In Part 1, I looked at the third-party citation signals that matter so much for AI visibility. In Part 2, I made the case for publishing original data, because it is the strongest single predictor of page originality, and the barrier to earning visibility and authority through this approach is still surprisingly low.
Now I have more evidence for why proprietary data should be part of content creation.
Publishing a number matters, but the number itself is not always what gets cited. I looked at Gauge’s citation data to understand what AI systems actually reward when brands publish first-party data. The answer is narrower, sharper, and more useful than simply saying, “original data wins.” Original data does win, but only when it is packaged in the right way.
The format AI rewards most is the benchmark that answers a clear commercial question: which option is best?
First-party research is scarce and punches above its weight
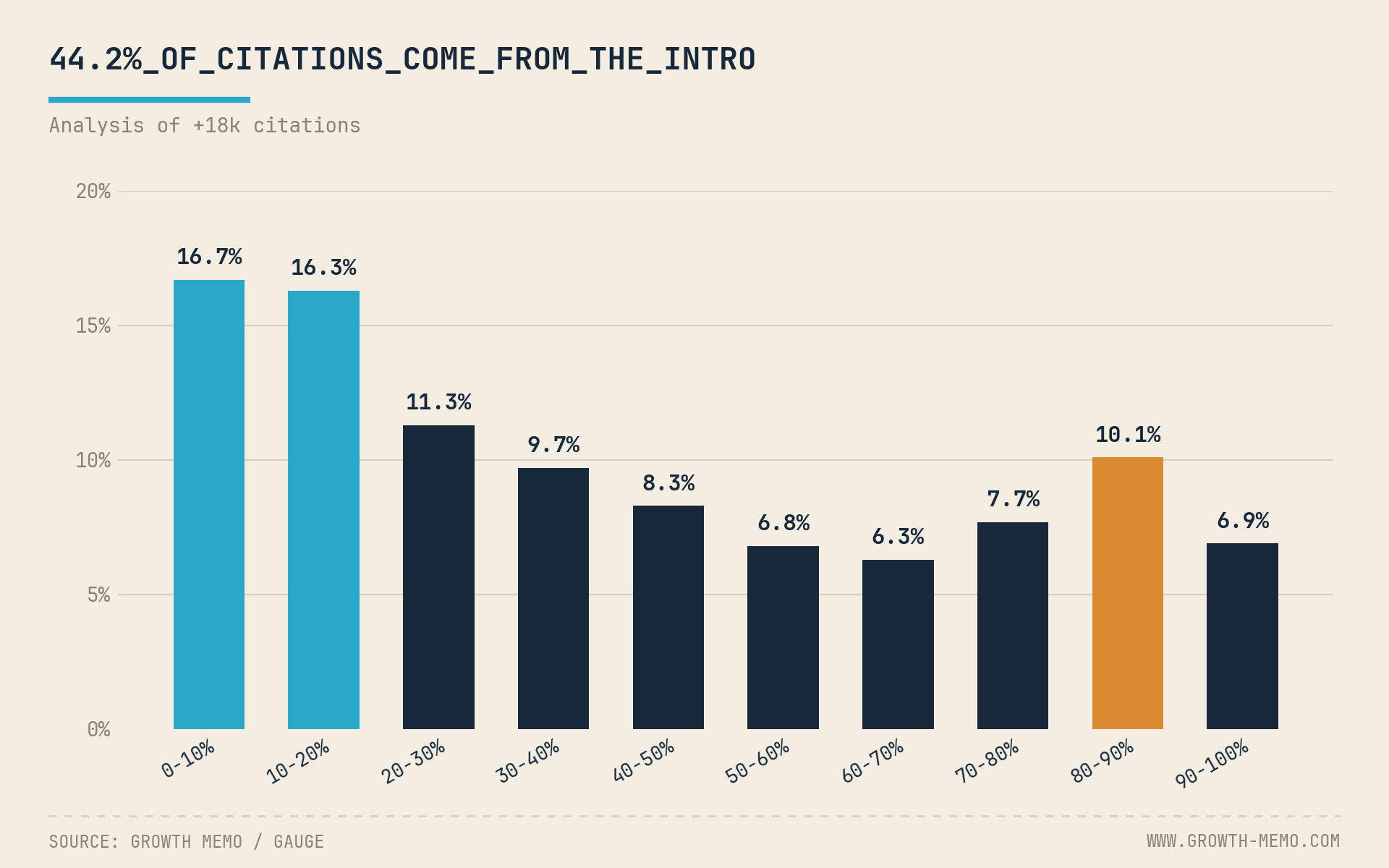
I worked from Gauge’s cited-URL set: 301 live pages cited by AI systems across 316 unique prompts and 7 verticals. Together, those pages carried 1,075 citations.
