site.
I can access the report directly in Search Console over here, or by opening the Indexing section and selecting Pages.
The report shows indexed pages in green and not indexed pages in gray. I can also overlay impressions on the chart, then review the listed reasons explaining why certain pages on a website are not being indexed.
For more details on how the page indexing report works, I would refer to Google’s help document.
Why I care. If I was trying to diagnose why Google had not indexed specific pages over the past couple of weeks, the delayed report left me with limited visibility.
Now that the data has finally been refreshed through June 29, I can dig back into the indexing report, review the latest issues, and decide what needs attention next.
I see generative AI and automation creating both excitement and anxiety across the SEO industry. With 87% of Americans reading AI summaries, I believe any SEO team that is not adapting its toolset is already starting to fall behind.
When I move away from rigid enterprise tools and toward agile, AI-driven workflows, I can work faster, spot new search signals earlier, and show clients or internal stakeholders that I understand where search is heading.
In this guide, I’ll walk through what the old SEO stack looked like, what I now add to it, and how I combine both approaches without abandoning the fundamentals that still matter.
Here’s what an old SEO stack looks like
I still believe traditional SEO practices matter because generative AI search experiences continue to depend on core search ranking systems, quality systems, and the broader signals search engines have used for years.
That said, the classic SEO stack was built for a simpler search environment. It usually centered on rank tracking, keyword research, and technical site audits.
Rank trackers
For a long time, I treated keyword rankings as the heartbeat of an SEO campaign. I would add target keywords, monitor SERP positions, and expect higher rankings to translate into more search traffic. But rankings have become far more fragmented.
Now I need to pay attention to AI Overviews, local packs, shopping carousels, and many other search features that can change the value of a ranking completely.
A third-place local pack ranking, for example, may drive two or three times more traffic than a number one ranking in an AI Overview. That makes old-school rank tracking useful, but incomplete.
Keyword tools
Keyword tools still help me understand what people search for, how competitive a topic might be, and which queries match specific user intent. In the past, that information often felt close to a crystal ball.
I would choose keywords based on difficulty, search volume, intent, and other factors. The better the data, the easier it was to shape a campaign around the right opportunities.
The problem is that search volume has always looked backward. A keyword may have shown 10,000 monthly searches last month, but that does not mean it will perform the same way this month. Demand can rise, fall, or shift quickly.
Today, the bigger issue is opportunity loss. A keyword that generated tens of thousands of clicks in 2022 may now be answered directly inside an AI Overview. Even when search volume has not dropped, zero-click behavior can reduce the traffic I can realistically capture.
Site audit tools
I still rely on site audit tools because crawlers still crawl websites, interpret content, and surface technical issues. I need to know whether search engines can access, understand, and navigate the pages I care about.
Audit tools help me find broken links, redirect problems, missing metadata, slow pages, thin content, and other technical issues that can hold a site back.
But I do not expect crawl audits alone to tell me whether my content will appear in AI-driven search experiences. Technical health is necessary, but it is no longer the full picture.
Signals such as brand mentions can influence whether a site is included in LLM outputs from tools like ChatGPT, Claude, and Gemini. Many older site audit tools were not built to track those signals.
That is why I still keep parts of the old stack, but I now add tools and workflows that help me understand AI visibility, brand presence, and faster data-driven decision-making.
Here’s what a new SEO stack looks like
If I am optimizing only for Google’s traditional results, I am missing where search behavior is moving. Between the first and second half of 2025, LLM referral traffic grew by 80%. Conversion rates reached 18%, even though LLM referrals still represented 2% or less of total traffic in the dataset.
That tells me the channel is still small, but meaningful. Now is the time to build a stack that helps me understand, measure, and improve performance across AI-driven discovery.
LLMs
I want my site to appear in LLM responses, but I also use LLMs to strengthen my SEO process. These tools can support analysis, content review, competitor research, metadata refinement, and structured data work.
For example, I can connect ChatGPT with Google Search Console to automate SEO analysis, use Claude to refine copy and conduct content audits, or use Gemini to generate schema markup and compare competitor pages against my own.
I use the LLM that best fits the task, but I keep human oversight in place. These tools help me improve speed and performance; they do not replace judgment, strategy, or editorial review.
