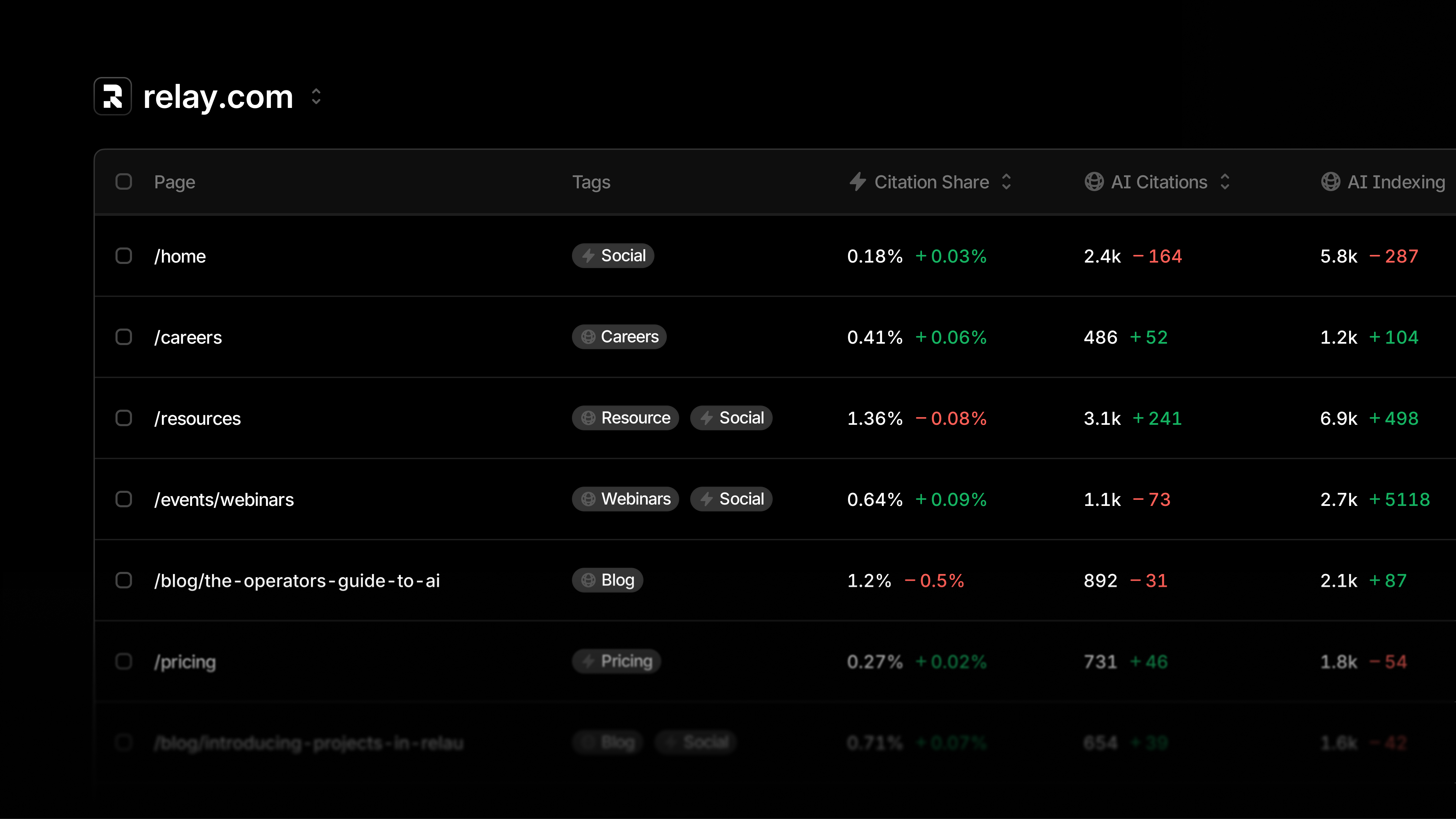
I’m introducing Pages in Profound—my single command center for monitoring content citations, tracking bot activity, and understanding page health.
