
As a marketer, I know how it feels to operate with a hidden skepticism tax. Trusting marketing data can be a challenge, often leading to countless hours spent cleaning spreadsheets and reconciling conflicting reports. And let’s not forget second-guessing those attribution models and AI outputs.
This lack of trust slows down execution, weakens team alignment, and results in decisions built on shaky foundations. A prime example is branded search, which often undeservedly takes credit for conversions that were likely to happen anyway. It’s like crediting a revolving door for everyone who enters a building. This gap between correlation and causation highlights a broader issue in modern marketing—a reliance on fragmented or low-confidence data.
The key isn’t just collecting more data, but building a foundation of data we can actually rely on—through verified identities, unified reporting, cleaner pipelines, and a robust measurement framework designed to distinguish true signals from noise.
Let’s break down some core concepts behind building this foundation and the types of data environments they foster.
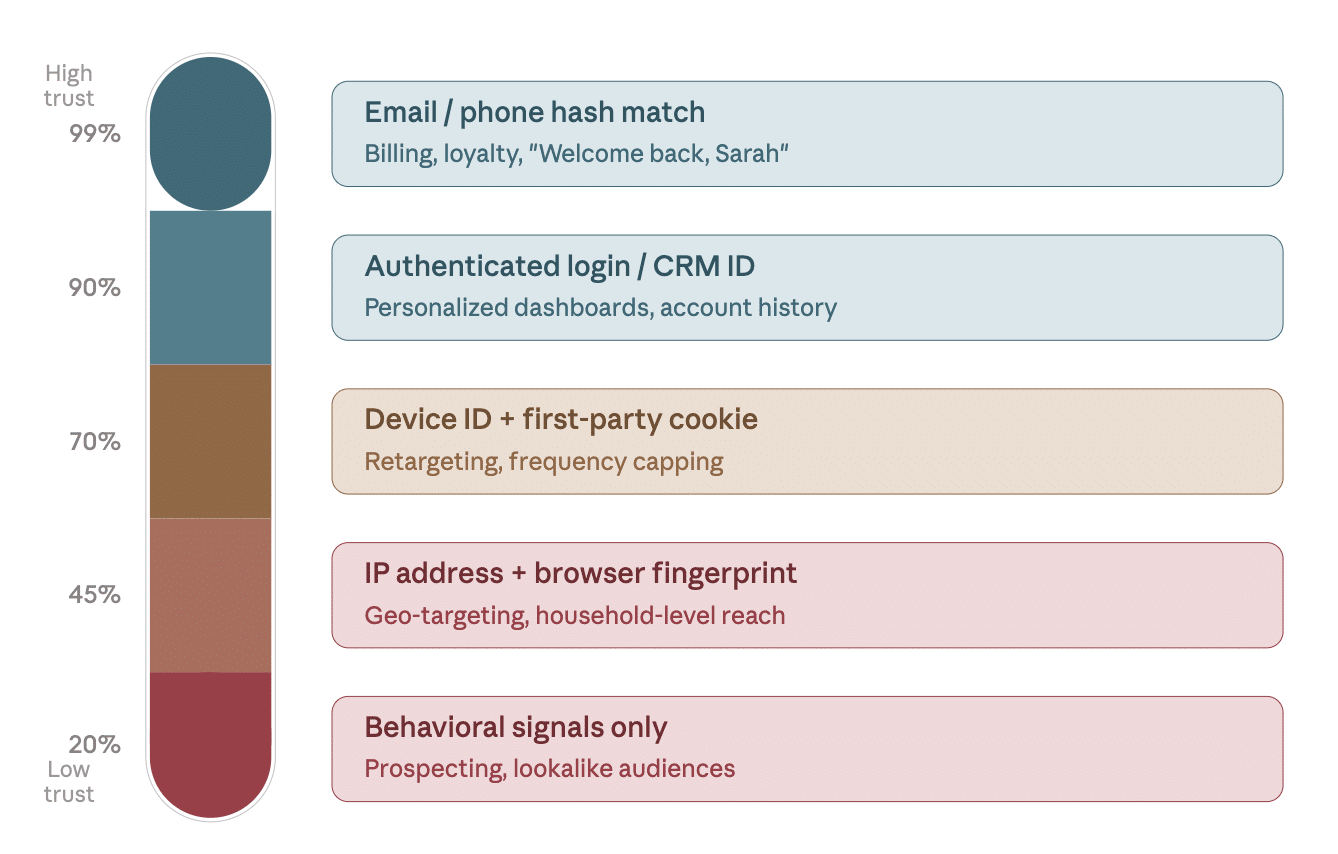
Probabilistic vs. Deterministic
Consider a coffee shop loyalty app to explain probabilistic vs. deterministic data: When a customer logs in and orders, you know it’s Sarah. That’s deterministic. Conversely, if someone on the same Wi-Fi browses your menu without logging in, you might assume it’s Sarah based on the device and location signals—it’s probabilistic. Both have their uses, but assumptions can lead to inaccurate messages, like sending a “Happy Birthday, Sarah!” notification without certainty.