After auditing the URLs, I found that only 8 of the 301 pages qualified as primary research. To count, the page had to include the original source of the data and its methodology, rather than simply writing about someone else’s numbers.
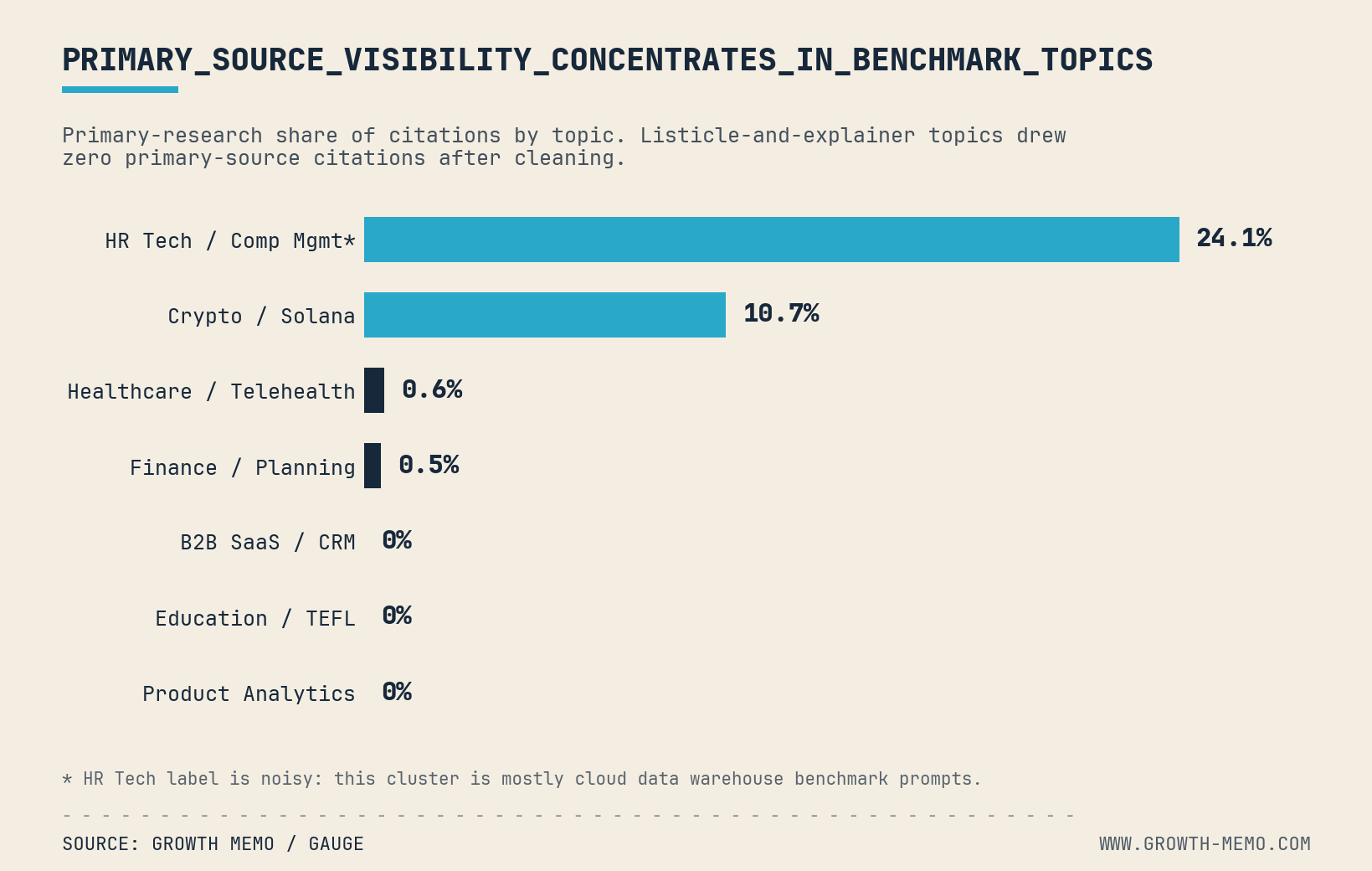
That means primary research made up just 2.7% of the cited set. But those same 8 pages earned 90 of the 1,075 citations, or 8.4% of the total citation volume. In other words, first-party research appeared rarely, but when it appeared, it over-indexed by roughly 3x on citation share.
