I’ve recently discovered that Google has introduced a new feature in Chrome Lighthouse to check for llms.txt files. Though Google mentions that llms.txt isn’t necessary for AI search visibility, Lighthouse has started flagging sites based on their presence.
Google’s latest Lighthouse audits, under the “Agentic Browsing” category, now focus on a site’s usability for machine interaction. I find this interesting as it aligns with Google’s push towards better machine readability.
The new audits are part of Chrome’s evolving “Agentic Browsing” features, which analyze if sites are prepared for automated interaction. This concept came soon after Google issued guidance on AI search optimization, debunking the necessity of llms.txt files in their new guide on generative AI features.
What Lighthouse Evaluates Now. Lighthouse’s Agentic Browsing tests focus on how well my site is built for machine interactions, incorporating various deterministic audits as per Google’s documentation. These checks include:
– WebMCP integration.
– Accessibility tree integrity.
– Layout stability through CLS.
– Presence of an llms.txt file.
These audits help ensure that there’s a machine-readable summary at the site’s domain root. Google explains that without llms.txt, agents might take longer to understand a site’s main structure.
The impact of these audits doesn’t translate into a traditional Lighthouse score but into a fractional pass ratio related to agentic readiness signals.
The Tension. Interestingly, while these audits don’t directly affect SEO rankings, their mention in Google’s readiness checks could make SEOs reconsider their stance on llms.txt files.
Agentic Engine Optimization. Google’s approach aligns with insights shared by Addy Osmani from Google Cloud AI about Agentic Engine Optimization. Osmani emphasizes creating web content that is semantically structured, token-efficient, and easy for AI to process.
SEO vs. llms.txt. According to Google, creating llms.txt or similar files isn’t necessary for AI search success, as outlined in the guide on Mythbusting generative AI search. The AI systems can discover, crawl, and index a variety of file types encountered on the internet.
John Mueller from Google responded to concerns about the role of llms.txt in a discussion with Lily Ray on Bluesky, stating that the use of these files is more for functionality and not directly linked to search engine optimization.
Google’s Take on AI Agents. Besides llms.txt, Google’s Lighthouse guidelines place strong emphasis on accessibility and interface stability. The insight I gained is that AI agents heavily rely on the accessibility tree as their core data model, focusing on integrity and proper layout.
Ultimately, while Google indicates llms.txt isn’t needed for search, including such files might be beneficial for adapting to Google’s evolving tools that prioritize machine readability.
Rendering isn’t always immediate or complete. Discover where no-JavaScript fallbacks still safeguard critical content and indexing in 2026.
I’ve noticed that Google has the capability to render JavaScript, but it doesn’t always do so instantly or flawlessly. Since Google’s 2024 comments on rendering all HTML pages, developers have questioned the necessity of no-JavaScript fallbacks. Now, in 2026, the answer is clearer yet nuanced.
Google’s position on JavaScript rendering has been a hot topic since July 2024. During an episode of Search Off the Record, Martin Splitt and Zoe Clifford from Google’s rendering team discussed rendering costs and prioritization.
Developers, especially those working on JavaScript-heavy applications, began to question the need for fallbacks. On the other hand, many SEOs remained skeptical, wary of removing fallbacks without understanding Google’s consistency and limits in rendering processes.
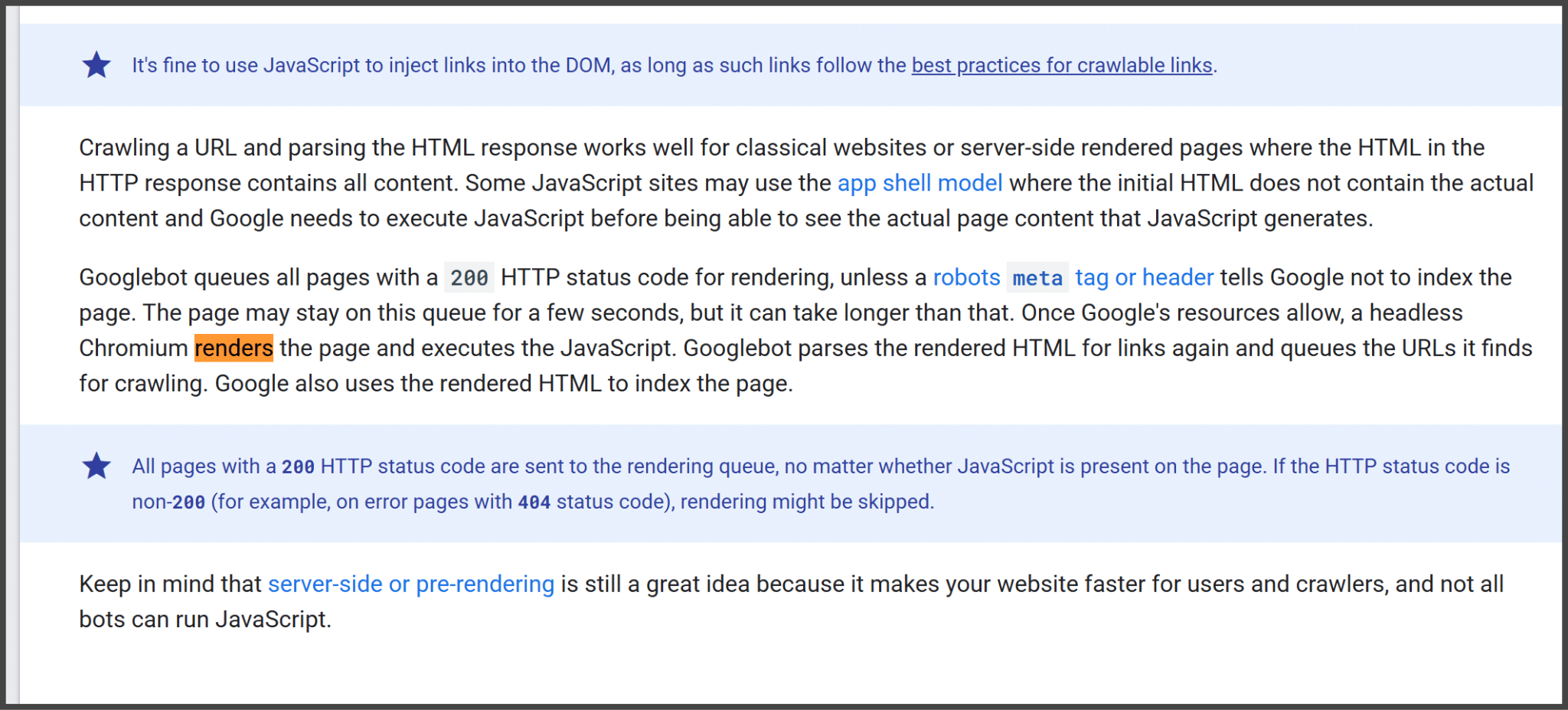
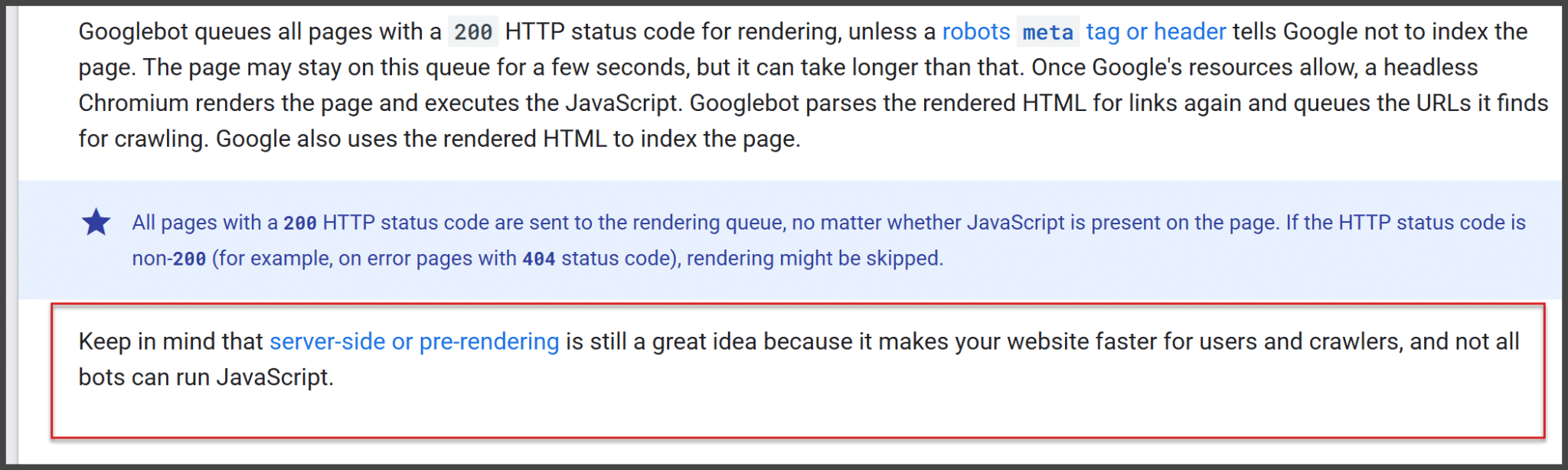
While developers debated, Google’s documentation clarified how JavaScript rendering functions. Pages are queued for rendering, and once resources become available, a headless browser processes the JavaScript. This means that not all interactions within JavaScript elements are parsed immediately.
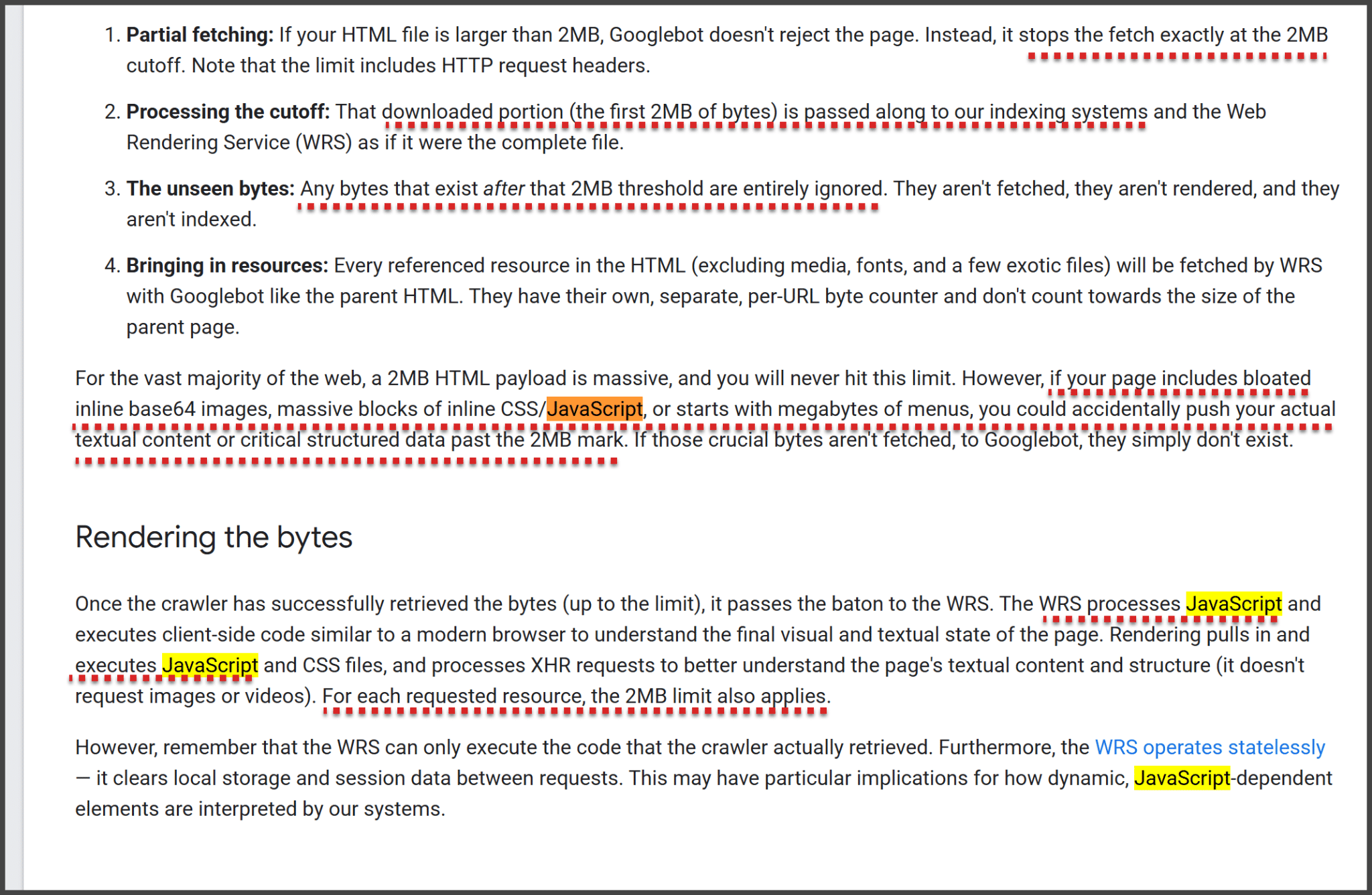
Google’s guidelines on rendering emphasize the importance of pre-rendering strategies like server-side rendering to ensure critical content is indexed properly. Although Google claims it renders all pages, there are practical limits, such as a 2MB HTML and resource cap.