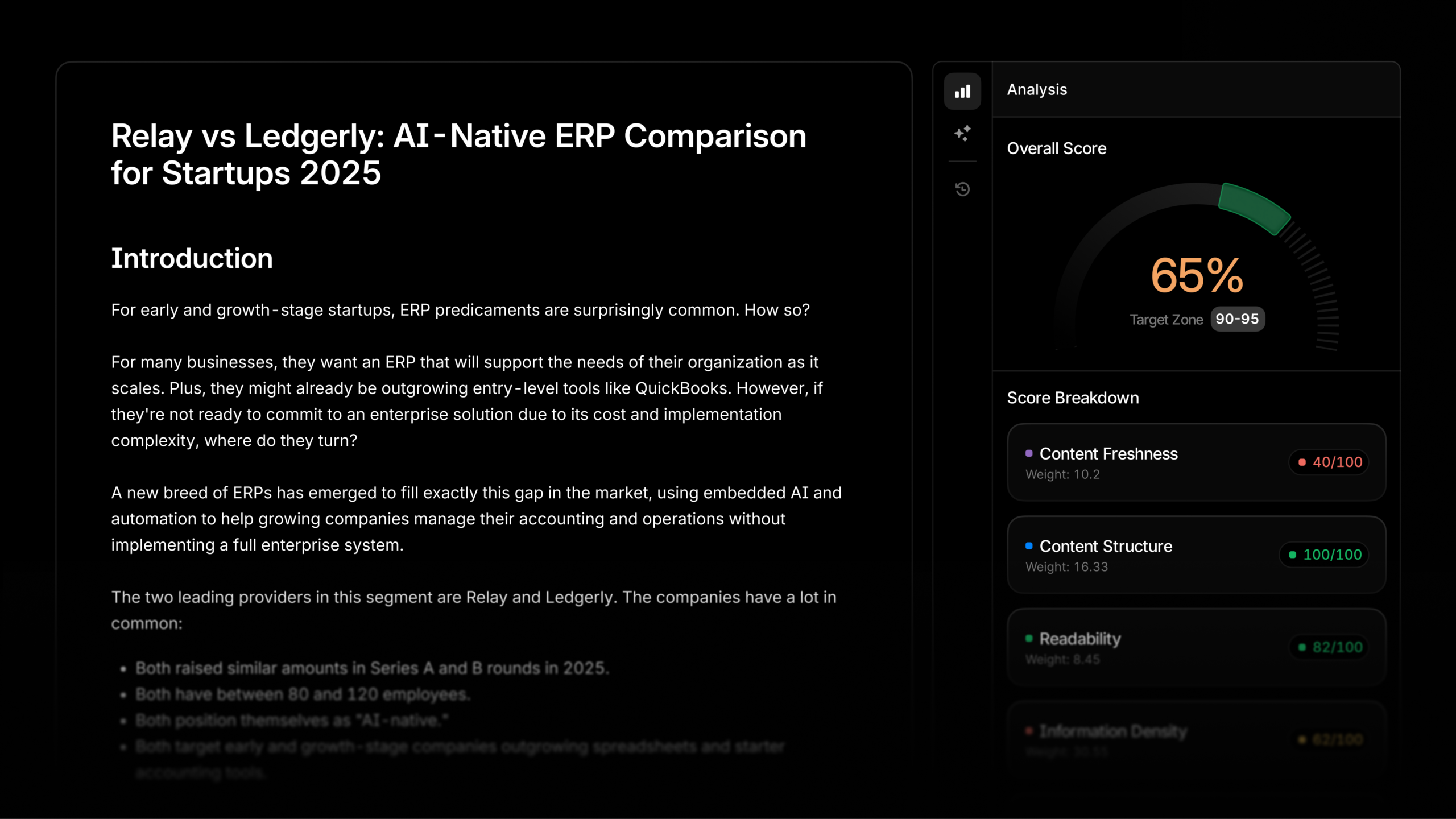
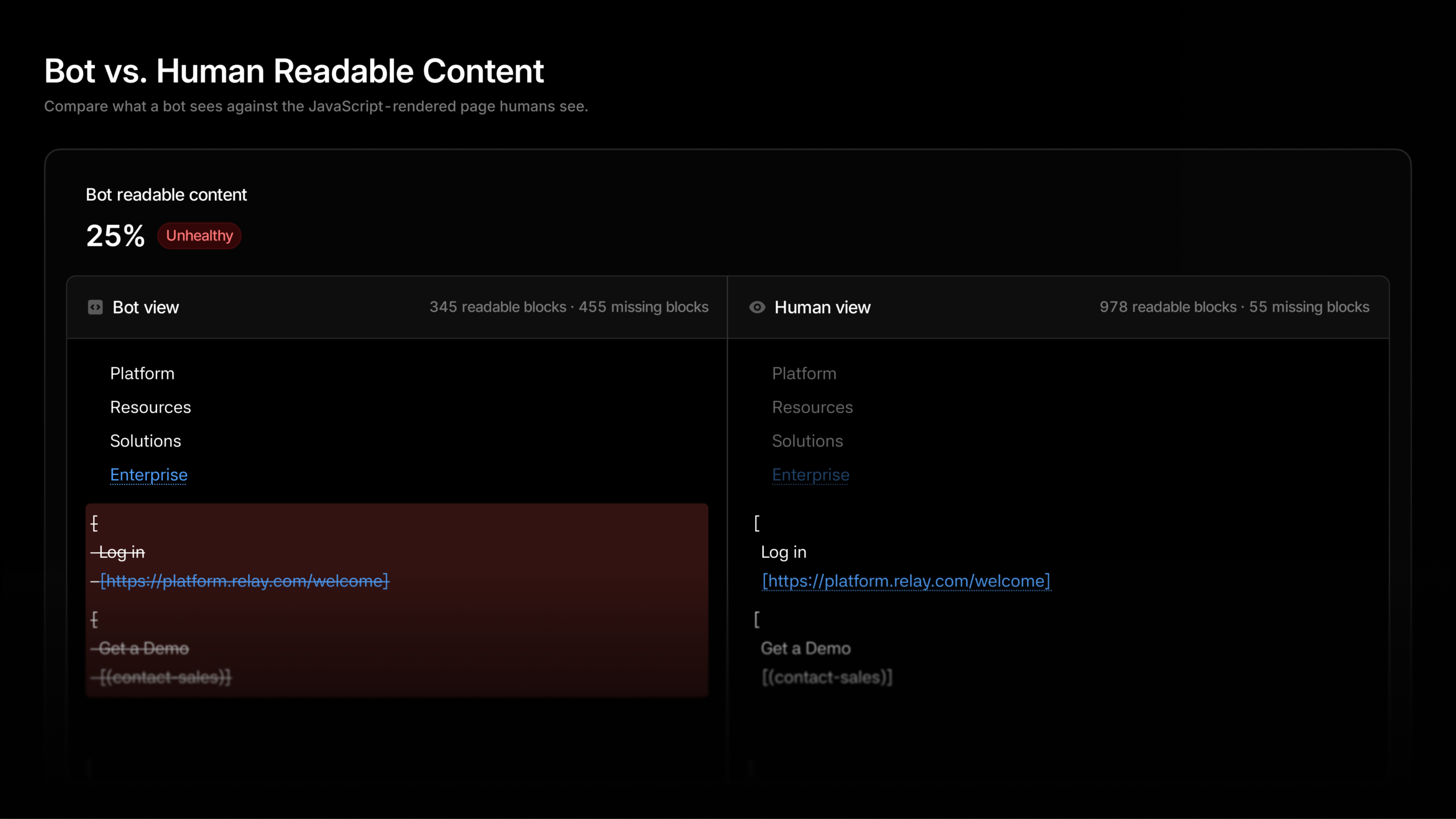
Inspired by this post on Try Profound Blog.

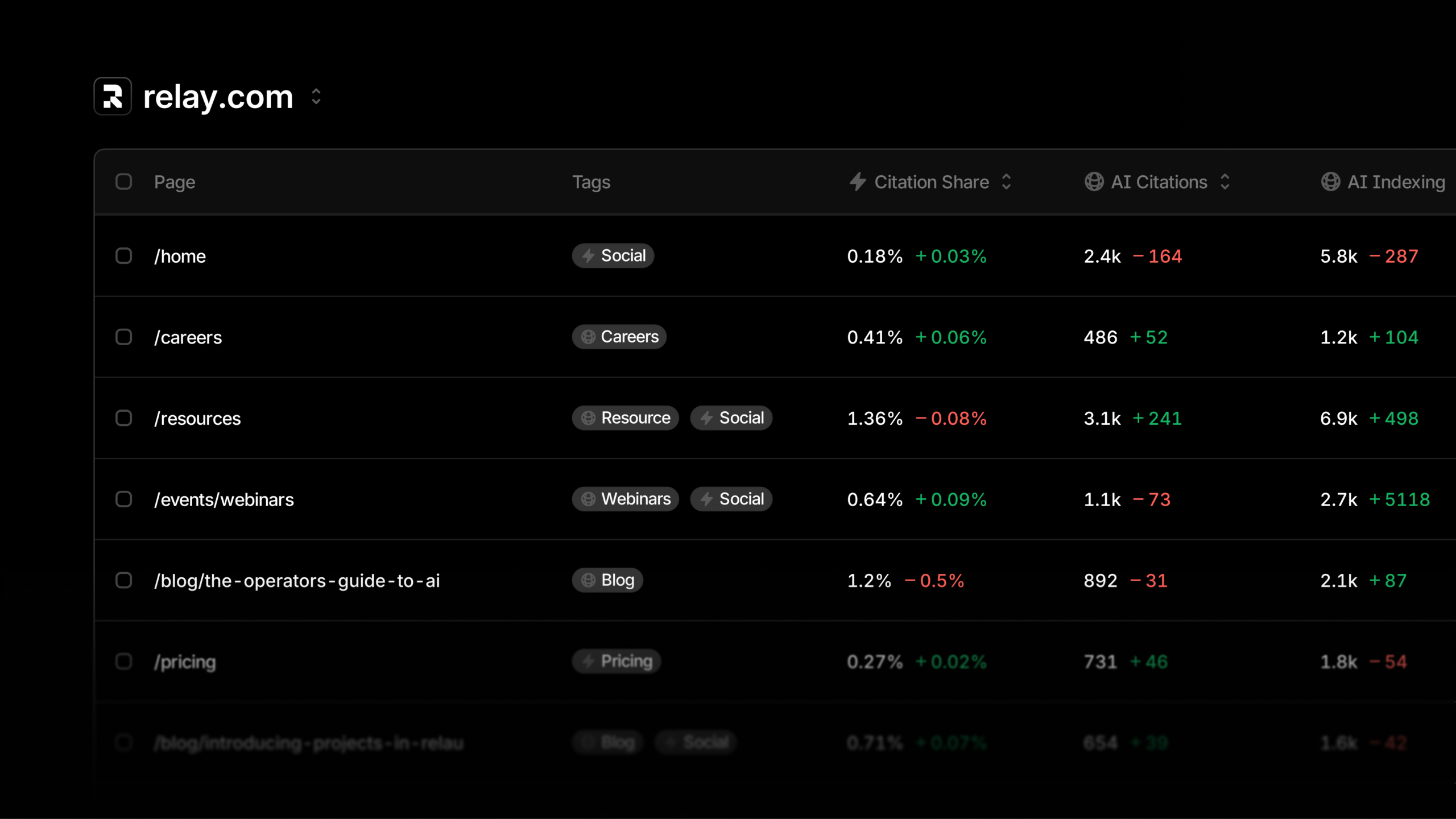
I’m introducing Pages in Profound—my single command center for monitoring content citations, tracking bot activity, and understanding page health.
Inspired by this post on Try Profound Blog.

Have you ever wondered how Google is ensuring the authenticity of AI bots? I recently stumbled upon Google’s latest experimental method, Web Bot Auth, which aims to address exactly that. This project is currently in a limited testing phase, specifically for AI agents hosted on Google’s infrastructure, but it could be expanded in the future.
In Google’s new help document, they clarify that Web Bot Auth is a “new cryptographic protocol that helps websites validate that bots are authentic.” This innovative approach is designed to automate the authentication of AI Agent bots, distinguishing between genuine and fraudulent bots.