The cleaner way I see this is citation density.
Primary research averaged 11.3 citations per page. Everything else averaged 3.4 citations per page. A primary-research page was 3.3x as citation-dense as a non-primary page.
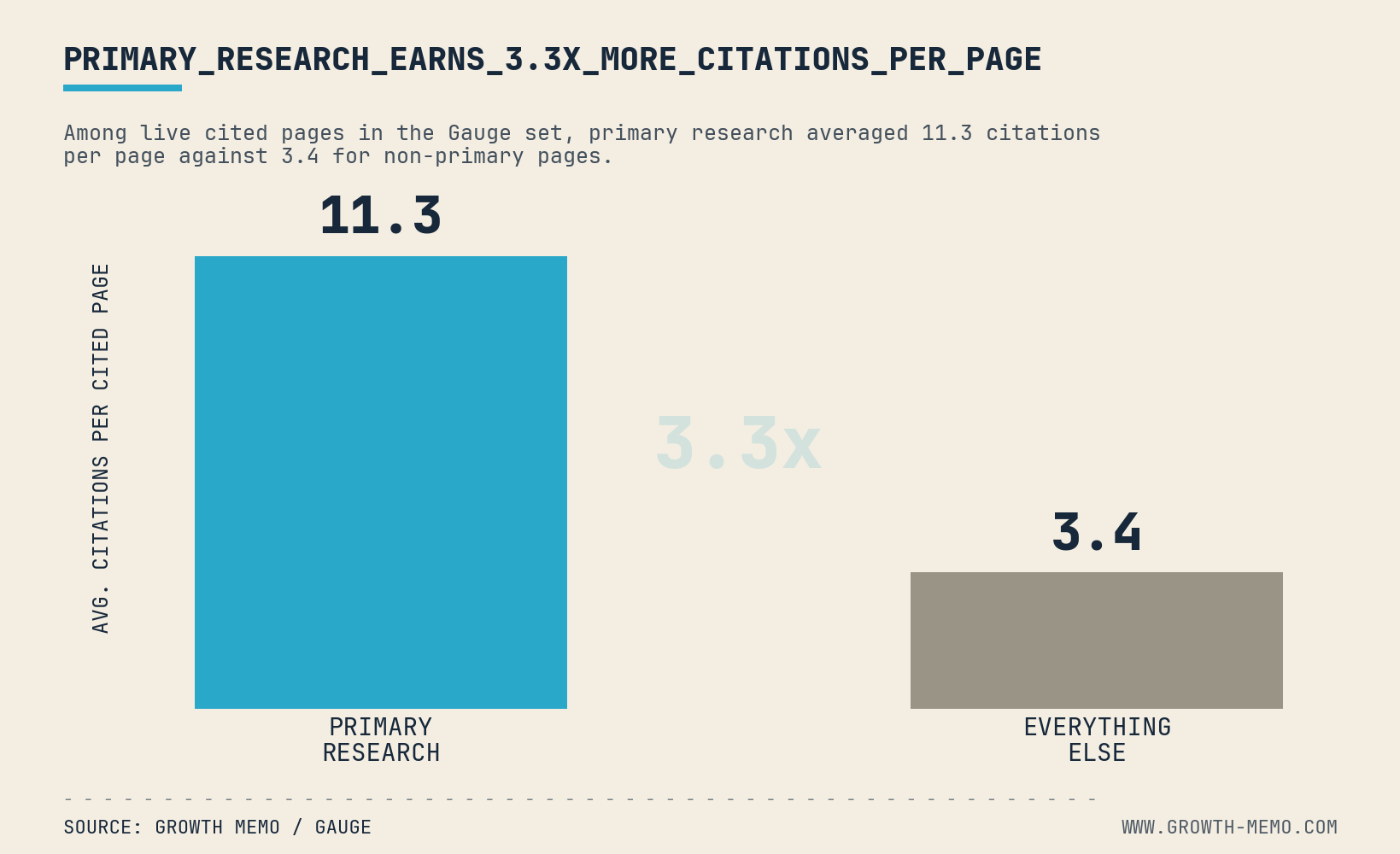
That is the compounding effect of primary research.