Discover Google's March 2026 updates, enhancing clarity in forum markup, meta tag processing, and modernizing accessibility content for SEO.
Although Google’s JavaScript capabilities have improved, the broader web hasn’t uniformly adapted, with many systems still dependent on HTML-first delivery. As AI crawlers and other non-Google bots often don’t execute JavaScript, the need for no-JavaScript fallbacks remains critical.
Despite Google’s advancements, fallbacks for critical architecture, content, and links are still vital. Google’s documentation and recent updates reinforce this by highlighting the ongoing importance of server-side rendering and resilient HTML.
From personal experience, it’s clear that while blanket no-JavaScript fallbacks might not be universally necessary, critical content should not solely depend on JavaScript. In 2026, no-JavaScript fallbacks for essential content are more than just a good idea; they are often essential for maintaining SEO integrity.
I’ve often wondered how much schema markup actually aids AI search optimization. There are claims it can increase citations or significantly enhance AI visibility, yet the truth is more complex and nuanced.
Let’s dive into separating facts from assumptions and explore how schema truly integrates into an AI search strategy.
How Schema Fits into AI Search Now
Search is evolving from simple SERP links to dynamic AI Overviews, with generative answers and chat-style summaries compiling content beyond just links. My goal is to ensure my content is recognized within this model, and that’s achieved by focusing on ‘entities’—distinct concepts such as a person, place, or event—not just strings of text.
Schema markup is a powerful tool I use to clarify these entities and their relationships, making them comprehensible to AI. For instance, identifying a person, their organization, the price of a product, or the author of an article.
AI systems focus on three key elements:
Entity definition: Identifying brands, authors, services, or SKUs on the page.
Attribute clarity: Distinguishing which properties relate to which entity (like prices or ratings).
Entity relationships: Understanding connections between entities (using tags like offeredBy or authoredBy).
By employing schema with stable values and structured methods, it begins to function like a mini knowledge graph. AI systems no longer guess who I am or how my content ties together; they follow explicit links between my brand, authors, and subjects.
Microsoft Bing Copilot: Microsoft’s product manager confirmed in March 2025 that schema aids Microsoft’s LLMs in understanding content for Copilot.
Exploring ChatGPT, Perplexity, and Other AI Search Platforms
The usage of schema by these platforms remains uncertain. They haven’t publicly clarified if they maintain schema during crawling or use it for data extraction. Though LLMs can technically process structured data, it doesn’t guarantee their search systems do.
It doesn’t negate schema’s value, but highlights that schema alone doesn’t drive citations. LLM systems prioritize relevance, authority, and clarity over structured markup presence.
LLMs excel when given a structured format to fill out instead of a blank canvas, minimizing errors when extracting defined data fields.
Schema markup resembles this structured format, providing clear entity, brand, and topic fields.
Interpreting the Research
The findings suggest that LLMs can better process structured data than unstructured text. However, we still lack confirmation on whether AI search systems preserve schema data during crawling or use it during extraction.
For Microsoft Bing and Google AI Overviews, schema likely improves data extraction accuracy, given their confirmed usage. Other platforms remain unverified regarding implementation.
Given the novelty of AI search—exemplified by ChatGPT’s launch in October 2024—companies haven’t revealed their indexing methods. Measuring impact remains challenging due to non-deterministic AI responses.
No peer-reviewed studies yet explore schema’s AI search visibility impact, nor are there controlled studies on LLM citation behavior with schema.
This gap persists as AI search is relatively new, with companies withholding indexing details and difficulties in assessing AI interactions.
Building an Entity Graph with Schema
In traditional SEO, schema is often limited to adding individual markup like Article or Organization. For AI search, connecting nodes into a cohesive graph through @id is more beneficial.
Create an Organization node with a permanent @id for your brand.
Develop a Person node for each author linked to your organization.
Form an Article node linking the author to the publication with detailed topics.
This interconnected pattern transforms schema into a useful entity graph. For AI systems preserving the JSON-LD, it clearly identifies brand ownership, human responsibility, and topic focus, unaffected by page changes over time.
Aspect
Traditional SEO schema
Entity graph schema
Structure
Single @type object per page
@graph array of interconnected nodes
Entity ID
None (anonymous)
Stable @id URLs for reuse across site
Relationships
Nested, one‑way (author: “name”)
Bidirectional via @id refs (worksFor, authoredBy)
Primary benefit
Rich snippets, SERP CTR
Entity disambiguation, extraction accuracy for AI
AI impact
Minimal (tokenization often strips)
Makes site a unified knowledge graph source if preserved
Schema markup acts as infrastructure rather than a miracle solution. Although it may not automatically raise citation rates, it’s an aspect I control that’s explicitly used by platforms such as Bing and Google AI Overviews.
The key isn’t just implementing schema in isolation, but integrating structured data with proper entity connections, high-quality authoritative content, and clear entity identity and brand signals. Strategic use of @graph and @id to build these connections is crucial.
After conducting a thorough comparison of over 35 SEO agencies focusing on AI startups, I’ve ranked them based on five crucial factors. Each agency was evaluated to identify their capacity in rapidly evolving markets.
The criteria used in this assessment include:
Notable Clients (35%): Agencies were assessed based on their clientele, specifically those in AI and software startups, highlighting their proficiency in adaptable markets.
Leadership Experience Score (25%): A score from 1-5 that evaluates the leadership, focusing on their history in marketing and tech startups.
Average Reviews (25%): Agency performance was rated from 1-5, weighted more by reviews from AI firms.
Company Size and Year Founded (15%): While not as critical, company size and longevity are indicative of sustainable growth and enduring success.
The top agencies are displayed below, noting their rankings, headquarters, and SEO specializations.
Tech-focused marketing services centered on modern marketing channels like SEO, short-form video, and social media
First Page Sage
At First Page Sage, we’re leading the field with innovative SEO and generative engine optimization strategies tailored for AI companies. Our robust content production helps AI firms solidify their authority, with proven success on Google and AI platforms like ChatGPT.
“First Page Sage provides top quality content marketing with competent teams possessing specialized industry knowledge. Clients report measurable organic results within year one that significantly increased online leads.”
Clay Agency
Specializing in the technical side of SEO, Clay Agency excels in branding and UX/UI design, making them perfect for AI companies aiming to unveil products or services interactively and refresh their image in the AI realm.
“The Clay Agency worked as an extension of our own team, delivering an interface that clients are extremely proud of. Their tech-savvy teams are familiar with market trends, creatively tackling technical challenges.”
Marketing Eye
At Marketing Eye, we focus on technical SEO for tech firms, including website auditing and keyword analysis. Besides technical services, we also manage content and social media campaigns, particularly in the retail sector, while also supporting various tech companies.
One of the more established names here, our lean team thrives on blending marketing expertise with computing acumen, ensuring continued prominence in the field.
“Marketing Eye provides superior service, delivering measurable growth. Their teams are competent and professional but might require additional training.”
RNO1
RNO1 specializes in digital branding and product design for tech, AI, and commerce brands, offering technical SEO, market research, and services like AR/VR and Web3, distinguishing them from others.
Notable Clients: Prive, TakeUp, Fluxa
Leadership Experience: 3.5
Company Size: 51-100
Year Founded: 2018
Headquarters: Seattle, WA
Average Reviews: 4.2
Main Focus: Market research and UX/UI design for SaaS Companies
“RNO1 offers a redesigned website praised by users, but their teams sometimes rely too much on online management over direct communication.”
REQ
With REQ‘s expertise in branding, PR, and reputation management, we’re ideal for companies launching new products. While primarily focusing on branding and PR, our SEO services complement traditional marketing strategies effectively.
Notable Clients: Katabat, Verint, ActiveNav
Leadership Experience: 3.8
Company Size: 51-100
Year Founded: 2008
Headquarters: Washington, DC
Average Reviews: 4.3
Main Focus: Branding and UX focused SEO for tech companies
“REQ provides an excellent SEO analytics department that improves client reporting visibility and dramatically raises CTR, though improvements are needed in web development and response speed.”
Optimizely
Optimizely focuses on optimizing web pages through A/B testing, multivariate testing, and personalization, perfect for companies with solid content needing enhanced technical support.
Notable Clients: Google Cloud, Salesforce, New Era
Leadership Experience: 3.8
Company Size: 500+
Year Founded: 2010
Headquarters: New York, NY
Average Reviews: 4.0
Main Focus: A/B Testing, Mobile optimization, Conversion Rate Optimization
“Optimizely offers an intuitive UI that integrates easily, though lacking in extensive server-side testing capabilities.”
Directive Consulting
Directive Consulting excels in PPC and tech-focused marketing, offering performance-based campaigns that blend paid services with SEO to enhance visibility.
Notable Clients: Amazon, Snap Inc
Leadership Experience: 4.0
Company Size: 50-249
Year Founded: 2014
Headquarters: Irvine, CA
Average Reviews: 4.8
Main Focus: Tech-focused marketing services centered on modern marketing channels like SEO, short-form video, and social media
Have you ever wondered how the structure of your webpage affects its visibility on search engines? As someone who regularly dives deep into the technicalities of SEO, understanding the DOM (Document Object Model) is crucial for optimizing your site.
I’ve often encountered discussions about the DOM with developers, and maybe you’ve seen it referenced in tools like Google Search Console. But why does it matter so much for SEO? Let me walk you through its significance and how to optimize it.