The biggest shift is speed. Large datasets that once took hours, days, or weeks to review can now be explored in minutes when I use LLMs carefully and integrate them into a repeatable workflow.
APIs
The old workflow often meant logging into dashboards, exporting CSV files, and cleaning everything in Excel. I still do that when needed, but APIs let me pull data directly from platforms like Google Search Console and Google Analytics.
APIs can sound intimidating, but LLMs make the learning curve easier. I can use them to help with authentication, JSON parsing, and the basic structure of repeatable data workflows.
Once I can connect to APIs, I can stop waiting on manual exports and start building faster reporting, monitoring, and analysis systems around the data I already use.
Lightweight scripts
Python scripts are now within reach for many SEOs, especially with tools like Claude Code and similar coding support inside ChatGPT or Gemini. I do not need to be a full-time developer to automate repetitive SEO work.
I can create scripts that pull top pages from Google Search Console, compare title tags against character limits, flag 30-day performance changes, or generate a clean CSV output for review.
Instead of waiting for a vendor to add the exact feature I need, I can build a small script that removes a bottleneck. A hundred-line script can replace hours of manual work without requiring another SaaS license.
I also like that scripts make the logic visible. If I hand the workflow to another teammate, they can inspect what the script does and understand how the output was created.
Notebooks and local workflows
SEO teams usually have data scattered across shared folders, Google Sheets, Notion docs, monthly CSV dumps, and long-running audit trackers. I have seen how quickly that fragmentation slows decisions down.
Notebooks and local workflows help me turn scattered files into a working system. A script can pull the data, an API can surface the signal, and an LLM can help interpret the results before the output lands in a notebook or spreadsheet.
The value is consistency. I get cleaner data formats, shared access, and documented logic instead of rebuilding the same process every time someone needs a report or audit update.
As search optimization becomes more connected to generative AI, I need workflows that scale. Local workflows help me keep data consistent while giving the team a faster way to act on what we find.
Creating hybrid workflows that mix old and new SEO stacks
I do not think the old SEO stack is obsolete. I also do not think the new tools replace everything. The strongest approach is a hybrid workflow that keeps proven SEO fundamentals while adding AI, APIs, scripts, and notebooks where they create real leverage.
Tool + custom script + AI layer
To build a practical hybrid workflow, I would start with a familiar audit tool such as Screaming Frog, then run a Python script that joins the crawl data with Google Search Console data.
From there, I could flag pages with high impressions and low clicks, send those pages to an LLM for title and intent analysis, place the output into a notebook or spreadsheet for editors, and turn approved recommendations into change logs.
Work like this used to take weeks, so many teams pushed it aside. At enterprise scale, the amount of data could easily become overwhelming. With a hybrid SEO stack, I can complete larger projects in a fraction of the time.
For me, the goal is not to chase every new tool. The goal is to build a more agile SEO stack that can handle today’s massive datasets, identify AI search signals, and help teams move faster without losing the core SEO basics.
When one person is responsible for paid campaigns, landing pages, reporting, email, social posts, sales requests, and last-minute website updates, I know exactly what usually happens to SEO: it waits.
I have seen this play out on small marketing teams over and over. Everyone knows SEO can bring in qualified demand, reduce dependence on paid media, and support buyers long before they fill out a form. The problem is that SEO rarely feels urgent until traffic drops, rankings slide, or something breaks.
That is why I like a simple 120-minute weekly SEO workflow. It gives me a practical way to protect visibility, find opportunities, improve high-value pages, and turn search data into business impact without pretending I have unlimited time.
Why I keep SEO simple on lean teams
When SEO falls behind, I rarely see effort as the real problem. The bigger issue is usually competing priorities and a lack of clear prioritization.
On a lean team, SEO is one tab among 20. The person responsible for organic growth may also be sending newsletters, briefing designers, updating landing pages, and pulling the report leadership wants by Friday.
Then the advice starts piling up: fix technical issues, publish more, build topical authority, refresh old posts, add schema, improve Core Web Vitals, build links, optimize for AI search, and keep going. Most of that advice may be valid, but no small team can do all of it in one week.
The question I come back to is not, “What could I do?” It is, “What is the highest-leverage thing I can actually finish this week?”