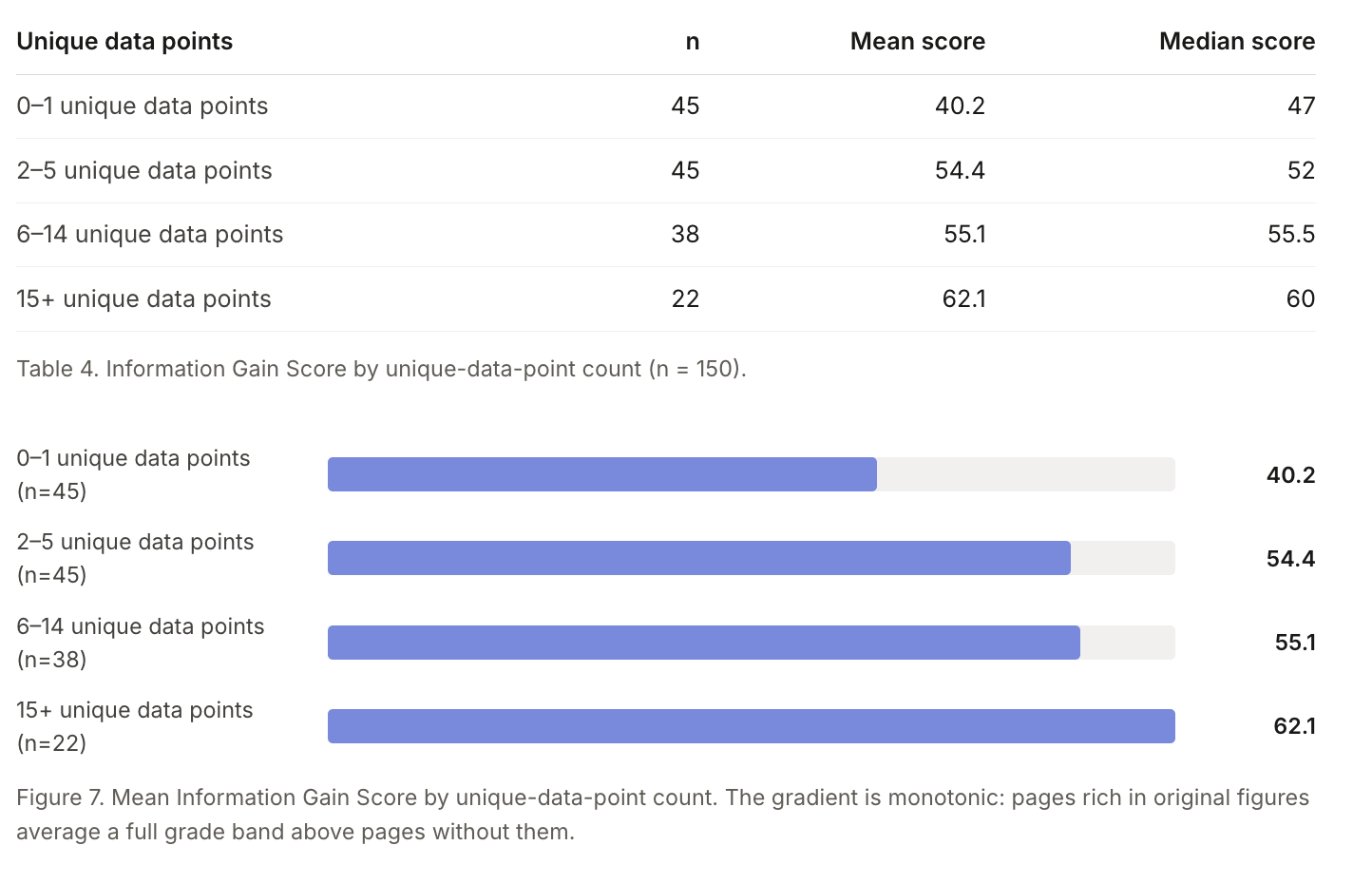
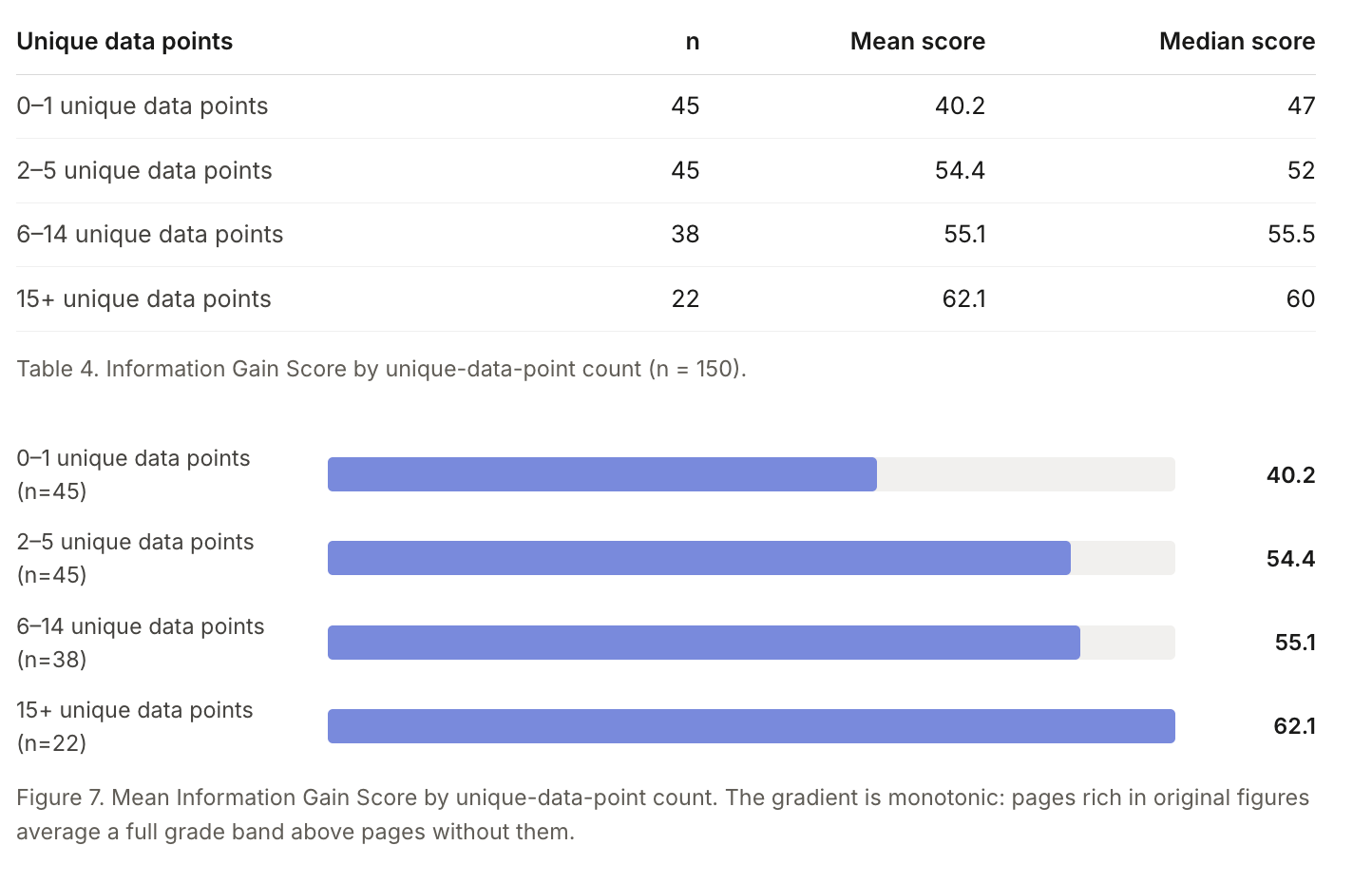
This mirrors the information gain finding I discussed in Part 2, but from the AI citation side rather than the classic 10 blue links side.