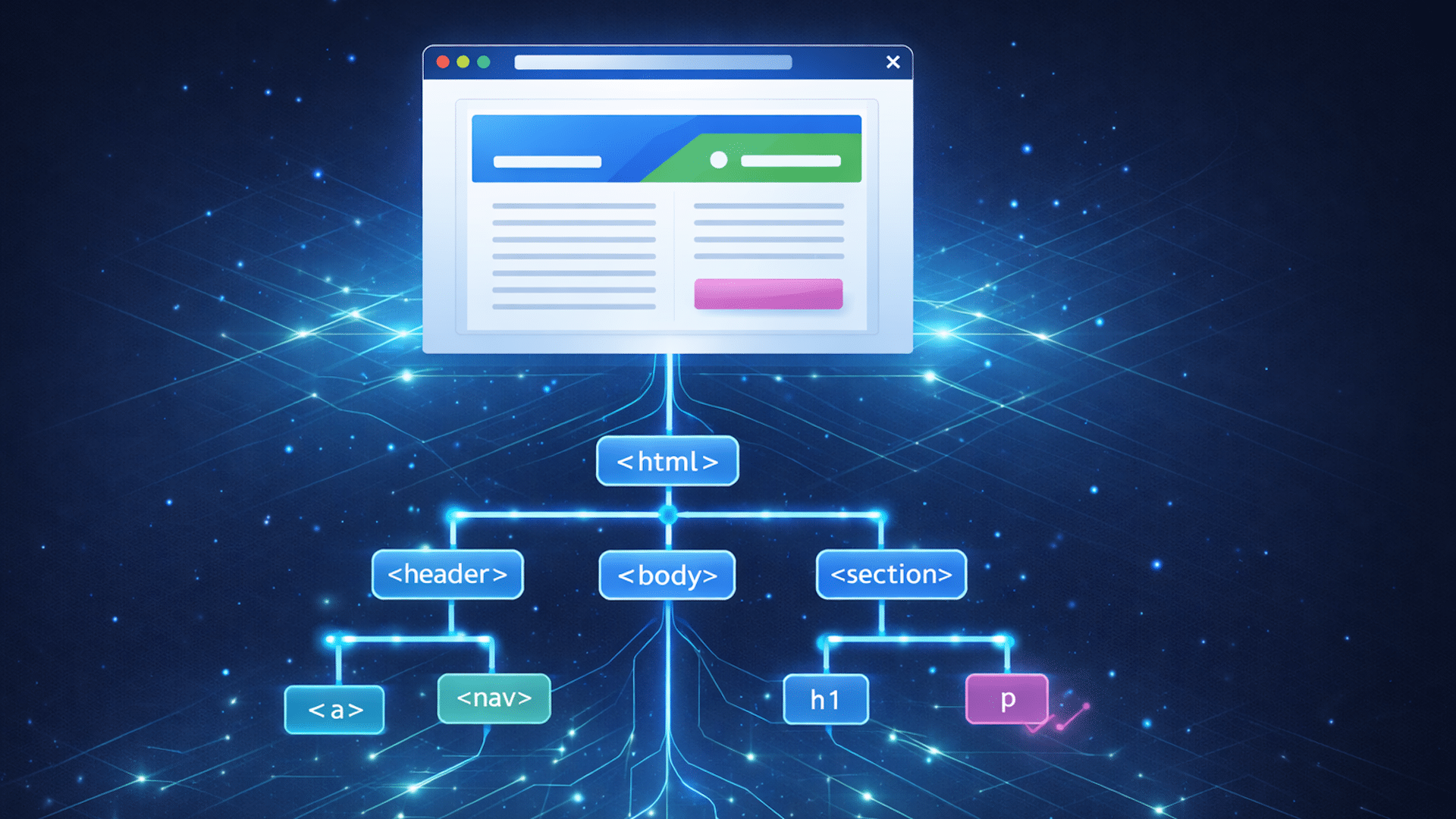
In essence, the Document Object Model is the browser’s dynamic, in-memory representation of your webpage. It serves as a bridge that allows programs, notably JavaScript, to interact with your content.
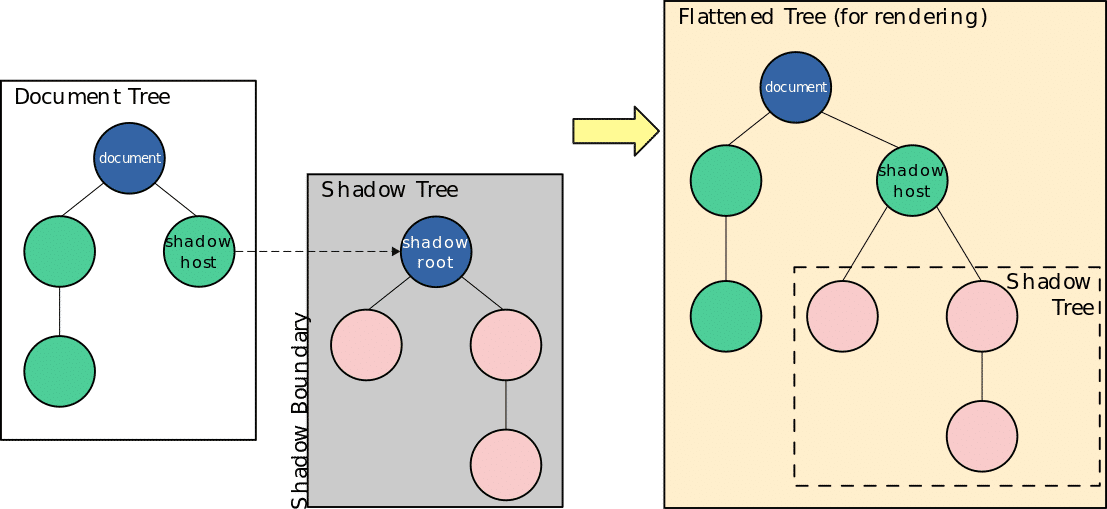
The DOM is structured like a family tree:
The document: Acts as the root of this tree.
Elements: HTML tags such as <body> and <p> transform into branches or nodes.
Relationships: There are parent-child-sibling relationships among elements.
This hierarchy is key for the browser and search engines in understanding your content’s structure, helping them discern, for instance, which paragraph is associated with a given heading.
The exploration of the DOM doesn’t end there. Let’s look at how you can inspect it directly.
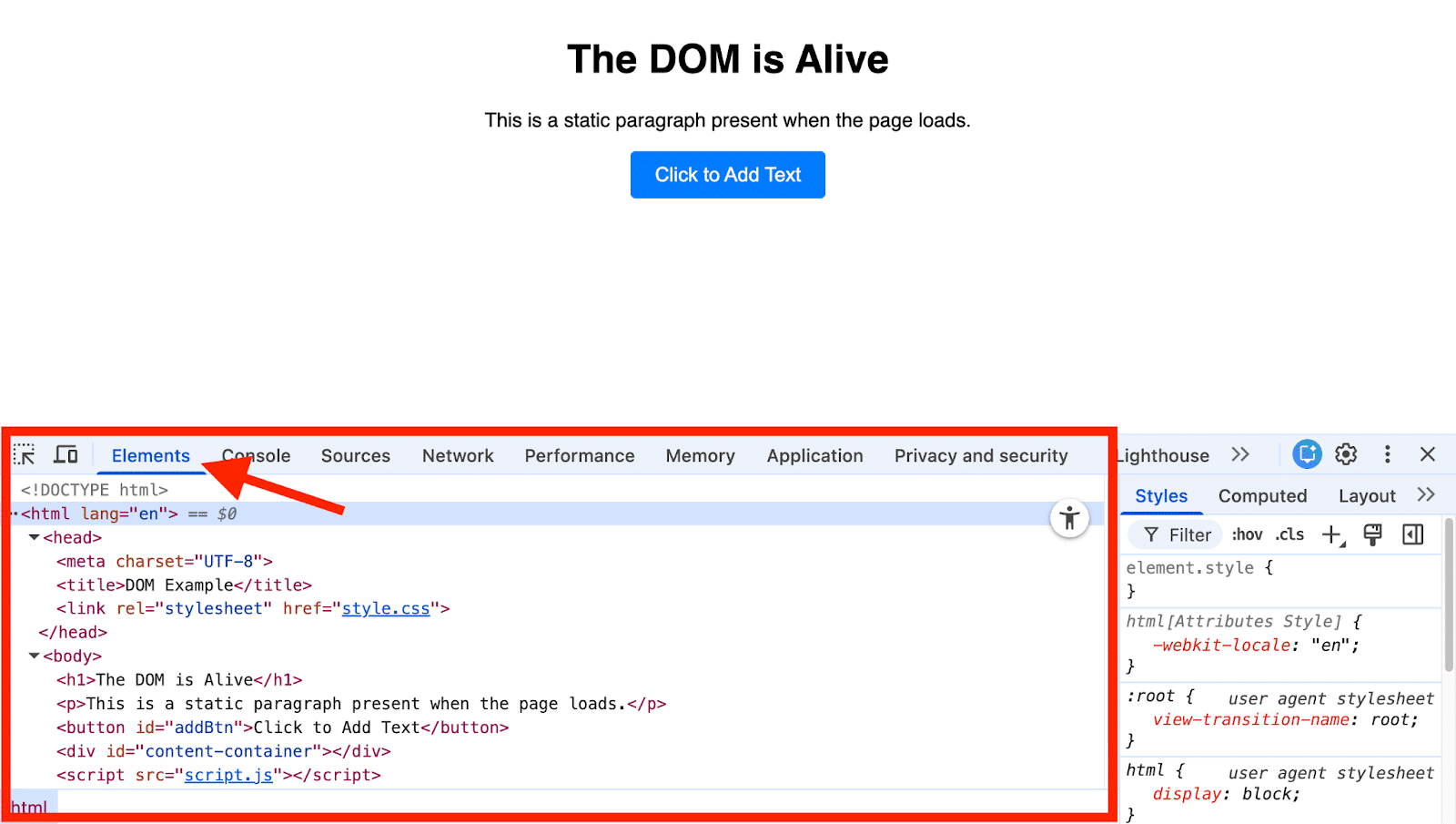
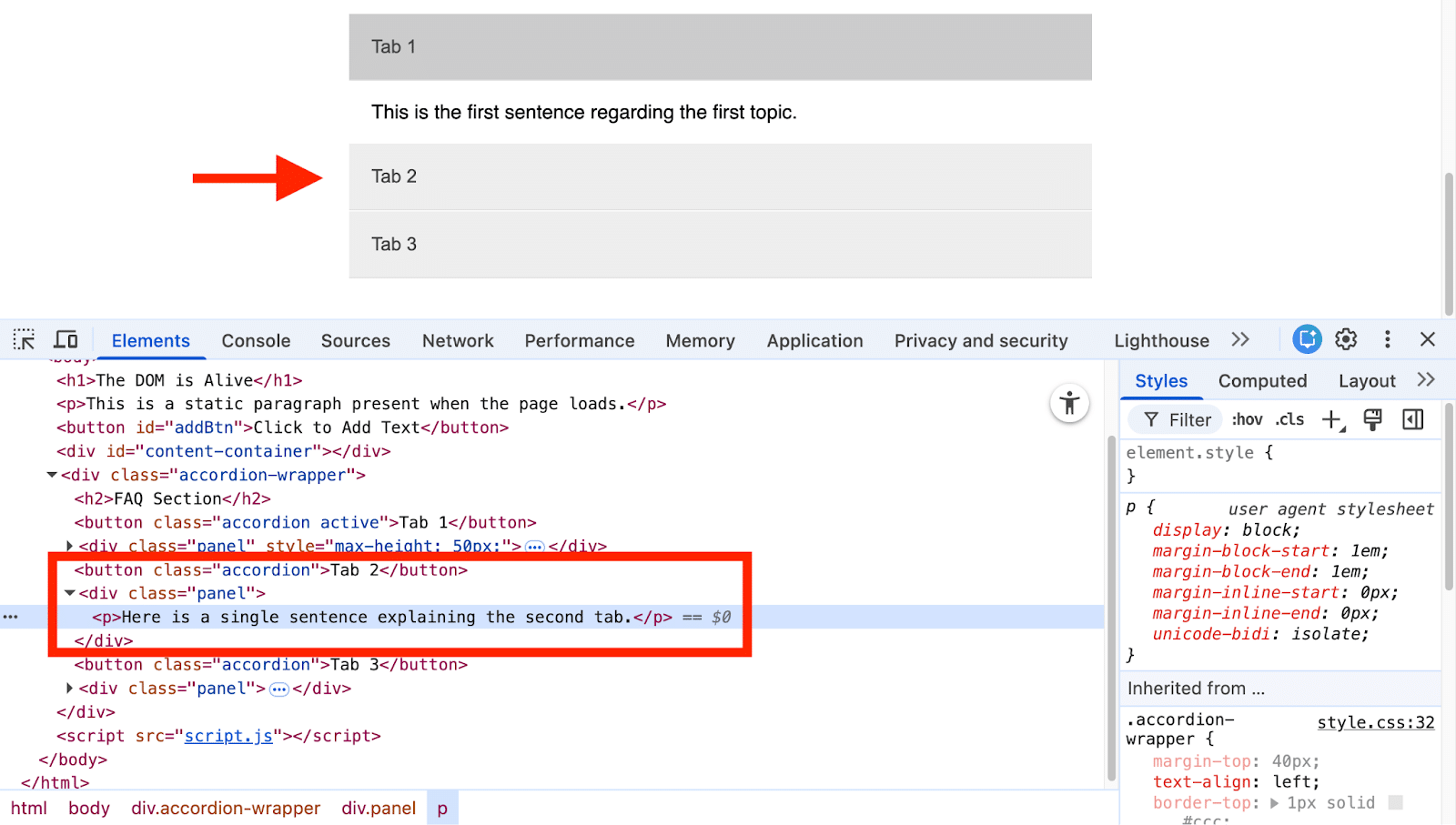
The DOM, a JavaScript object, can be viewed in a format akin to HTML using browser DevTools—just right-click on your page, select Inspect > Elements, and you’ll see the Elements panel.