Limited test phase: Google’s team mentions they are “testing the protocol with some AI agents hosted on Google infrastructure.” It’s important to note that not all Google user agents are currently using Web Bot Auth, and the company isn’t signing every bot request with this protocol just yet.
During this gradual rollout, Google advises us to keep using IP addresses, reverse DNS, and user-agent strings alongside Web Bot Auth, as not all traffic is currently signed.
What is Web Bot Auth? Defined as “an experimental cryptographic protocol used to authenticate requests sent by bots,” this method moves away from self-reported headers and IP addresses. Instead, it allows agents to sign their requests cryptographically.
According to Google, Web Bot Auth offers several benefits:
Why this matters to us: As AI agents continue to proliferate online, managing access to our sites becomes increasingly complex. This new authentication method could effectively distinguish credible AI agents from deceptive ones, ensuring the right entities access our data.
Since Web Bot Auth is still “experimental,” I’ll be keeping an eye on its development. It might just transform how we manage AI bot access in the future.
Inspired by this post on Search Engine Land.

Have you ever wondered how all those Claude bots from Anthropic handle your site’s data? Well, I’ve delved into their latest update, which offers insights into their AI training, real-time queries, and what happens when you choose to block them.
Anthropic recently enhanced their crawler documentation, providing clarity on how Claude bots interact with websites and how you can regain control by blocking them.
Why should you care? If you’re like me and manage content, you’ll want to manage how AI systems utilize your work. Anthropic smartly divides bots into training crawlers, user-initiated fetches, and search indexers. Blocking just one won’t impact the others, so make informed choices based on visibility and training implications.
Let’s meet the robots: Anthropic employs three unique user agents. First up, ClaudeBot gathers public online content for training their AI models. Blocking it means your site’s content won’t be in future AI datasets.