There, original data correlated with page originality more strongly than any other trait. Here, original data correlates with citation density. Both findings point in the same direction: the number only you can produce is the lever.
Original research wins when the question has a benchmark
This is where the “original data wins” idea needs more precision.
The 90 primary-research citations were not distributed evenly across the 8 pages. They were not distributed evenly across topics either.
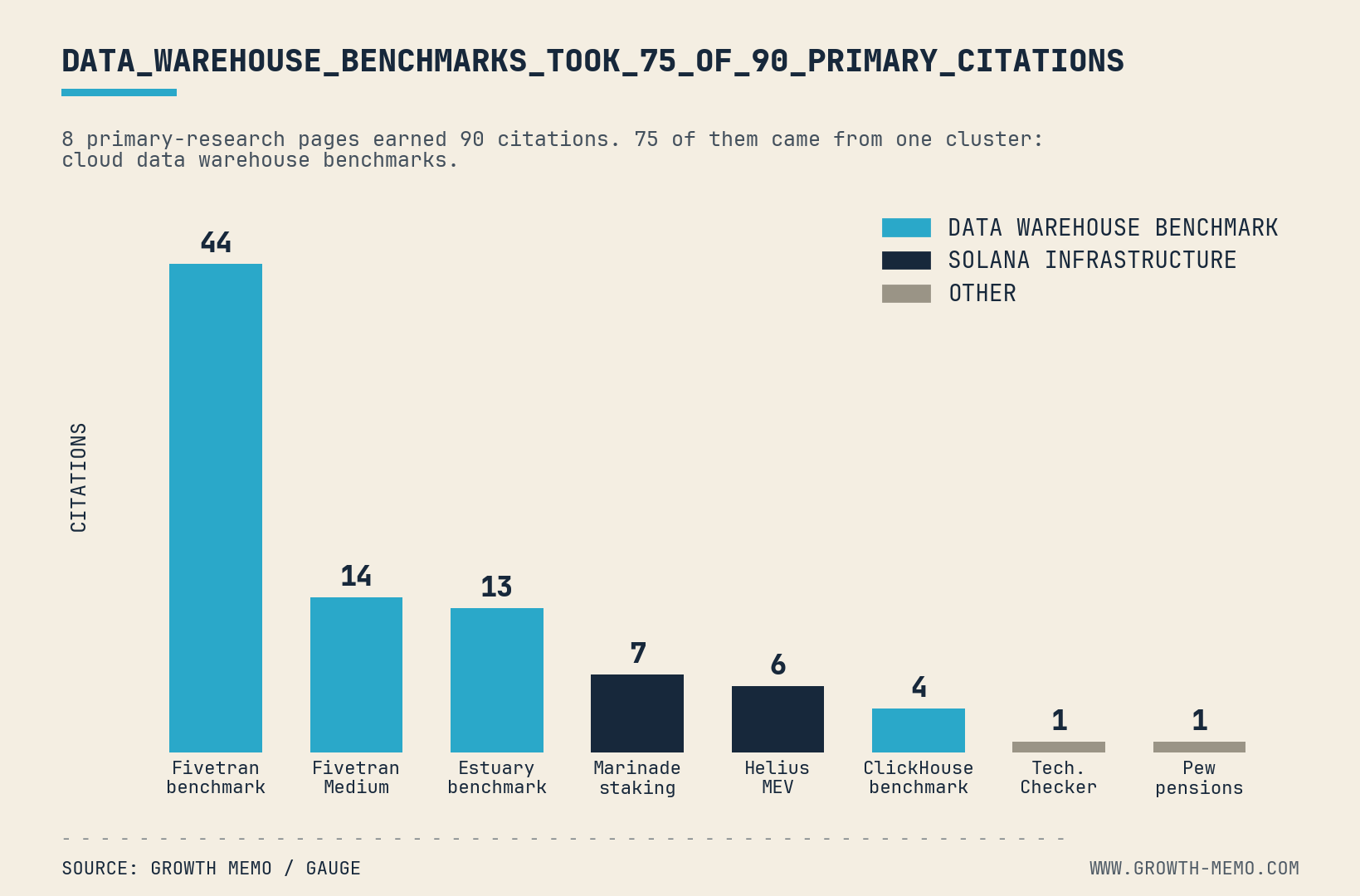
Of those 90 citations, 75 came from one cluster: cloud data warehouse benchmarks. Fivetran’s warehouse benchmark alone earned 44 citations, which was just under half of every primary-research citation in the set.