In this panel, it’s easy to dive into the structure by:
Expanding and collapsing nodes to explore hierarchy,
Searching for elements using Ctrl+F (Cmd+F on Mac), and
Identifying JavaScript-added or -modified elements as they flash briefly on change.
However, do remember that this tool sometimes shows a different view from what Googlebot crawls. I’ll delve into this discrepancy a bit later.
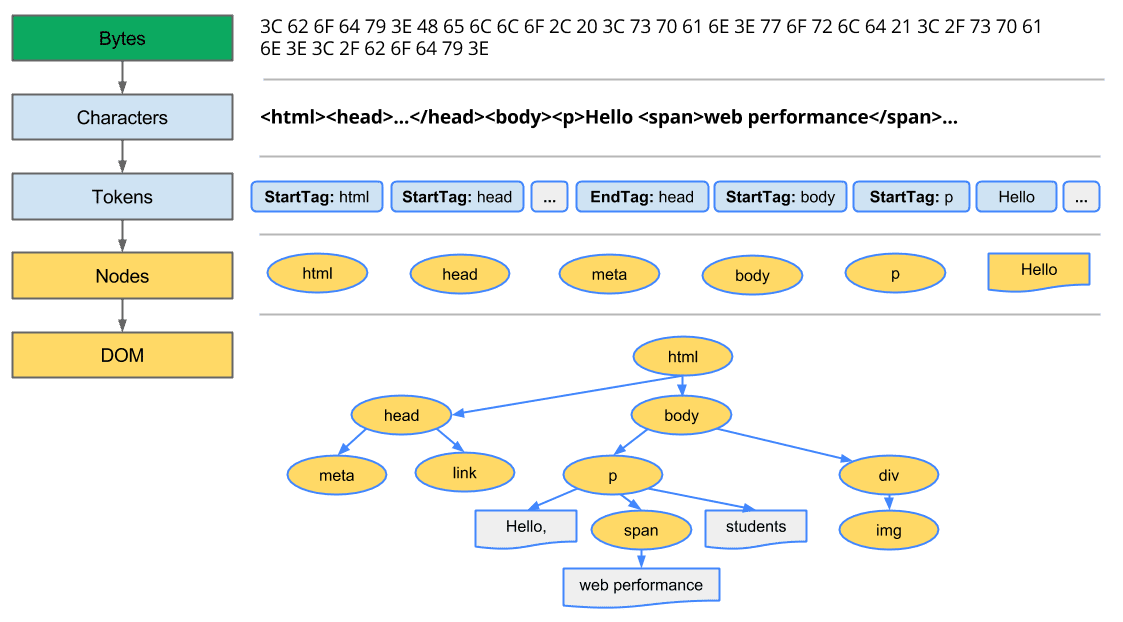
Next, understanding how the DOM is built is essential. It starts with the browser converting the HTML file retrieved from a server line-by-line into tokens, which are then turned into nodes forming a tree structure.
This tree-building process allows browsers to create a hierarchical structure necessary for rendering the web page you see, which also includes building a CSS Object Model (CSSOM), but this is less crucial for SEO than the DOM.
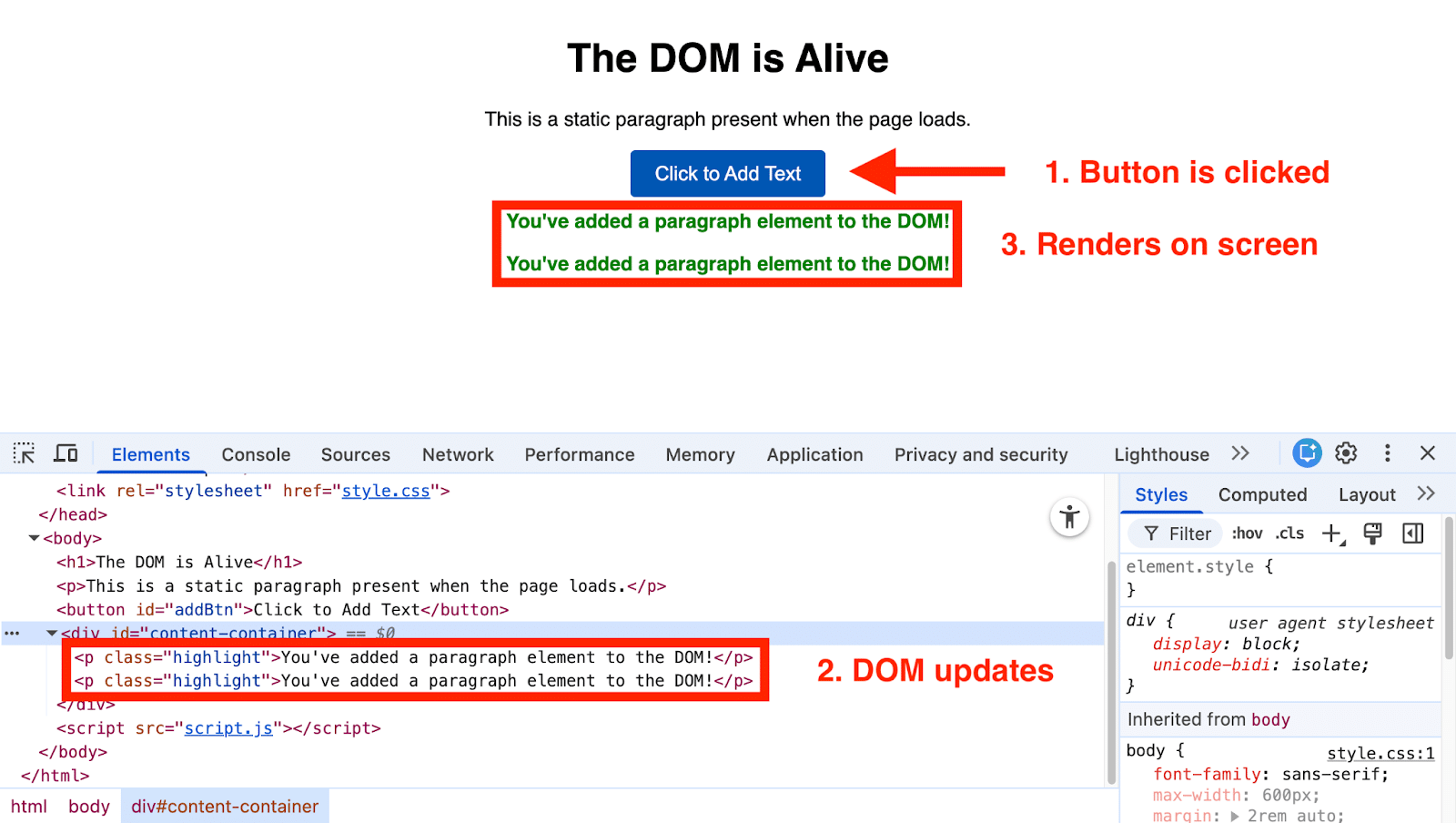
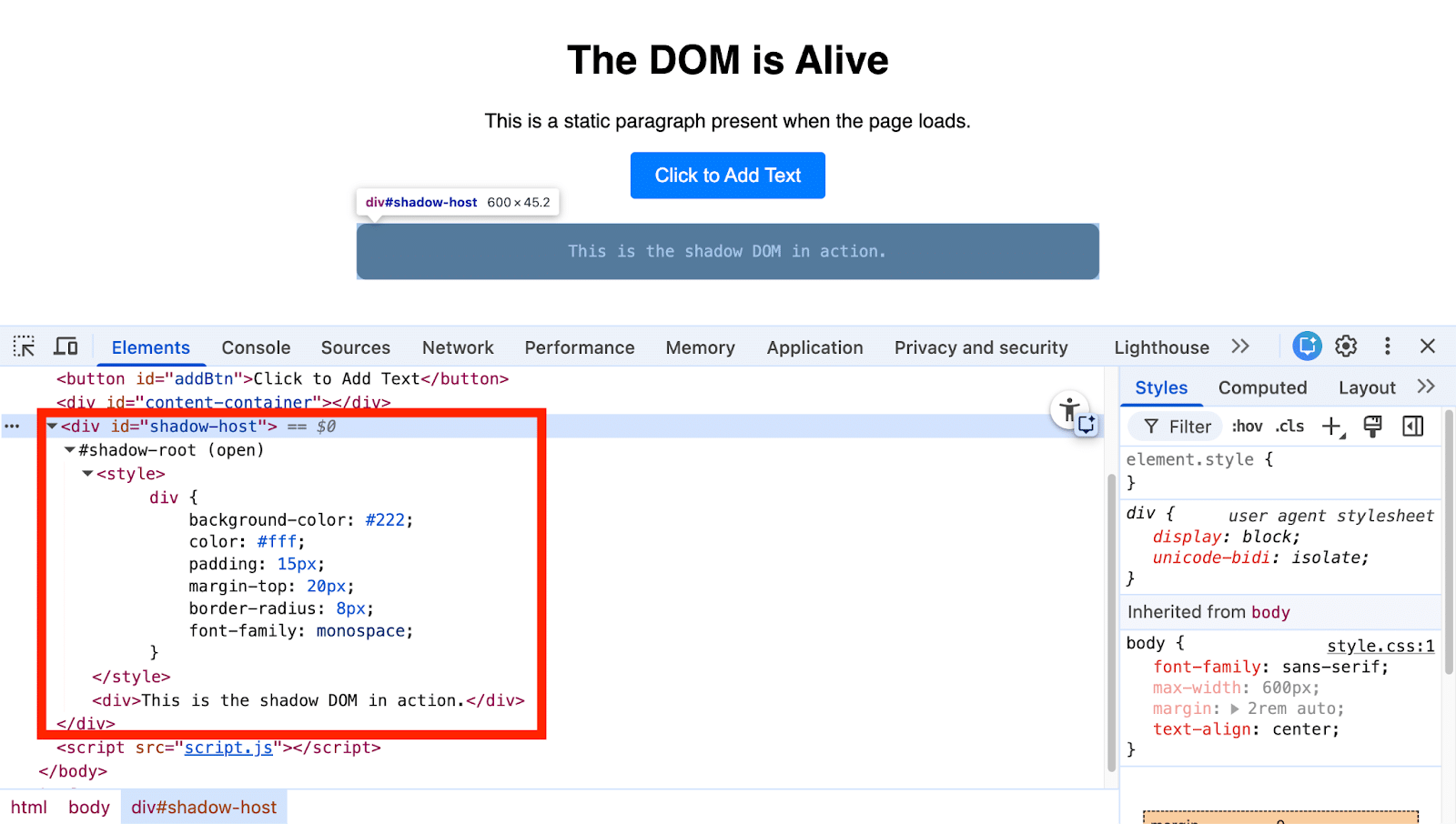
JavaScript often runs during this DOM construction. On encountering a <script> tag without async or defer attributes, the browser pauses to execute the script before continuing. These scripts might modify the DOM by adding content or changing links, differing from the initial HTML code.