I also try to avoid the reporting trap. It is easy to spend an entire SEO block looking at rankings, traffic, impressions, clicks, CTR, conversions, competitor movement, and keyword shifts. Then the hour ends and nothing ships.
For a small team, reporting has to be short enough to leave room for action. The goal is to decide what to fix next, not to build another dashboard.
Why 120 minutes can be enough
I do not try to run a lean team like an enterprise SEO department. If I audit everything, track everything, collect endless keywords, and ship nothing, I have not improved organic growth.
The point of time-boxing is to force a decision. Every weekly session should end with one or two changes that improve visibility, traffic quality, or conversion potential.
In my 120-minute workflow, I focus on four outcomes: finding what is already working, fixing what is blocking performance, improving the pages closest to revenue, and turning search data into next week’s actions.
I am not trying to “do SEO” for two hours. I am using two focused hours to make decisions and ship work that has a realistic chance of moving the business forward.
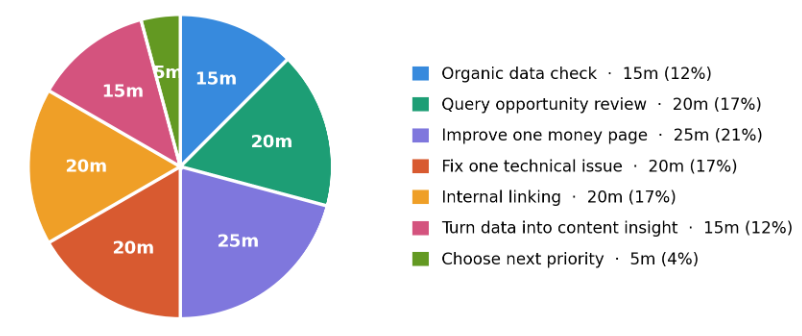
My 120-minute weekly SEO workflow
0-15 minutes: Check organic data
I start with a pulse check so I can catch problems before they turn into bigger performance drops.
I look at Google Search Console clicks, impressions, CTR, and average position. I also check organic conversions or assisted conversions in GA4, top landing pages gaining or losing traffic, branded versus non-branded movement, and any indexing, crawling, or manual action warnings.
What I do not do is turn this into a full reporting session. This is not a board deck. I only want to answer one question: is organic visibility moving in a direction that needs action?
My output is a short weekly note: the biggest organic win, the biggest organic concern, one page or query to investigate, and one action to take this week.
15-35 minutes: Find query opportunities
Next, I look for the easiest opportunities in Google Search Console. The richest ones are often queries ranking in positions 4-15 with real impressions. Those pages are already close, and a focused improvement can help them move.
I also watch for pages with strong impressions but weak CTR, queries climbing week over week, and rankings where the current page only partially matches search intent.
I resist the urge to build a long keyword list. Instead, I pick three things: one page to improve, one query to answer better, and one title or meta description to test.
For example, when I reviewed search data for a local accounting client, several queries kept appearing around tax help for freelancers, small-business tax mistakes, and the difference between an accountant and a bookkeeper.
The obvious reaction would have been to write three new articles. Instead, I rewrote one service page around freelancers, added a short FAQ based on those queries, and linked it to an existing bookkeeping article. One page served three search intents, which was far more useful than three unfinished drafts.
35-60 minutes: Improve one money page
This is the most important part of the workflow. I define a money page as any page close to revenue, pipeline, bookings, sales, demos, or consultations.
Money pages can include product pages, service pages, category pages, comparison pages, demo pages, consultation pages, pricing pages, and high-intent landing pages.
My weekly goal is not to optimize the entire website. It is to improve one important page in one meaningful way.
I ask what the buyer needs to believe before converting, what objection is missing, what proof would reduce hesitation, what comparison the buyer already has in mind, and what query the page almost satisfies but does not fully answer.
A meaningful update might be adding three FAQs based on real queries, improving the H1 and introduction, adding comparison language, including proof points, linking to a case study, clarifying who the offer is for, improving the CTA, or adding a short “how it works” section.
That is SEO work, but it is also conversion work. The best page improvements usually help both search engines and buyers understand the value faster.