Once I strip out the benchmark cluster, first-party research barely registers in the citation set. The win is not simply, “I published original data.”
The real win is, “I published a benchmark that answers a buying comparison,” and almost nobody builds those well. By benchmark, I mean a page that measures a set of named things against each other on a specific yardstick and publishes the results as numbers.
Original research is most powerful when it directly answers commercial comparison queries.
This is also what Google is pushing toward with non-commodity content: new, helpful information that is hard to get elsewhere.
The primary-research citations clustered where prompts asked AI to compare options on measurable specs such as speed, cost, latency, yield, or performance.
That explains the warehouse benchmark spike. The “HR Tech / Compensation” label was noisy, but the citations inside that bucket mostly came from cloud data warehouse benchmark prompts. Fivetran, Estuary, and ClickHouse had numbers AI could use.
Crypto / Solana showed the same pattern at a smaller scale. Marinade and Helius earned citations because staking and MEV questions need firsthand ecosystem data, not generic explainers.
The pattern disappeared in topics without a clear benchmark. B2B SaaS / CRM, Education / TEFL, and Product Analytics returned listicles, product pages, explainers, and case studies. After cleaning the data, I found no cited primary-research page in those topics.
A closer look at the content that held 44 citations
Fivetran’s warehouse benchmark took 44 citations from this dataset on its own. Fivetran’s 2 benchmark pages together took 58 of the 90 primary-research citations. So I wanted to understand why.
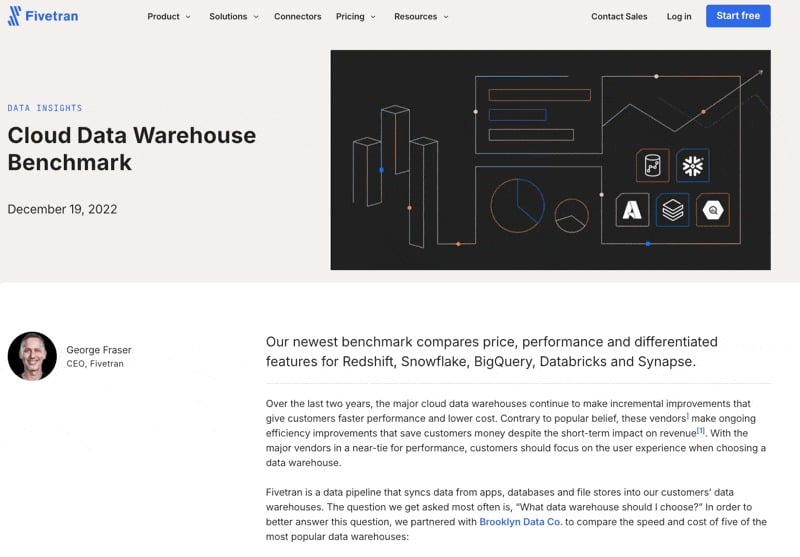
The page was published in 2022, but when I examine it, it is easy to see why LLMs still prefer it.
It answers a measurable comparison head-on. The page names BigQuery, Redshift, Snowflake, and Databricks, then ranks them on speed and cost. It is entity-rich and willing to name the major players directly.