Let me illustrate this: Each click on a button dynamically adds a paragraph to the DOM, changing the page’s visible content.
The original HTML is just a starting blueprint; the final constructed DOM is what the browser utilizes. It can dynamically change based on JavaScript operations.
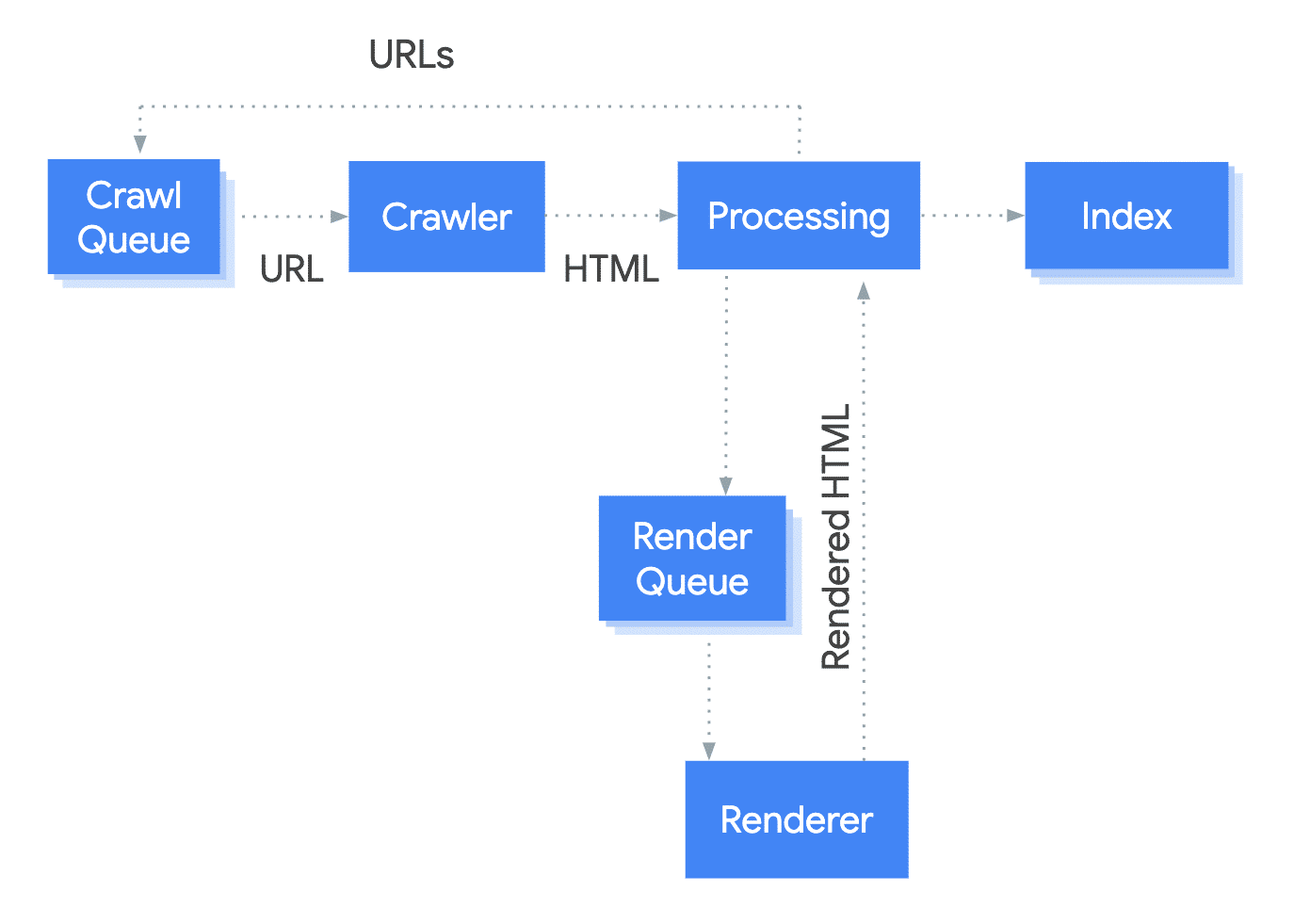
Why does the DOM matter for SEO? Modern search engines like Google render pages using headless browsers (Chromium). They evaluate the DOM, not just the initial HTML response.
Googlebot’s crawl process includes parsing HTML, executing JavaScript, and taking a DOM snapshot for indexing. However, remember:
Googlebot doesn’t interact with pages like humans—content triggered by user actions might go unnoticed.
Other crawlers might not render JavaScript, missing out on JavaScript-dependent content.
With AI agents harnessing DOM data for task execution, a well-structured and accessible DOM becomes ever more crucial.
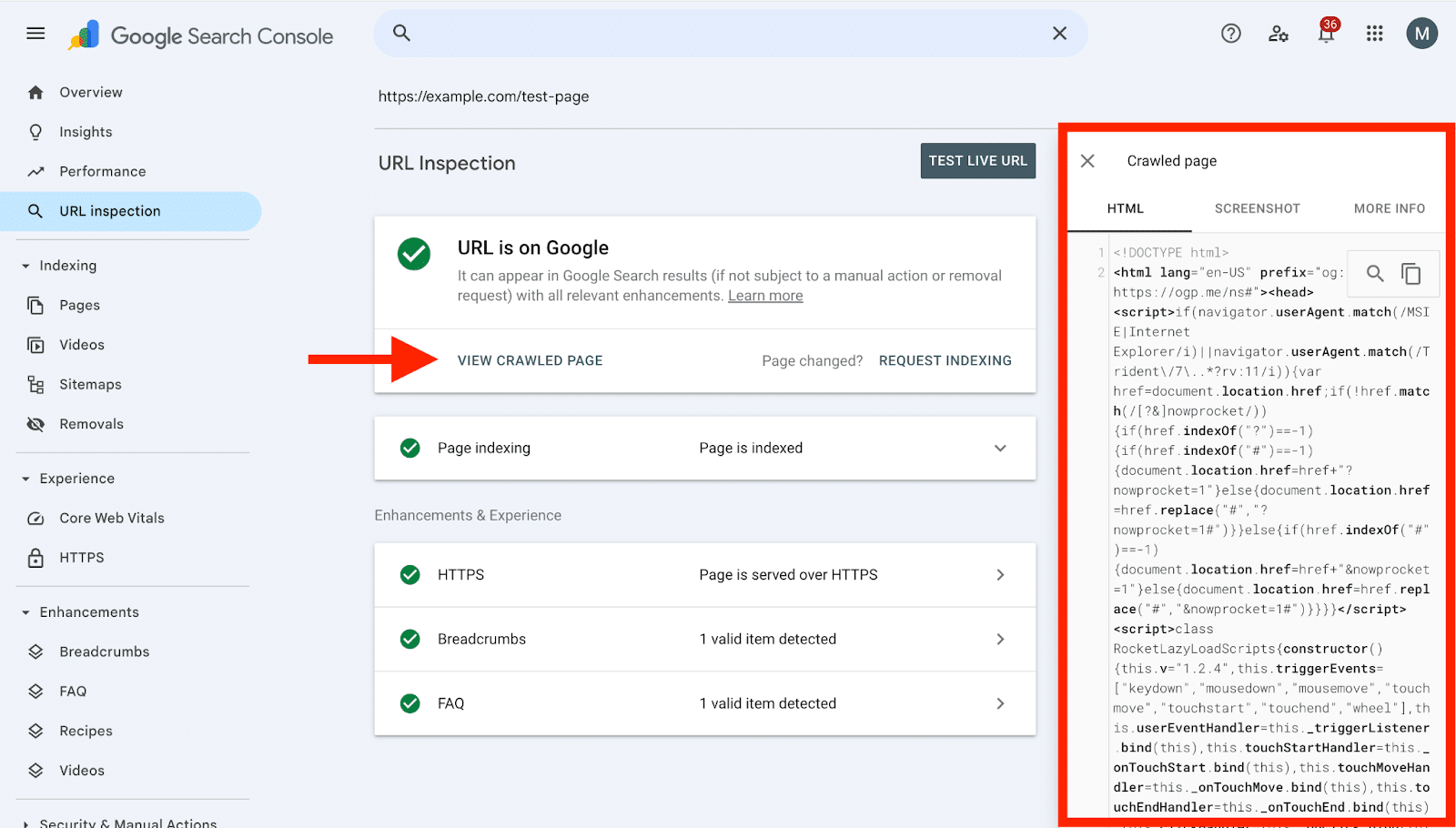
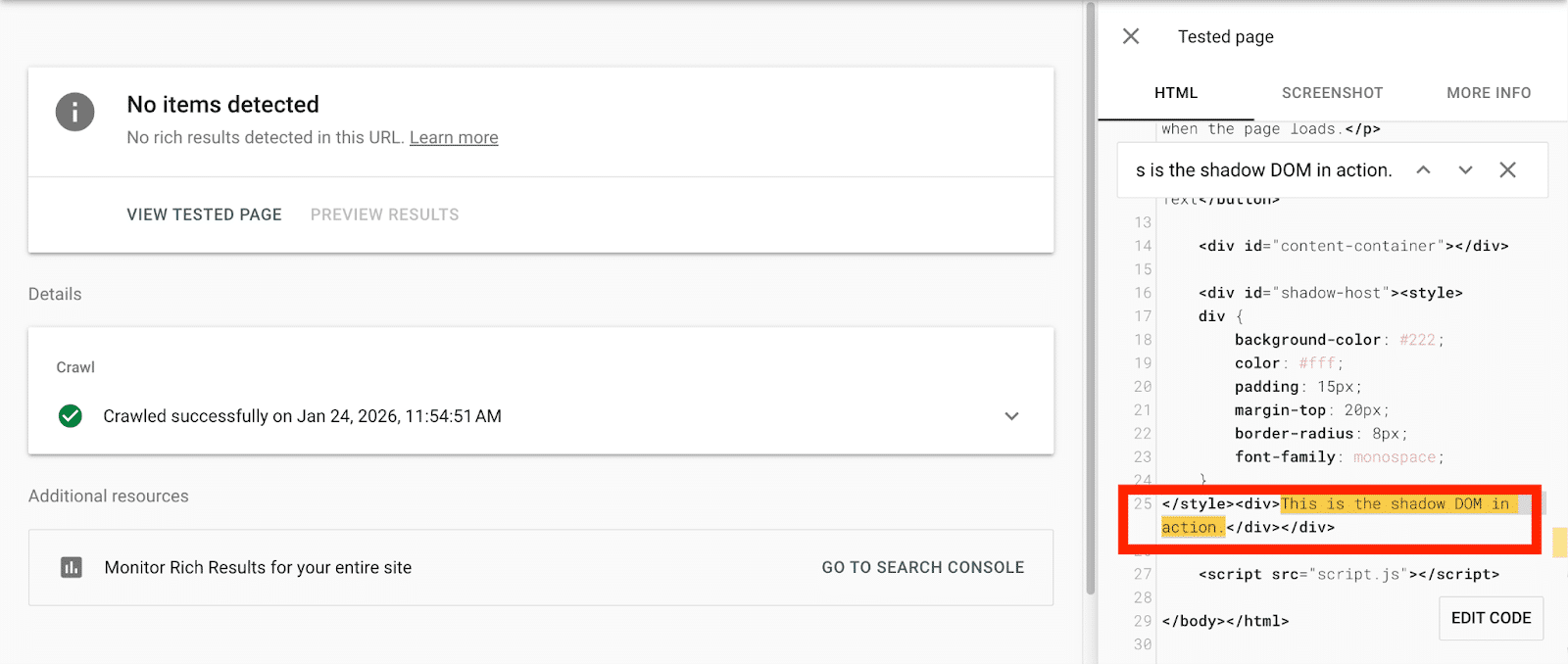
Verifying what Google sees via Google Search Console’s URL inspection tool reveals the rendered HTML version indexed by Google, showcasing any issues.