Using a data-to-confidence mapping, like the identity confidence thermometer, can help explain this concept effectively to clients.
Deterministic data sits at the top of the thermometer (100% confidence), with various probabilistic confidence levels descending down to the bottom.

Siloed vs. Holistic
Imagine the old tale of blind folks describing an elephant: Marketing describes the trunk as a hose, Sales sees the leg as a tree, and Finance calls the tail a rope. This illustrates the pitfalls of siloed data in ROI reporting. A holistic approach ensures everyone sees the whole elephant.
In a more practical example, a B2B SaaS company runs LinkedIn ads. Marketing registers 5,000 form fills, Sales finds only 2,000 worthy leads in the CRM, and Finance reports 1,200 closed deals attributed to organic traffic due to broken UTMs. Different teams, different truths, zero confidence.
Here’s what these inconsistencies look like, contrasted with a unified data spine approach.
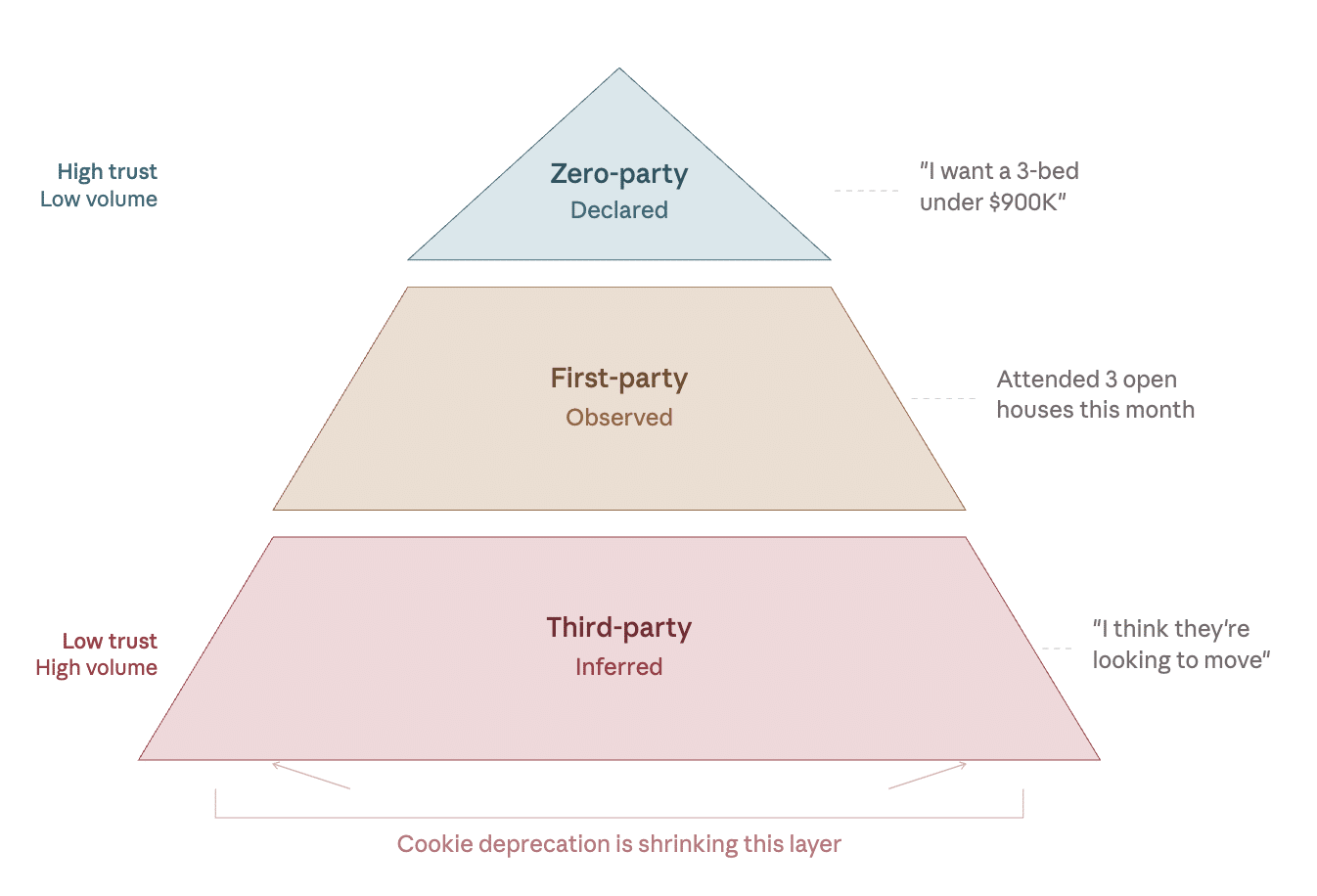
Third, First, and Zero-Party Data
Think about buying a house:
- Third-party data: a nosy neighbor speculating about a move—it’s just hearsay.
- First-party data: a realtor who sees them attending open houses—observed behavior.
- Zero-party data: the buyer expressing intent on a form—it’s direct communication.
As cookies fade away, marketers will shift from widespread hearsay to less frequent but more valuable direct interactions.
Visualize this as a pyramid: third-party data at the base (widest, lowest trust), first-party in the middle, and zero-party at the top (narrowest, highest trust).