60-80 minutes: Fix one technical or indexing issue
Technical SEO can take over the full two hours if I let it, so I stay focused on impact.
The question I ask is simple: what could stop an important page from being discovered, understood, indexed, or trusted?
That usually points me toward issues like priority pages not being indexed, broken internal links, redirect chains, duplicate or missing titles on key pages, incorrect canonicals, schema errors on important templates, or valuable pages buried too deep in the site.
I want one of three outcomes from this block: a fix shipped, an issue assigned, or a clear developer brief.
For example, if I find that ecommerce collection pages are not indexed because of incorrect canonical tags, documenting the affected URLs and writing a clear developer brief may be more valuable than publishing another generic article.
80-100 minutes: Improve internal links
Internal linking is one of the fastest SEO wins I can create because it does not require new content.
It helps search engines understand which pages matter, helps users continue their journey, and helps informational content support commercial outcomes.
Each week, I look for links from high-traffic articles to money pages, links from product or service pages to supporting guides, links from older articles to newer strategic content, and opportunities to use clearer anchor text.
If an article ranks for “how to choose accounting software,” I do not want it to be a dead end. I want it to guide readers toward a comparison guide, a relevant case study, and a demo or pricing page. The traffic is already there, so I try to make it more useful.
100-115 minutes: Turn one search insight into messaging
I do not want search data to stay trapped in an SEO silo. The best query I find each week is often a useful signal for the rest of marketing because it shows the language buyers actually use.
A query like “best CRM for small agencies” can become a comparison section on a landing page, a LinkedIn post, a sales email angle, and a paid search ad group.
A query like “is [product] worth it” can become a proof section, a pricing explainer, a “who this is not for” paragraph, or a ready-made answer to a sales objection.
When I share one search insight each week, SEO becomes more than a channel. It becomes a source of customer intelligence.
115-120 minutes: Choose next week’s priority
I end with a decision, not a long list. I choose one clear priority for next week based on business impact, search demand, ease of execution, current performance gap, and proximity to revenue.
The template I use is: “Next week, my highest-leverage SEO action is [X] because [Y].”
For example: “Next week, my highest-leverage SEO action is updating the pricing page because it gets non-branded traffic, supports demo requests, and does not answer implementation cost questions.”
That is how I make SEO operational. The work becomes specific, owned, and easier to repeat.
A sample month for the workflow
To keep the workflow balanced, I like rotating the emphasis each week.
In week one, I focus on a revenue page. I update copy, add FAQs, improve internal links, check indexing and schema, and sharpen the CTA.
In week two, I refresh existing content. I choose one article with impressions but weak clicks or rankings, improve the title, add missing sections, update examples, link to money pages, and better match search intent.
In week three, I handle technical cleanup. I focus on one crawl, indexing, or template issue, such as broken links, duplicate titles, sitemap problems, or a developer brief for a higher-impact fix.
In week four, I turn SEO data into broader marketing assets. That may mean one landing page insight, one sales objection, one content brief, one paid or social angle, or one FAQ or comparison section.
This rotation keeps me from spending every week in dashboards, technical audits, or new content production while ignoring the pages that already have potential.
What I stop doing
Most small teams do not have a doing problem. They have a stopping problem.
I stop chasing every low-impact technical warning. I stop creating content just because a tool found a keyword. I stop publishing AI-assisted articles at scale without a strategy. I stop rewriting pages without a hypothesis. I stop optimizing low-value pages before revenue pages. And I stop treating rankings as the only score that matters.
Before I create new content, I review the pages I already have. The highest returns often come from pages that already rank on Page 2, already get impressions, sit close to revenue, and are one focused update away from doing more.
My test for any task is simple: if I cannot connect it to qualified traffic, conversions, discoverability, buyer education, or trust, it does not belong in the 120 minutes.
How I make it work without a dedicated SEO person
This workflow does not require a full SEO department. It requires one owner, a weekly rhythm, and a bias toward shipping.
A marketing manager can own prioritization and the weekly SEO note. A content marketer can update copy, FAQs, and page sections. A developer or web support partner can handle technical fixes. A paid search manager can share query and conversion insights. A founder or sales team can contribute objections and buyer language.