Next, there’s Claude-User, which fetches pages when someone asks Claude a question necessitating site access. Block this bot and lose out on visibility in user-driven response queries.
Finally, Claude-SearchBot improves search results by indexing. If you decide to block it, it may affect your content’s visibility and accuracy in Claude-enhanced search responses.
Curious about blocking these bots? They comply with standard robots.txt directives, including “Disallow” and “Crawl-delay”. To block a bot site-wide, use:
User-agent: ClaudeBot
Disallow: /
Bear in mind, each bot and subdomain you wish to limit needs its own directive. Be cautious with IP blocking; these bots operate via public cloud IPs, which might interfere with robots.txt access, and IP details aren’t disclosed by Anthropic.
Explore Anthropic’s documentation here: Does Anthropic crawl data from the web, and how can site owners block the crawler?
Inspired by this post on Search Engine Land.

I recently explored Google’s SearchGuard, an advanced system that safeguards Google Search from bots. This groundbreaking technology has been thrust into the limelight due to a lawsuit against SerpAPI, revealing how Google differentiates between human users and automated scripts.
After meticulously dissecting the JavaScript code, I gained rare insights into how Google distinguishes humans from automated scrapers in real-time.
What happened: On December 19, Google filed a lawsuit against SerpAPI, accusing them of bypassing SearchGuard to extract copyrighted data from Google Search results on a colossal scale. Instead of focusing on terms-of-service breaches, Google cited DMCA Section 1201, emphasizing anti-circumvention clauses.
This case underscores what Google deems worth protecting, which is crucial for anyone in the SEO and marketing sectors who might be using tools that interact with Google Search.
Why we care: Understanding SearchGuard is vital because any large-scale automation with Google Search invokes this system. If you’re using scraping tools, this is the barrier they encounter.
Here’s where it gets interesting: SerpAPI isn’t just another scraper. OpenAI utilized Google search results, obtained through SerpAPI, to enhance ChatGPT’s capabilities. Although OpenAI’s request for direct access to Google’s index was flatly denied in 2024, they still needed real-time data.
This situation highlights a strategic move by Google, focusing on a key element in the competition’s data supply chain.
In investigating SearchGuard, I fully decrypted version 41 of the BotGuard script, which started with an unexpected greeting:
Anti-spam. Want to say hello? Contact botguard-contact@google.com
Don’t let the friendly tone fool you; behind it lies one of the most complex bot detection systems ever created.
BotGuard vs. SearchGuard: BotGuard, internally termed Web Application Attestation (WAA), shields most Google services. Google’s legal complaint disclosed that the specific system guarding Search is known as SearchGuard, which when implemented in early 2025, disrupted nearly all SERP scrapers.
Unlike traditional CAPTCHAs, BotGuard operates invisibly, seamlessly analyzing user behavior using sophisticated algorithms to separate bots from people.
It leverages a highly protected bytecode virtual machine to ensure it remains impervious to reverse engineering.
How Google knows you’re human: The system evaluates multiple behavioral metrics in real-time, including mouse movements, keyboard rhythm, scroll behavior, and timing jitter, painting a comprehensive picture of a user’s natural interactions.
Google observes the fluidity of mouse motions, capturing deviations that indicate a human touch, unlike the straight paths typical of bots.
A perfectly linear mouse action raises alarms, as it is atypical of human movement, usually characterized by imperfections.
Keyboard rhythm: Everyone types differently. Google captures inter-keystroke intervals, error patterns, and post-punctuation pauses to form a user’s unique typing ‘fingerprint.’
The aspects of natural scrolling and timing jitter are also scrutinized, as context-specific nuances help discern human from machine.
Google’s system even enlists over 100 HTML elements for browser environment fingerprinting to further ensure authenticity.
Performance monitoring: Google captures intricate details such as navigator properties, screen metrics, and engagement with browser APIs for an exhaustive analysis.
Despite efforts to outsmart it, SearchGuard employs cryptographic measures similar to those developed by the NSA to protect its integrity, making circumvention fleeting at best.
The statistical ingenuity behind SearchGuard: Algorithms like Welford’s and reservoir sampling give SearchGuard the upper hand, continuously refreshing a composite profile of expected user behavior.
SerpAPI’s stance: Julien Khaleghy, CEO of SerpAPI, notes Google never reached out before filing the lawsuit, suggesting it’s an attempt to stifle competition from innovative services using their platform to power advanced applications.
Google’s assertiveness poses a monumental challenge to the SEO industry, redefining how anti-scraping measures might be perceived legally. Should SearchGuard be recognized as a legitimate protective measure under DMCA, it could set significant precedent.
Inspired by this post on Search Engine Land.