Using this tool can alert you to discrepancies in what Google indexes versus what you expect, impacting your SEO efforts if overlooked.
For instances without console access, you can resort to Google’s Rich Results Test for similar page insights.
To ensure your webpages are crawled and indexed well, here are some best practices:
Make sure significant content loads in the DOM by default—Googlebot doesn’t interact beyond initial page loads.
Use proper <a> tags to ensure links are crawlable, avoiding JavaScript-based navigation that search engines don’t execute.
Maintain a clear semantic HTML structure. Search engines rely on tags like <header>, <article>, and <section> to understand content organization, unlike ambiguous <div> nesting.
Keep your DOM lean—under about 1,500 nodes—to avoid performance lags and enhance user experience.
In a digital landscape increasingly reliant on AI interactions and advanced crawling methods, understanding and optimizing the DOM is key to maintaining your site’s SEO competitiveness.
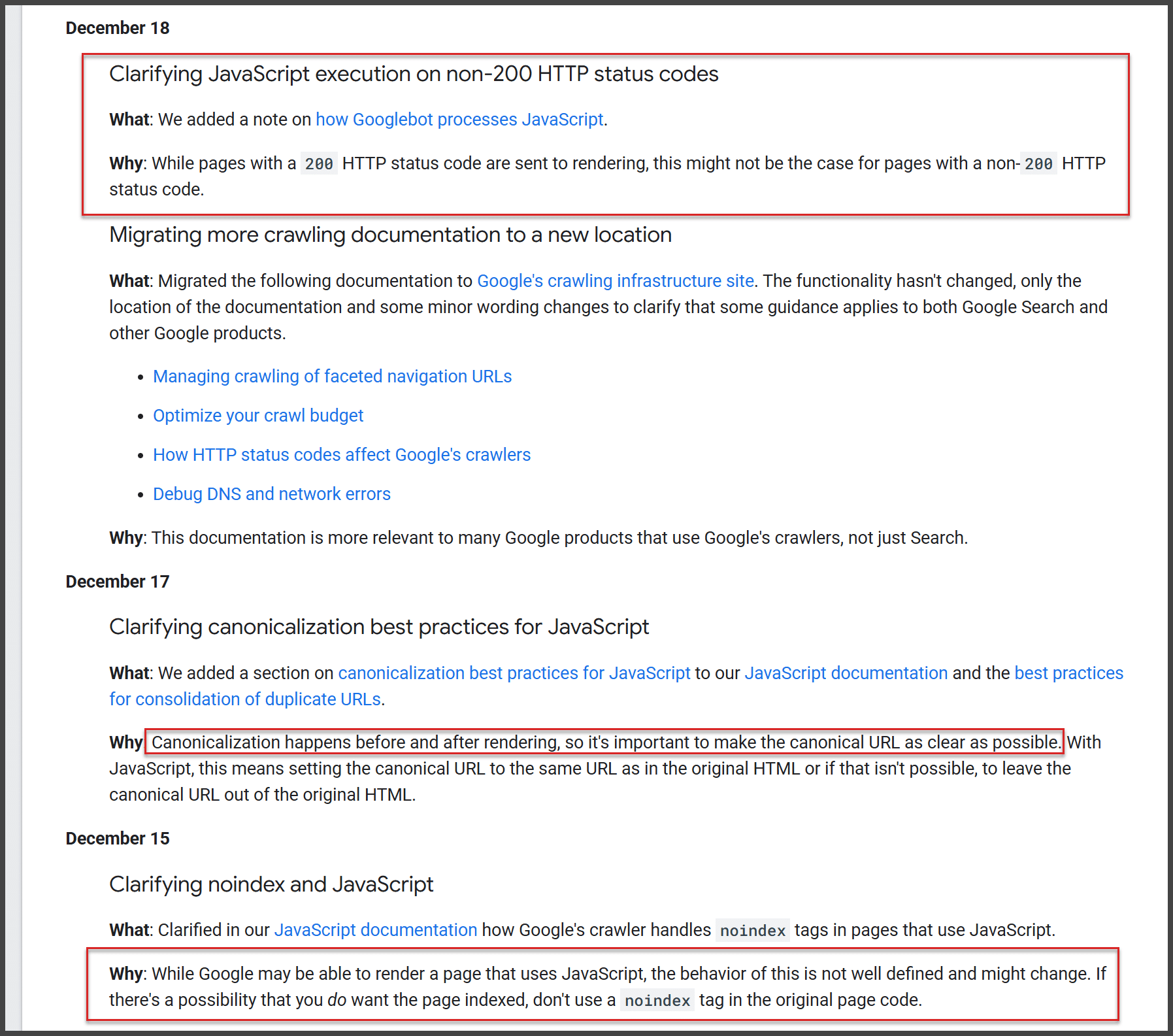
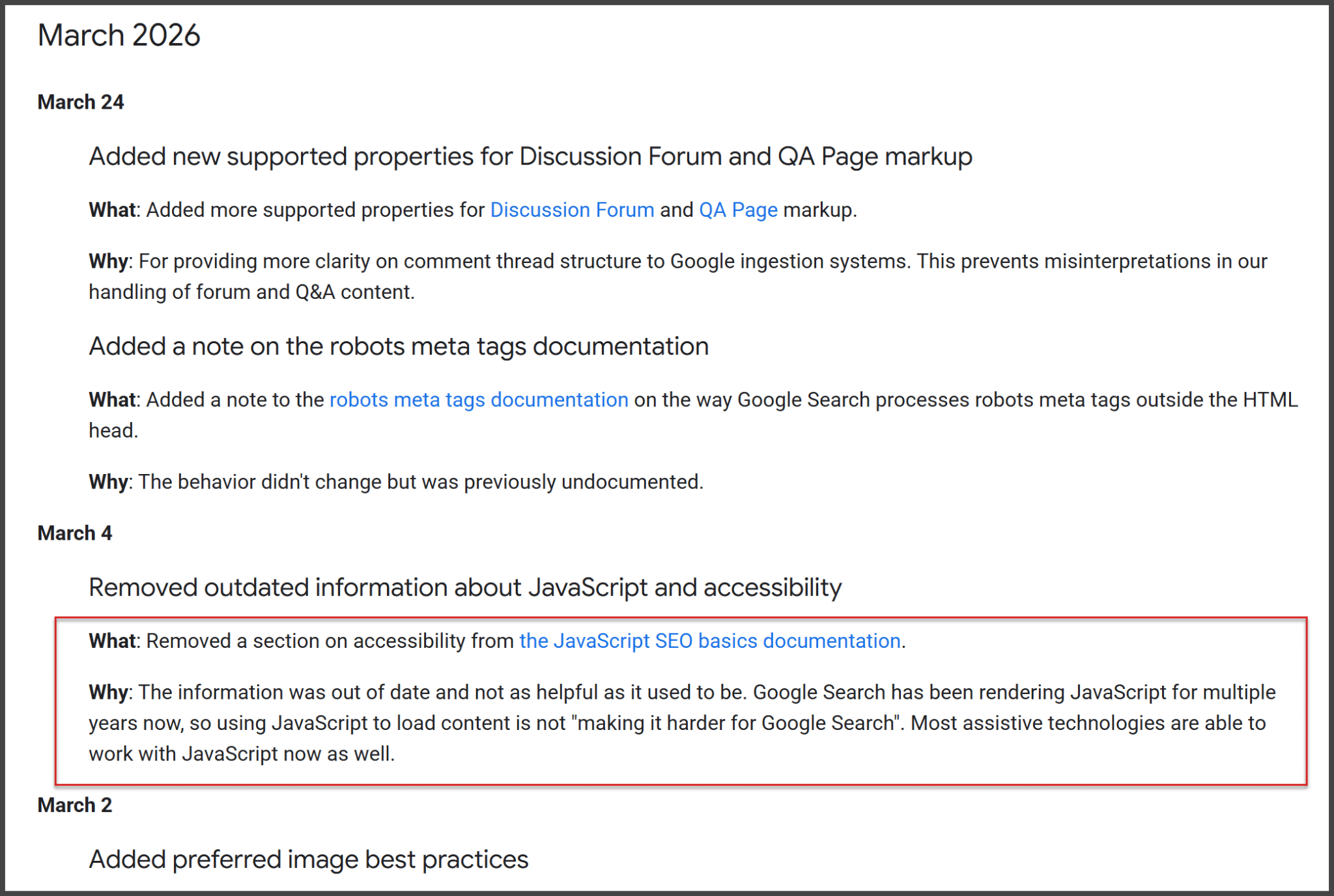
I recently discovered that Google has adjusted its JavaScript SEO guidelines by removing the ‘design for accessibility’ section. This decision was made because the advice was deemed outdated. Nowadays, Google handles JavaScript smoothly.
When Google announced the change, they explained the section was no longer as useful as it once was. Previously, they warned that JavaScript might obscure content from Google, but clearly, that’s not an issue anymore.
The Old Advice. Here’s what the original guidance stated:
“Design for accessibility: Create pages for users, not just search engines. When designing your site, consider users who might not use a JavaScript-capable browser, like those with screen readers or less advanced mobile devices. Test your site’s accessibility by viewing it with JavaScript turned off or in a text-only browser like Lynx. This can help identify content hard for Google to see, such as text in images.”