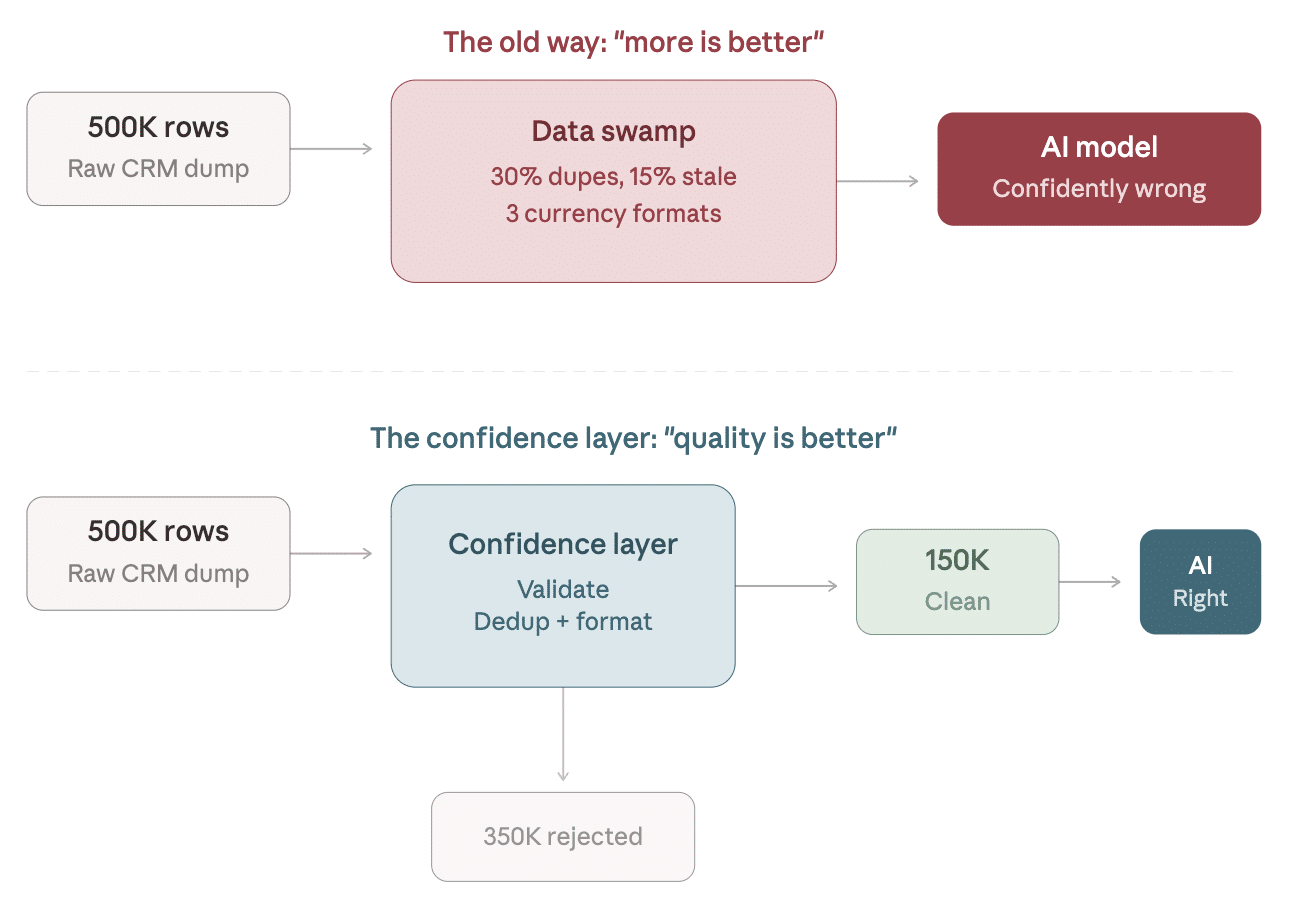
Big Data vs. Correct Data
Picture a cluttered kitchen where nothing is ever discarded. The fridge is full, but half the contents have expired, forcing you to sift through it all for a single fresh ingredient. Occasionally, you use something spoiled—this is ‘big data’ for you.
By contrast, ‘correct data’ is a well-organized pantry: fewer items, all fresh, accurately labeled, and easily accessible. Consider feeding an AI model a massive data set with duplicates and errors—it might mislead rather than help you make informed decisions.
Here’s a visual metaphor of raw data flowing into a ‘swamp’ versus passing through a filter into a clean, reliable reservoir.