The owner matters most. Someone has to protect the 120 minutes, choose the priority, and make sure the session ends with an action.
Without ownership, SEO becomes everyone’s job and nobody’s job.
How I use AI to save time
I use AI to shorten repetitive SEO work, not to hand over strategy.
That might mean using a focused workflow to identify queries in positions 4-15, pages with high impressions and low CTR, search queries that should become FAQs, internal linking opportunities, or technical issues that should become developer briefs.
For agencies, client-specific assistants can reduce context switching by remembering each client’s services, priority pages, competitors, and customer objections.
The most useful AI workflows are narrow: a GSC opportunity analyzer, a money page refresh assistant, an internal linking assistant, a technical SEO brief generator, or an SEO reporting summarizer.
I do not want one generic SEO assistant trying to do everything. I want small workflows that help me move faster from data to decisions.
Consistency is the advantage
Small teams win SEO by doing the highest-leverage things repeatedly.
A 120-minute weekly SEO workflow will not replace a full strategy. It will not solve every technical issue, build every content asset, or uncover every opportunity.
But it gives me a practical way to protect visibility, learn from search data, improve revenue pages, and keep organic growth moving.
The mindset is simple: less auditing, more shipping, more buyer intent, less busywork, and more business impact.
LLMs have changed how people search and how Google responds. The SERP has not been limited to 10 blue links for a long time, but traditional search has usually centered on one core intent: the thing someone is trying to find.
Now, AI Overviews can create a full answer directly in the SERP. They do more than respond to the original query. They also bring in related terms, contextual refinements, and supporting information that help searchers make better decisions.
That is why I pay close attention to Google query expansion. When I understand how Google connects related searches, I can find visibility opportunities that competitors may miss.
What is Google query expansion?
I think of Google query expansion as Google broadening a searcher’s query so it can return more accurate results, especially for long-tail searches that might otherwise produce weak or limited results.
This can happen through synonyms. For example, Google may connect “budget” with “affordable” when the intent is similar.
It can also happen through intent expansion. Google may understand what my audience means even when they do not type the exact words I expected.
Related topic expansion matters too. Google can use similar searches and connected topics to surface content that supports the searcher’s broader need.
I do not use this as an excuse to stuff keywords into a page. Instead, I use query expansion as a research signal. When I see related searches that make sense, I can add useful supporting information and help my content rank for a wider range of relevant queries.
Here is a simple example. If I have an article about backyard chicken care and someone searches “What’s the average lifespan of a chicken?”, my page might appear even if I never used the word “lifespan.”
In that case, Google has decided the article is semantically relevant. Once I know Google has made that connection, I can add a helpful section about chicken lifespan. That gives the page a stronger chance to rank for the term and attract more traffic.
It can also improve the odds that my content appears in relevant AI Overviews.
The difference between Google query expansion and query fan-outs
Google query expansion and query fan-outs are related, but I do not treat them as the same thing.
Query expansion is part of traditional search. Google broadens a query with synonyms, related terms, and intent signals before results are generated. Because of that, my content can rank for searches I did not directly target.
Query fan-outs are part of AI Mode. They break a query into multiple related subqueries while the AI response is being generated. Because of that, my content can be retrieved as a source for an AI-generated answer.
So why does traditional query expansion still matter in a search world shaped by LLMs and AI Overviews?
Because the same semantic relationships that help Google expand a query can also influence which content AI systems retrieve during query fan-outs.
How I find query expansion opportunities
The first place I look is Google Search Console. It is one of the clearest ways to confirm whether query expansion is already happening for my site and my content.
My workflow is straightforward. I go to Performance > Search results, filter by a specific page, pull the full query list, and sort by impressions.
From there, I look for queries I never intentionally targeted. I pay attention to synonyms with meaningful impressions, question-based searches that may be especially useful for AI visibility, and broader keywords that are not currently addressed on the page.
I do not assume every discovered query deserves a content update. Sometimes a page appears for terms that are not truly relevant. When that happens, I audit the page and make sure the content is not drifting into unrelated topics that fail to match the promise of the SERP result.
How I plan better content with query expansion
Once I understand which expanded queries Google is connecting to my content, I use that data to strengthen the page instead of chasing isolated keywords.