Why It Was Removed. Google clarified:
“The information was outdated and less helpful. Google Search has successfully rendered JavaScript for years, so using it for content loading doesn’t hinder visibility.”
“Most assistive technologies can now handle JavaScript as well.”
The Importance. Even though Google is adept at processing JavaScript, it’s still critical to verify what Google Search sees. I recommend using the URL inspection tool within Google Search Console to ensure everything checks out.
Remember, while Google and probably Microsoft Bing manage JavaScript efficiently, some emerging AI engines might not render it as effectively.
In 2021, my fascination with Google Discover began when I noticed it generating millions of clicks monthly for publishers. I never imagined how significant it would become.
As I scroll through my feed, it covers everything from soccer, television, Baltimore news, SEO, to global happenings. This variety underscores just how intuitively Discover knows users.
Remarkably, Discover isn’t confined to a single app. It shows up in Chrome’s new tabs, Google app, Android homescreens, on Google.com via mobile browsers, and elsewhere on Google platforms.
Given Discover’s pervasive presence, it’s imperative for us SEOs to leverage the opportunities it presents. Let me guide you on how to do just that.
To start, it’s essential to understand that Discover traffic isn’t suitable for every brand, similar to how search may not be the answer for all.
In Discover, timely content takes precedence. The most successful content is often from reputable sources, particularly major publishers, and is usually time-sensitive. Evergreen content is a rare sight.
Interestingly, sites I’ve collaborated with often draw more traffic from Discover compared to traditional search.
There’s an ongoing decline in Discover traffic due to the influx of social posts and AI summaries, which now occupy space in the Discover feed, pushing aside traditional articles.
Previously, crafting articles about viral social media topics was highly effective for attracting clicks. However, the landscape is shifting, prompting Google to experiment with tracking social platform traffic.
Nevertheless, quality and relevance in content continue to hold significant value. Regardless of technical optimization, content that resonates with user interests will always triumph over less relevant material.
Should your content miss the mark on Discover, assess whether it aligns with what Discover seeks to highlight. And in case of a traffic dip, critically examine your content before delving into technical issues.
Don’t be discouraged from optimizing for Discover. These strategies won’t impact traditional search negatively, and they might unexpectedly boost your Discover traffic, as I’ve observed non-publishers enjoy temporary spikes in clicks.
The three primary factors I scrutinize during new client audits are the Discover publisher profile, article images, and signals from the publisher and author. These form the basis of your optimization process.
Your publisher profile should reflect your website and social profiles accurately. Tools like Damian Tsuabaso’s app, albeit in Spanish, can help identify your profile page.
Discover profiles are linked to your entity’s Knowledge Graph ID and this is crucial for your representation as a publisher. Focus on whether your profile pages accurately portray your brand’s identity.
Incorporate your social media handles into your publisher’s profile. This linkage often requires patience, as manual updates are necessary.
Verify if you have the max-image-preview:large tag, which is vital for showcasing large images in article previews, a detail often overlooked in many CMSs.
Images, especially hero images, should be at least 1,200 pixels wide, aligning with Google’s recommendations for optimal display in Discover.
Ensure your Open Graph image tags are correctly configured and reflect high-quality images instead of logos, enhancing Discover visibility.
Prioritize author transparency by ensuring details such as author photos, bios, and social links are visible, underpinning credibility.
Maintain thorough publisher transparency by linking robust About Us and policy pages, as well as implementing structured data carefully.
Discover thrives on relevance, timely content, and authority. Optimization can’t substitute the necessity for high-quality, suitable content.
Remember, Discover is just the starting point. Uncover larger opportunities for your content through comprehensive audits.
As an SEO professional, Google Search Console is like a trusty sidekick for me. It’s no secret that this free tool from Google provides an in-depth look at how my website performs. It’s like having a pair of X-ray glasses to see through the web’s layers.
With its robust data, I can delve into reports to uncover hidden treasures like clicks, impressions, and Core Web Vitals. It’s like exploring a digital gold mine inside my site.
Search Console’s custom regex filters are my guide through my vast website, ensuring I navigate it seamlessly, page by page.
While I hope to sidestep any SEO-related disasters, especially with Google’s AI advancements, it’s always best to be prepared. That’s why diving into this Search Console guide is essential.
This guide has been crafted for those times when the SEO world becomes unpredictable, much like a thrilling adventure in a post-apocalyptic world.
For instance, as an SEO director, I rely on Search Console daily. It’s my go-to for monitoring content performance, validating technical enhancements, and tracking grows in branded and non-branded queries. It’s integral to my SEO strategy, helping me prioritize tasks with precision.
What does Search Console do? And how does it help SEO?
Search Console stands as Google’s free website analytics and diagnostic platform. It tracks how a site performs in search results, potentially expanding soon into Gemini and AI Mode, offering us what feels closest to first-party search truth.
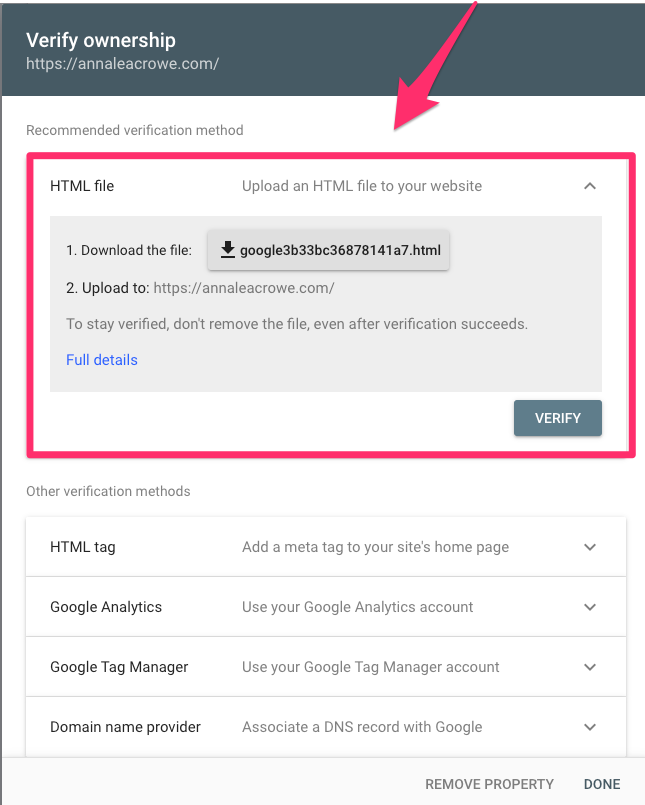
To set it up, it’s as simple as having a Google account and visiting the website. If profiles aren’t visible, simply verify ownership via a domain or prefix URL.
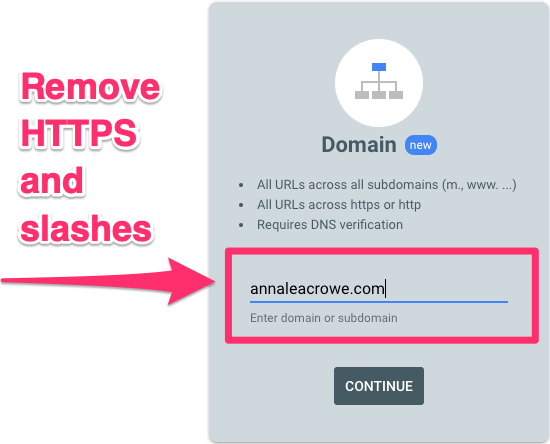
Domain property is the default recommendation
By default, I prefer setting up a domain property. It offers a holistic overview of my site’s search performance, autonomously including HTTP, HTTPS, www, and non-www versions.
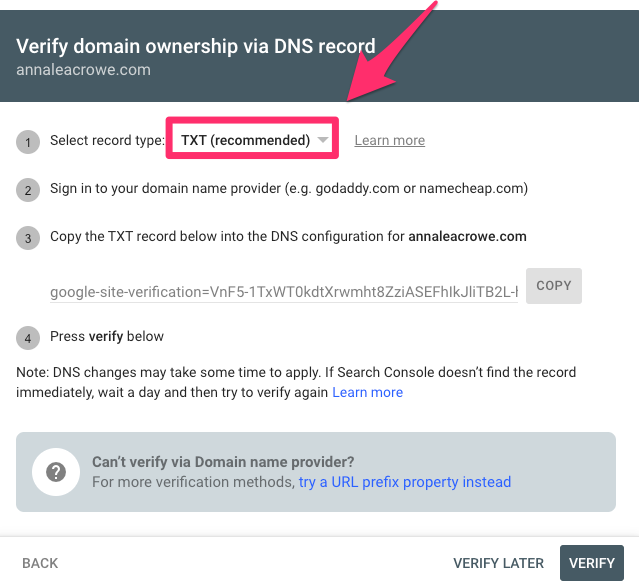
With a verified domain property, I enjoy an uncomplicated setup, often via a DNS TXT record through my hosting provider.
URL prefix property allows you to dissect sections of a site
For more detailed insights, the URL prefix property lets me focus on specific sections like subfolders or subdomains. This is especially handy for producing targeted reports and troubleshooting.
Working with colleagues, such as customer support teams, becomes seamless when I can provide detailed data on specific site sections their work influences.
Key moments in Search Console history
The journey of Search Console has been quite eventful. Launched as Google Webmaster Tools in 2005, it evolved significantly over the years, adding key functionalities like mobile usability reports, security issue improvements, and Core Web Vitals report.
The enhancements continue as we advance into an era increasingly intertwined with AI, making Search Console a dynamic tool for SEO professionals like myself.
Was Google preparing us for AI through Search Console all along?
Reflecting on its evolution, I see a clear narrative. Search Console is transitioning from a mere technical tool into an AI visibility intelligence platform. Google’s approach suggests a future-bound strategy where not just queries but topic clusters define our analysis.
