I’ve discovered that the biggest SEO gains now come from interactive experiences that immediately address user intent and remove friction.
SEO was once heavily reliant on external factors, especially developer support and waiting on roadmaps that promised features “maybe next quarter.”
If I needed a new page template, a calculator, or even an interactive component, I had to wait. But that’s no longer the case.
Nowadays, if you’re involved in SEO or GEO and haven’t explored vibe coding, you might be hindering your potential impact.
Vibe Coding: Shifting SEO Power Dynamics
Not long ago, creating tools like calculators or widgets involved lengthy processes, but now I’ve used AI to build dozens of apps without needing a developer.
Some tools are basic and others not visually appealing, but they’re effective and drive thousands of organic visits monthly.
Pages centered around these tools are outperforming traditional content competitors.


What’s truly transformative is that my SEO team is now adept at building tools independently, which empowers us to achieve our goals faster.
We can test ideas instantly and utilize developer skills for more complex tasks like scaling and infrastructure.
There’s a significant sense of accomplishment when creating and releasing a tool that consistently attracts traffic.
It’s not about sophistication; it’s about building effective tools.
Engage Directly: From User Personas to Conversations
The traditional approach says to identify and cater to user personas. But few explain how to present that effectively.
- Recognize user personas.
- Pinpoint their challenges.
- Create content to address those challenges.
Previously, SEO relied heavily on text targeting personas, which is now outdated.
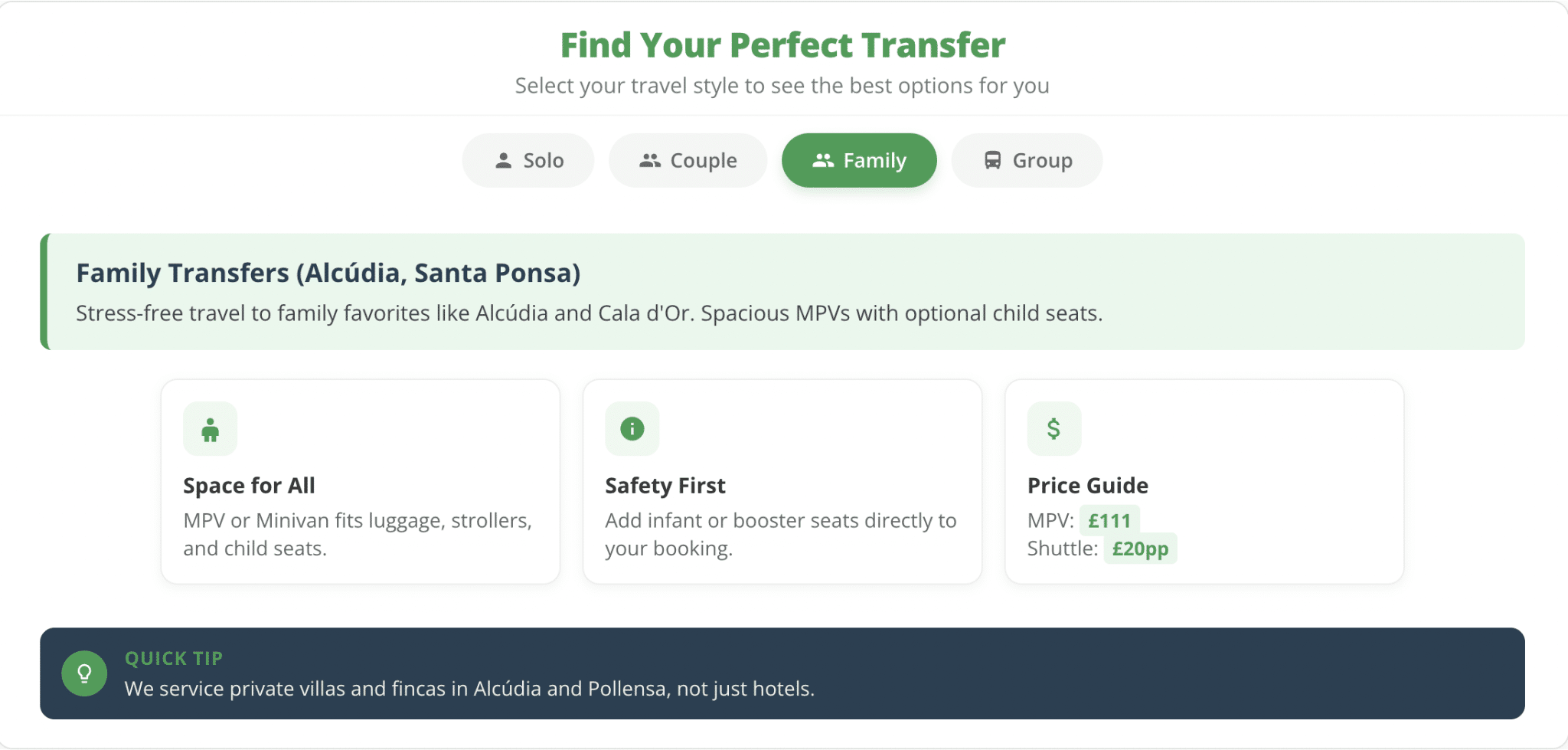
Instead, we should let users self-identify to show the most relevant content.
- A vibe-coded component with tabs for different personas.
- Each tab reveals content tailored to that persona.
For instance, Majorca airport transfers differ greatly between family travelers and solo adventurers.