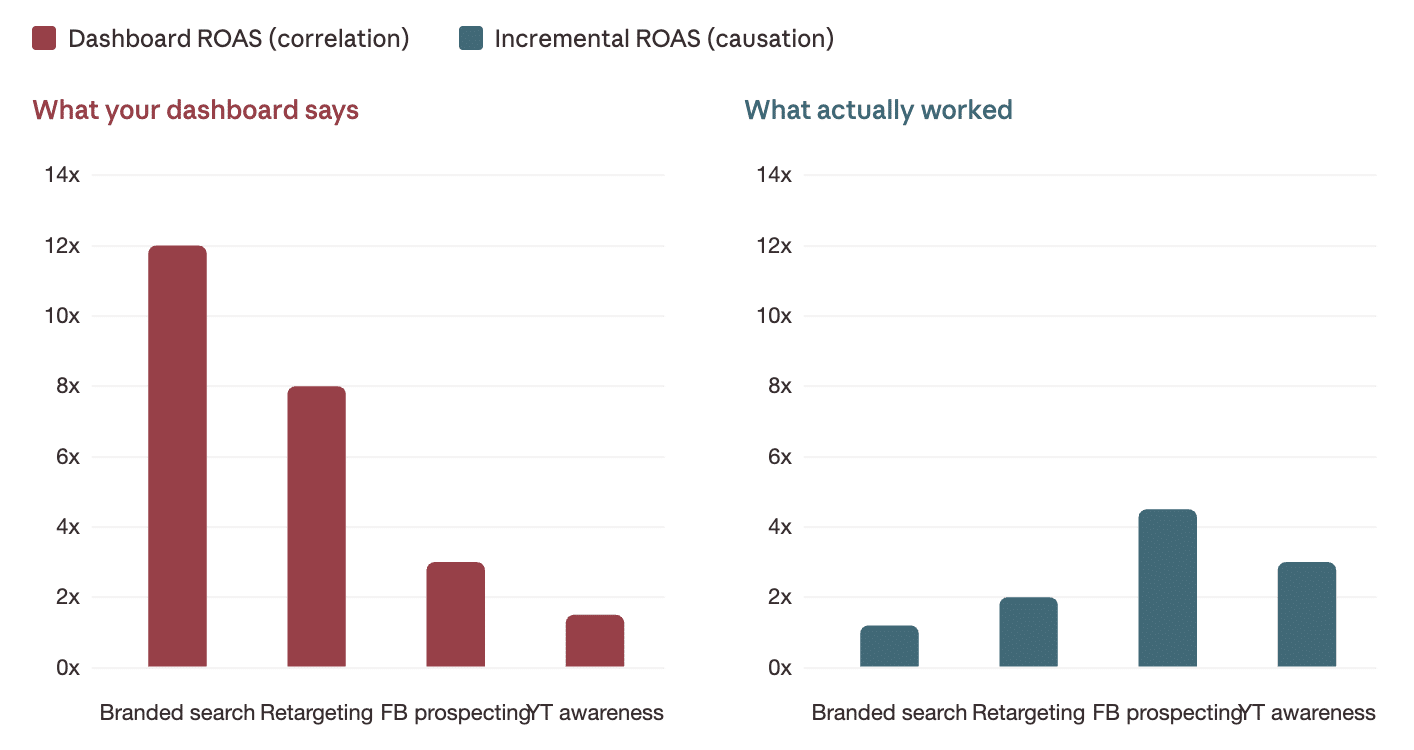
Correlation vs. Causation
You’ve probably encountered this concept before. In marketing, branded search often seems like a high performer because it records conversions right before purchases, similar to a revolving door taking credit for everyone entering a building.
Correlation identifies that those walking through the door became customers, while causation asks whether they’d have entered regardless of the door. Incrementality testing is key here.
In this test, you hold out a group from seeing ads and compare conversion rates to the exposed group. If both groups convert similarly, ads may be taking credit rather than creating demand.

An example might show branded search with inflated ROAS compared to a more accurate, incrementality-adjusted view emphasizing prospecting channels.
Building a Stronger Marketing Confidence Layer
To establish cross-team confidence, consider these data foundation tools:
- Identity confidence thermometer: Go from probabilistic data (low confidence) to deterministic data (high confidence).
- Siloed vs. holistic: Transition from siloed data to a holistic view for greater confidence.
- Data trust pyramid: Move from third-party (low confidence) to first- and zero-party data (high confidence).
- Big data vs. correct data pipeline: Filter raw data to reliable outputs, moving away from a ‘confidently wrong’ AI.
- Correlation vs. causation ROAS: Shift from identifying correlations to proving causation with a scientific approach.
While AI can automate countless tasks, effective decision-making must be upheld by experienced marketers applying good judgment. These data foundations help us move closer to achieving that.
Inspired by this post on Search Engine Land.