Breakdown of Search Console for SEOs
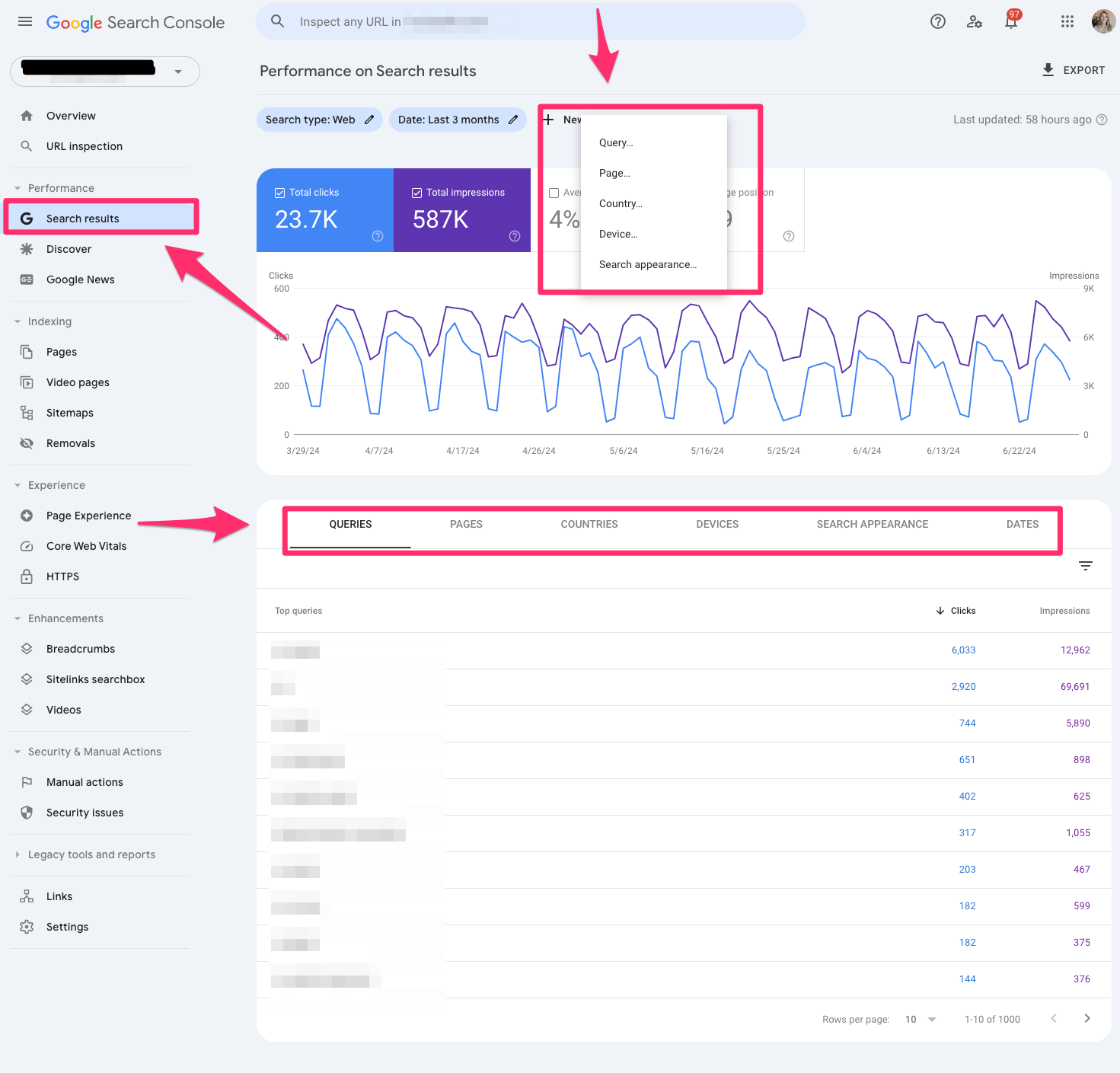
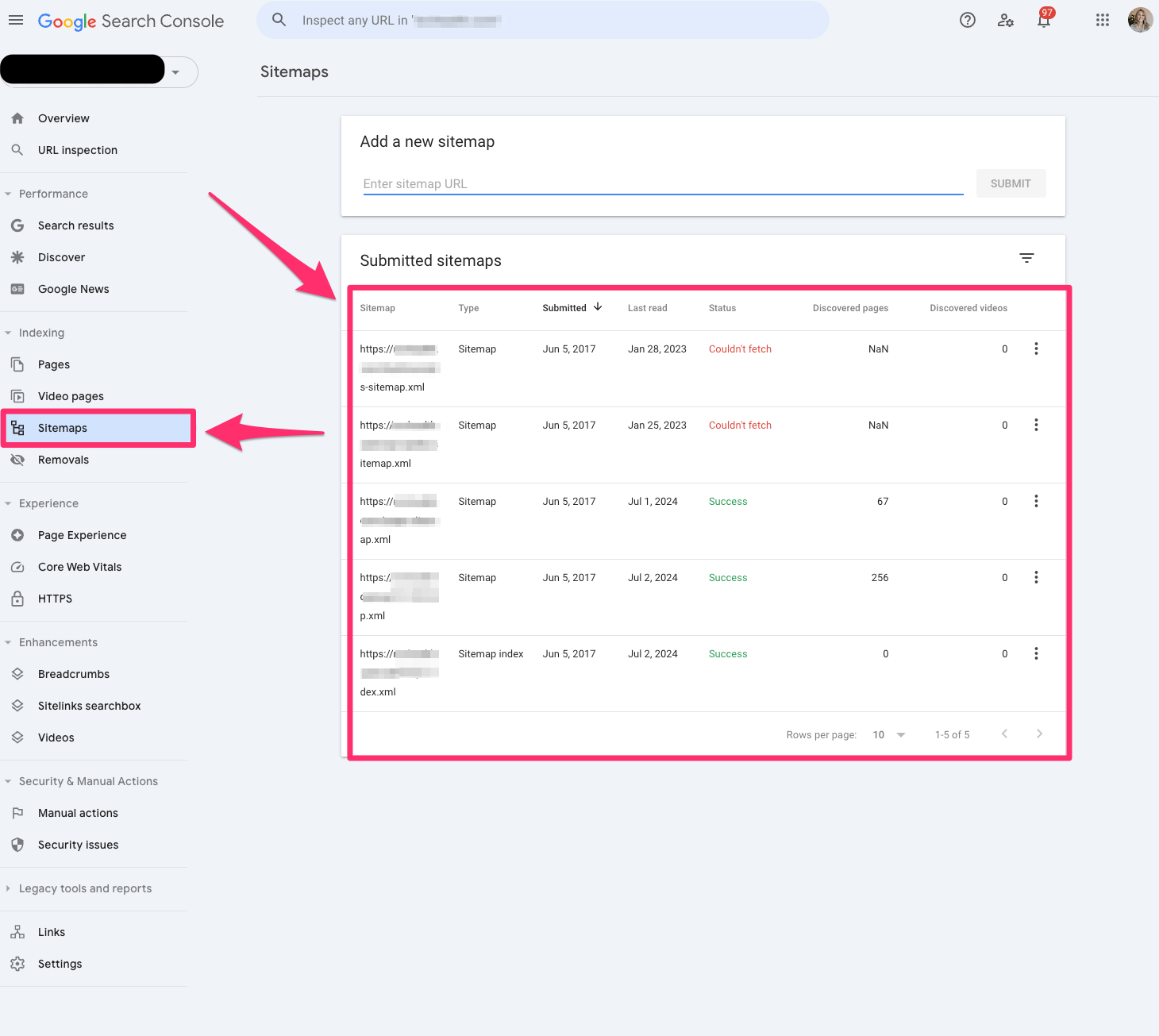
Within Search Console, I explore various features like URL inspection, search results, Core Web Vitals, and sitemaps, each offering unique insights into the health and performance of my sites.
With advanced tools like regex filters and manual action alerts, Search Console stands as a fortress of data, informing my SEO tactics with precision.
Overview
The Overview section quickly outlines key data sets, setting the stage for deeper dives into performance metrics across my websites.
Yesterday, I stumbled upon some exciting news from Cloudflare. They’ve introduced a feature called Markdown for Agents, which provides machine-friendly versions of web content alongside the traditional pages we all see.
Cloudflare describes this update as a proactive measure in response to increasing AI crawler activities and agentic browsing.
When a client requests text/markdown, Cloudflare fetches the HTML from the origin server, converts it right at the edge, and then hands over a Markdown version.
Interestingly, the response includes a token estimate header, which helps developers like me manage context windows more effectively.
Early feedback highlighted not only the efficiency gains but also the potential implications of offering alternate representations of web content.
What’s happening. Being part of the 20% of the web that Cloudflare powers, I learned that Markdown for Agents utilizes standard HTTP content negotiation. If a client sends an Accept: text/markdown header, Cloudflare immediately converts the HTML response on-the-fly to Markdown format. The response, marked with Vary: accept, ensures caches store separate versions.
Cloudflare views this opt-in feature as a shift in content discovery and consumption, benefitting AI crawlers and agents with its structured text that requires less overhead.
They claim Markdown can reduce token usage by up to 80% compared to HTML, which is quite impressive!
Security concern. SEO consultant David McSweeney raised a concern, citing that Cloudflare’s Markdown for Agents feature might make AI cloaking incredibly simple because the Accept: text/markdown header tips off origin servers that the request is AI-related.
Regular requests deliver the usual content, but those for Markdown can trigger a unique HTML response that gets converted for AI consumption, McSweeney explained on LinkedIn.
The worry is that sites might inject hidden instructions, altered product data, or other machine-only content, creating a hidden “shadow web” for bots, unless the header is stripped before reaching the origin.
Google and Bing’s markdown smackdown. Here’s the kicker. Representatives from Google and Microsoft advised against creating separate markdown pages for large language models. Google’s John Mueller noted:
“Given that LLMs have always trained on and parsed normal web pages, it seems obvious they have no issues with HTML. Why serve a page that no end user sees? Plus, if they validate equivalence, why not stick to HTML?”
Microsoft’s Fabrice Canel added:
“Do you really want to double crawl load? We’ll check for similarity anyway. Non-user versions (like crawlable AJAX) are often neglected and broken. Human oversight fixes both user and bot views. Schemas help, and AI makes us even better at deciphering web pages. Less is more in SEO!”
Cloudflare’s feature doesn’t generate another URL but does create varied representations based on request headers.
The case against markdown. Technical SEO consultant Jono Alderson pointed out that once a machine-targeted representation exists, platforms must choose to trust it, verify it against the human version, or outright ignore it:
“Flattening a page to markdown doesn’t only remove clutter. It strips away judgment and context.”
“The instant you publish a machine-exclusive page representation, you craft a secondary candidate version of reality. Regardless of source promises or claims of identical content, a system now views two representations and must determine the true reflection of the page.”
Why we care. With Cloudflare’s advancements, AI ingestion might become more cost-effective and streamlined. But does serving distinct content to humans and crawlers verge on cloaking? Stay tuned…
Is this the new technical SEO frontier? This question is top of mind for many of us as Google has recently unveiled an early preview of WebMCP, a protocol shaping the way AI agents engage with websites. According to André Cipriani Bandarra from Google, “WebMCP aims to provide a standard way for exposing structured tools, ensuring AI agents can perform actions on your site with increased speed, reliability, and precision.”
WebMCP offers developers the capability to communicate with LLMs through our websites about the specific actions that various buttons and links should initiate. With this protocol, websites can publish a “Tool Contract” using the new browser API, navigator.modelContext. This means rather than leaving the AI to guess, our websites can present a structured list of functions, like buyTicket(destination, date), allowing the AI to execute these functions directly.
Structured interactions for the agentic web. WebMCP introduces two new APIs enabling browser agents to act on behalf of users:
Declarative API: This offers standard actions that can be simply defined within HTML forms.
Imperative API: For more complex, dynamic interactions that need JavaScript execution.
These APIs serve as a crucial bridge, making our websites “agent-ready” and facilitating more reliable and high-performance agent workflows compared to raw DOM actuation.
Use cases that Google has put forward highlight how AI agents can tackle complex tasks efficiently and confidently for users:
Travel: With structured data, agents can help users search for, filter, and book the exact flights they want, ensuring accuracy in results.
Customer support: Agents can automatically populate detailed customer support tickets, filling in all required technical details without user intervention.
Ecommerce: Enhancing shopping experiences where agents can locate, configure, and navigate purchasing options flawlessly.
How to access the preview. If you’re interested in trying out WebMCP, you can apply for the preview through this link.
Why we care. The advent of agentic experiences marks a significant shift in search and potentially SEO. Esteemed voices in the industry, such as Dan Petrovic and Glenn Gabe, have highlighted this as a pivotal transformation, comparable to the impact of structured data and described it as a big deal.
Exploring these cutting-edge protocols could be extremely valuable for anyone keen on staying at the forefront of SEO developments.