For most of the past decade, I treated organic marketing as a visibility game. I wanted brands on Page 1, inside featured snippets, and in front of the people already searching.
That north star has moved.
When I spoke at SMX Advanced on June 5, the question I put to the room was not simply, “How do I get a brand found?” The harder question was, “How do I get that brand chosen?”
In 2026, those answers are no longer the same. The distance between being discovered and being selected is where I see many brands losing ground.
In AI search, my reputation shows up first
The old user journey was messy and multi-step. People explored, compared, checked reviews, read Reddit threads, visited comparison sites, and moved toward a decision over time. Now, a single AI prompt can compress much of that process into one synthesized answer.
AI search does not reward the brand that shouts the loudest in paid media or stuffs the most keywords into metadata. I see it rewarding the brand with the strongest reputation in the places that matter. Reddit discussions, review sites, comparison pages, expert commentary, forums, and editorial coverage are all being absorbed by large language models and blended into recommendations.

In other words, my brand is no longer defined only by what I say about it. It is shaped by how AI understands it, and AI is reading what everyone else has said, too.
Owned content on websites and social channels will always carry a promotional bias. AI systems look for outside validation to support, challenge, or clarify those claims.
That changes the work of organic marketing. I can no longer stop at visibility. I have to build a brand that is found, correctly understood, and ultimately chosen. Those are three separate challenges, and I need a strategy for each one.
Found: I need to appear where my audience actually looks
The first challenge is still discoverability, but the canvas is much wider than Google. People now discover brands through ChatGPT, Reddit, YouTube, TikTok, Google, Quora, LinkedIn, and word of mouth. I have to understand which of those entry points matter most to the specific audience I want to reach.
That starts with mapping the sources my audience genuinely trusts: the publications, platforms, communities, creators, analysts, newsletters, and peer groups that influence their decisions. The intersection of semantic relevance, domain authority, and audience affinity tells me which third-party properties are worth pursuing.
For one B2B audience, that might mean Wired, Tom’s Guide, or an active LinkedIn group where buyers discuss vendors in a specific vertical. For another, it might be r/smallbusiness or a Substack newsletter with 40,000 engaged subscribers.
Once I know where the audience spends time, I can create useful content, earn credible mentions, and participate in the conversations already shaping decisions. This is audience-first, performance-driven PR and organic strategy, not generic brand awareness.
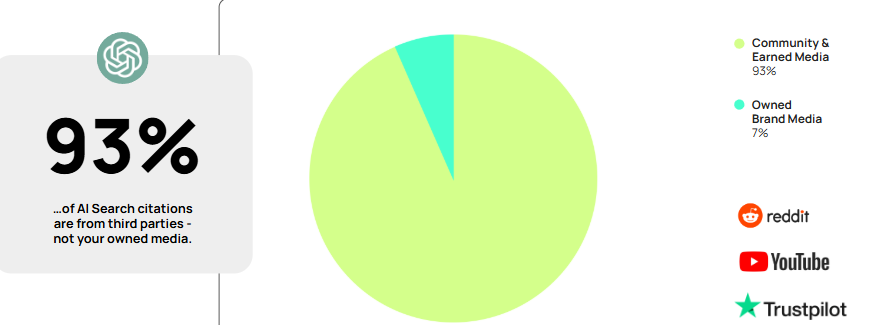
The data makes the case even stronger. Across the top commercial sectors analyzed, 93% of AI search citations came from third-party sources. If I only invest in content on my own domain, I risk being invisible to the systems now doing much of the brand discovery work.
Understood: I need consistent signals everywhere
Getting found matters, but it is not enough on its own. If machines are surfacing my brand, they also need to understand it accurately.
LLMs do more than crawl my website. They build a consensus picture from everything available online: reviews, Reddit discussions, press coverage, YouTube commentary, Trustpilot ratings, forum threads, and more. If those signals conflict with the story I am telling about myself, I have a real problem.
If I claim premium positioning while thousands of articles question whether the brand is truly luxury, heavy discounting is part of the public record, and review scores are poor, AI is unlikely to recommend that brand as a premium option. The model has read the broader story, not just the homepage copy.
That is why brand messaging consistency has become an SEO issue. Owned, earned, and paid content all need to reinforce the same core associations. Conflicting signals do not just confuse customers; they can weaken AI visibility.
Digital PR plays a critical role here because it helps shape the external narrative. Through strategic media placements, expert commentary, and search-informed coverage, I can influence what journalists write, what audiences remember, and what models learn.
I also have to think beyond one obvious keyword. The query fan-out, or the range of prompts a potential customer might use, requires positive and consistent answers across every touchpoint an LLM might evaluate.
Chosen: I need trust signals that influence the decision
The third challenge is the hardest and probably the most important. Trust has always been an SEO currency, but as clicks decline and zero-click search becomes more common, trust matters even more.
According to an Ahrefs study, brand appearance in AI Overviews is most strongly correlated with branded web mentions. In practical terms, that means the number of times a brand is positively named across authoritative third-party sources is becoming one of the most powerful signals organic marketers can influence.
That is also the core output of strong digital PR. Based on the last 4,000 pieces of U.S.- and U.K.-based coverage driven for clients, 91% of AI search citations included expert insight rather than branded content or product pages.
That tells me expert-backed, editorially independent coverage is critical. Internal experts are now one of the most valuable assets a brand has. Brands that invest in real thought leadership, original research, and data-backed studies are giving both people and AI systems stronger reasons to trust them.
The three content formats I see consistently supporting LLM inclusion are product roundups and listicles that place a brand inside trusted “best of” editorials, reliable data-backed research that journalists and LLMs can cite, and expert thought leadership that positions real people as credible voices in their category.

What does not work is chasing inauthentic mentions through artificial link schemes, fake expert personas, or manufactured coverage. Google has already flagged these kinds of tactics in its GEO guidance, and models are getting better at distinguishing genuine authority from manipulated signals.
The reputational risk is also high. If I try to manufacture authority and get caught, I do not just lose visibility. I damage the trust I was trying to build.
This cannot be a one-time effort. Multiple studies, including research from Waseda University, have identified a correlation between AI brand visibility and content recency.
Brands that maintain a steady flow of credible, expert-backed third-party coverage do not just appear more often in AI responses. They appear with more confidence.
Frequency and freshness both matter. A one-off PR campaign is not enough. I need to treat credible external validation as an always-on strategic investment.
The framework I use in practice
When I think about brand discovery in 2026, I come back to three words: found, understood, and chosen.
Found: I map the audience’s real sources of influence and make sure the brand is credibly present across the fragmented ecosystem where discovery now happens.
Understood: I work to make sure everything said about the brand tells a consistent story, matches the desired positioning, and reinforces the associations that drive preference.
Chosen: I continuously build genuine trust signals through earned coverage, expert commentary, and third-party validation, so that when a person or machine compares the brand with a competitor, credible external evidence tips the decision in my favor.
The brands winning in organic search right now have not unlocked some secret technical trick. They have built reputations worth recommending, and they have made sure machines can understand those reputations clearly.
That is where I believe organic marketing has to go next. Instead of chasing the algorithm, I need to build something worth finding, worth understanding, and worth choosing.
Inspired by this post on Search Engine Land.