I write for topic coverage
For a long time, strong SEO has been less about exact keywords and more about semantic relevance. I try to build coverage around subtopics, related questions, and adjacent ideas because that gives Google more context than a page built around one keyword alone.
I answer questions adjacent to the main topic
For example, if I am working on content for a company that sells chicken feed, I would not only explain the feed itself. I would also consider why the right balance matters and how the right feed can support chicken health.
I can find those adjacent questions by reviewing query expansion data in Google Search Console, checking tools like Ahrefs, and studying the SERP to see what supporting information Google is already surfacing for the topic.
I use expansion data to find content gaps
If Google Search Console shows that Google is pulling my page for a query I have not planned for, and that query is genuinely relevant, I treat it as a signal that the page may need more complete coverage.
Sometimes query expansion data includes odd or unrelated searches. I ignore those. But when I find adjacent queries that clearly strengthen the topic, I add them to the page in a useful and natural way.
I also revisit content regularly, usually at least once a quarter. New queries can appear, while others fade away. Since I am already keeping content fresh for the SERP, query expansion gives me another practical way to make each topic stronger.
How I use query expansion to improve AI Overviews visibility
AI Overviews often pull from ranking pages on a topic to build a more complete answer. Those answers can include semantic connections and supporting subtopics, not just the exact phrase someone searched.
That is why I cross-reference my query expansion data with the main keyword in the SERP. If an AI Overview includes supporting topics that are relevant to my page, I consider adding those topics to the content.
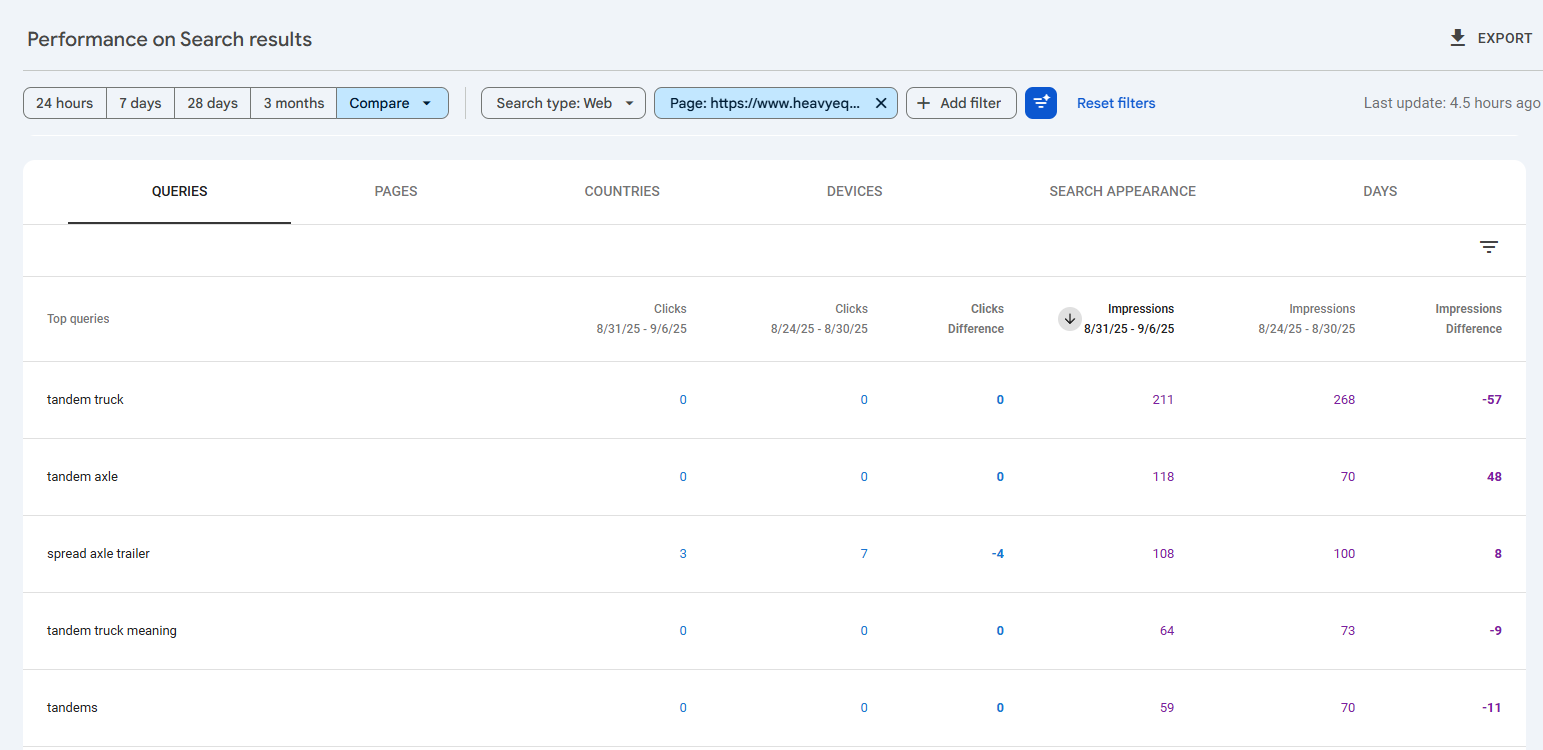
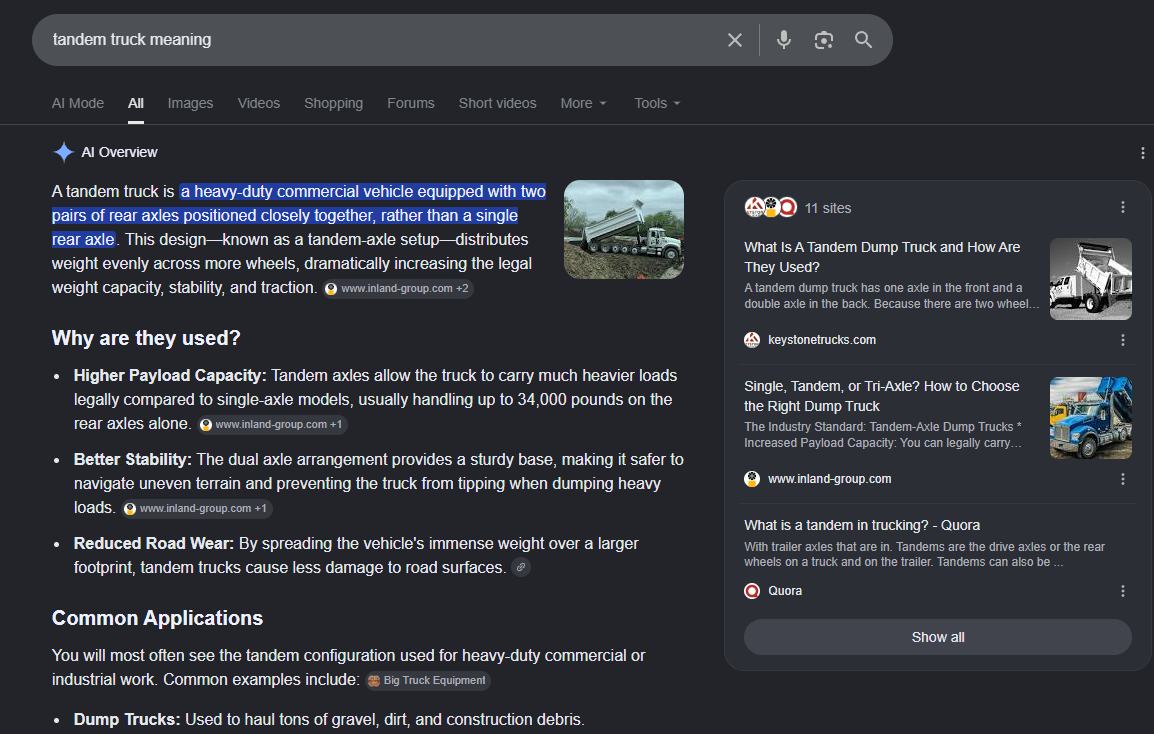
For example, I followed this process for a blog post titled “Tandem vs. Spread Axles in Trucking.” After filtering by impressions, I found that the page appeared for “tandem truck meaning,” even though that exact phrase was not specifically included in the content.