Families care about safety and child-friendly options, visible only when their tab is selected.
SEO strategies now harness data from sources like Google Search Console to directly address these needs.
The component was strategically coded to enhance immediate intent satisfaction.
This mirrors AI platforms’ approach: segmented, persona-aware, and intent-driven.

Harnessing Traffic through Tool-Only Categories
In a personal project, I launched a Tools category with ten pages of simple, effective tools like calculators and count-down timers.
- Calculators.
- Checklists.
- Calendars.
- Countdown timers.
- AI generators.
Each page’s centerpiece is its tool, supported by components addressing additional queries.
The impact? Over 5,000 clicks in two months, even with seasonal variations.
UI: A Powerful Ranking Factor
SEO capabilities have expanded, but creativity remains essential.
Visual presentation is a highly underrated SEO asset today.
Merely producing text is insufficient. Instantly fulfilling intent through UI is key.

- Two calculator pages have added significant monthly sessions.
- A tool ranked in the top three within days for a government query.
- Pages rank off-season thanks to superior UI.
Where others list information, I offer interactive user engagement.
- Eligibility calculators.
- Countdown timers.
- Dynamic tables.
- Visual comparisons.
Text backs up the tool rather than being the main attraction.
SEO Done Right, Quickly
I published a page targeting a Greek government program, outshining heavy-text competitors.
We introduced:
- An eligibility tool.
- A transparent algorithm explanation.
- Tips to avoid application errors.
- Historical program updates.
- An application walkthrough.

The page was promptly tagged and marked up, achieving a first-page ranking within three days and generating substantial clicks.
Solving problems better than anyone else shortens the typical SEO timeline.
Maximize SEO and PR with Tools
Tools can drive traffic or act as valuable digital PR assets.
A due date calculator or baby name generator could turn into a major PR opportunity.

A modern tool addressing real needs, outshining SERP features, can become the interface where SEO and PR beacons meet.
Uncovering Tool Page Opportunities with Ease
SEO tools’ MCP servers now make discovering tool ideas from search demand a breeze, letting me validate and launch swiftly.
This method has significantly sped up my tool page creation process compared to traditional methods.

We’re moving into an era where ideation, validation, and action can occur in days, reducing project duration considerably.
The Paradigm Shift in SEO
SEO has evolved beyond long-form content, demanding fast intent fulfillment and seamless user experiences.
Embracing vibe coding can accelerate development and provide a competitive edge. Building interactive elements, not just content, is crucial for modern SEO success.
Inspired by this post on Search Engine Land.