It runs on real first-party data. Fivetran tested against actual customer usage rather than relying on synthetic assumptions, and the page calls that choice out clearly.
It shows the method step by step. The page walks through what data was queried, which queries were used, and how each warehouse was configured and tuned. A reader, or a model, can see how the numbers were produced.
The structure is easy to lift. Descriptive headings such as “Results,” “How much did performance improve?,” and “Why are our results different from previous benchmarks?” help AI map a question to the exact passage that answers it.
It links to raw data and sources. The page footnotes references, including the C-Store paper, and points to the underlying data. That makes the claims verifiable. Few brands put that much work into a data-backed content piece, and even fewer share the full dataset for transparency.
It shows its limits. Dated correction notes from December 2022, named qualitative limitations, and an honest “performance floor” caveat make the claims more credible, not less. The corrections also show care.
The URL never moved. A page from 2022 is still earning citations in 2026 because it stayed live at one canonical address.
The data behind a page like this is easier to pull and analyze than it has ever been. The hard part is everything around the data: the clean method, linked sources, corrections, navigable structure, and willingness to say what the numbers do not prove. That is the craft, and that is the moat.
This kind of first-party data content is not a thin press release with a few loosely pulled numbers. It requires real work, and it can hold authority for years. My takeaway is simple: AI does not reward “original data” by default. It rewards first-party research when the page gives a clear answer to a measurable comparison and signals depth, expertise, and trust.
The opportunity is to publish a retrievable dataset for a buyer question where AI does not yet have a clean benchmark source. That connects directly to the unanswered-questions finding from Part 2. The opening exists, but in many verticals, nobody has walked through it with a real dataset.
Original data needs a citation-ready package
Original data gives a page something AI cannot get from another explainer. But AI still has to retrieve it, parse it, and map it to the user’s question.
That is where many brands lose the citation. They publish proprietary numbers, but bury them in narrative, gate them behind forms, move the URL, or skip the methodology. The data exists, but the citation never happens.
The pages that won in this dataset had both ingredients: original numbers and a clean citation shape. They had stable URLs, clear methods, named comparisons, and results that answered buyer questions directly.
Who wins: brands with proprietary product, usage, or pricing data that package it into a comparison a buyer can act on, especially one that can inform LLM-generated recommendations.
Who loses: brands that publish original numbers inside dense narratives, on slow or unstable pages, with no clear comparison frame for AI to retrieve and reuse.
When I think about a citation-ready research page, I look for four parts.

Lead with the comparison result. The headline finding, such as “X is fastest” or “Y is cheapest at scale,” should appear in the first 30% of the page. Lead with the result, then explain the method and nuance.
Box the methodology. Show the sample, time window, what was measured, and how the measurement happened. Attribution confidence is part of what makes a number citable, so the method needs to be clear on the page.
Frame the comparison explicitly. AI reaches for benchmarks when prompts ask “which is best.” A table comparing named options on named specs is the format most likely to be lifted.
Keep the URL stable. Use one canonical page and keep it live. Do not migrate it or rename it every redesign. The citation earned this quarter only compounds if the page is still there next quarter. In this dataset, 64 of 365 cited URLs were dead, redirected, or otherwise broken, taking 203 citations down with them.
This is the work behind a citable benchmark, and it is more involved than it looks.
HockeyStack documented its own version in a playbook on launching research reports. The company published 18 original reports built entirely on anonymized first-party customer data, the kind of data no competitor could replicate.
Its process includes the same steps the Fivetran page demonstrates: list the data points needed, have a teammate pull them with SQL, define and document the method so the numbers can withstand scrutiny, and structure the report around a real ICP question. HockeyStack calls methodology non-negotiable because without it, someone will always dispute the data.
With AI analysis, pulling the data is often the easier part now. Building the content into something citable, trustworthy, and durable enough to keep earning visibility for commercial queries years later is where the harder work sits.
What sites are already trusted for your topic? When a benchmark you did not publish is earning the citations in your category, the Citation Source Mapper can map that trusted set into a ranked, pitchable target list. It is available in the premium library.
This post first appeared on the author’s website and is republished here with permission.
Inspired by this post on Search Engine Land.