The page ranked first, but it was not included in the AI Overview for that specific query. That told me there was an opportunity.
Because the page already ranked well, I could use the expanded query and the supporting information in the SERP to create a section that better addressed both the query expansion term and the query fan-out patterns behind the AI Overview.
That is the value of this process. Query expansions can reveal supporting topics that strengthen traditional search visibility and improve the chances of being included in AI-driven results.
How query expansion helps my SEO strategy evolve
I use query expansion as a practical way to identify supporting topics and expand content coverage across search experiences.
As clicks become harder to earn, I want my content to appear across more relevant search moments. Broader visibility can strengthen brand awareness, support AI visibility, and keep my content in front of the people most likely to need it.
I am seeing Google Search Console’s page indexing report running more than two weeks behind, with the latest visible timestamp still showing June 11, 2026. That means I cannot get a fresh view of page indexing data for the pages on my site right now.
When I check the Google Search Console page indexing report, I would expect to see that June 11 date instead of a more recent update. The delay is inconvenient, especially when I am trying to understand whether Google has recently found, crawled, or indexed important pages.
This report matters because it shows me which pages Google can find and index on a website. It also helps me spot indexing problems Google may have encountered while crawling the site.
I can access the report in Search Console over here, or I can open Search Console, go to the Indexing section, and then select Pages.
Inside the report, I usually see a chart with indexed pages in green and not indexed pages in gray. I can also overlay impressions on the chart, which makes it easier to connect indexing patterns with search visibility.
Below that chart, Google lists the reasons pages on the website are not being indexed. That section is often where I look first when I need to understand whether the issue is related to crawling, duplication, redirects, noindex signals, canonical choices, or another indexing reason.
For more details about how the page indexing report works, I can refer to Google’s help document.
Why I care: if I am trying to debug why Google has not indexed specific pages over the past couple of weeks, this delay leaves me with limited visibility. Until Google updates the report again, I would need to rely on my own SEO analysis or use the URL inspection tool to investigate indexing issues one page at a time.
The delay is frustrating, but I do not see it as especially uncommon. Search Console reports can lag from time to time, so for now I would treat the page indexing report as stale and avoid making major conclusions from that delayed data alone.
When I heard that Google had added a new help document to its search developer documentation, I knew I needed to dive in. This new document, “Google Search’s guidance on using third-party SEO tools, services, and advice,” provides updated insights into the world of SEO, especially revolving around the hot topic of generative AI optimization.
Google also revamped its “Do you need an SEO?” guide, adding fresh content around generative AI topics. The intent behind these updates, as stated by Google, is to highlight what to consider when evaluating third-party tools and to simplify existing documentation. They want us to be cautious about trusting these tools and advice without proper verification.
Reading through Google’s new guidance, I found some valuable advice on thoughtfully evaluating third-party SEO services. Here’s how they suggest approaching it:
Evaluate external SEO advice against Google’s official guidelines, think critically about third-party tools, and always verify the claims made by these services.
Evaluate and verify external SEO advice against official Google guidelines
Think critically about using third-party SEO tools and services
Assisting in sitemap generation
Establishing indexing directives
Offering to generate “SEO-optimized” content for you
Providing advice to improve the ranking of existing content
Promising improvements for AI experiences and search formats (“AEO” or “GEO” tools)
While Google doesn’t endorse any third-party tools, they emphasized using Google Search Console for credible data directly from Google Search. We need to be wary of tools claiming to guarantee success since they lack access to Google’s internal ranking data.
With the updated “Do you need an SEO?” document, Google has also covered topics like Optimizing for generative AI. It includes essential reminders that if an SEO uses a third-party tool, one should not assume it’s approved by Google, and during audits, access to Search Console should be limited initially.
In essence, before making any site changes based on third-party audits, it’s crucial to cross-reference their advice with Google’s official resources, especially when it comes to AI optimization strategies.
If your SEO offers an audit, scrutinize what’s involved and avoid granting write access to Search Console at first.
Understanding these updates helps us not only in improving our own SEO strategies but also in promoting ethical and effective use of tools.
The document updates come as a reminder for us to regularly check Google’s official documentation. Staying informed about new guidelines ensures that we’re always on the right path in our SEO journey.