At Resolve, we define link building for legitimacy as earning authoritative backlinks, brand mentions, and media coverage that demonstrate trust, expertise, and credibility to search engines and AI systems. Instead of chasing link volume, we use digital PR, original research, thought leadership, and journalist relationships to earn genuine editorial citations. These are the authority signals behind Google’s E-E-A-T framework, and they can help us appear in AI Overviews, earn citations from large language models, and build visibility that survives ranking swings.
We believe a little competition is healthy. It challenges us, sharpens our thinking, and pushes us to pursue bigger and better results.
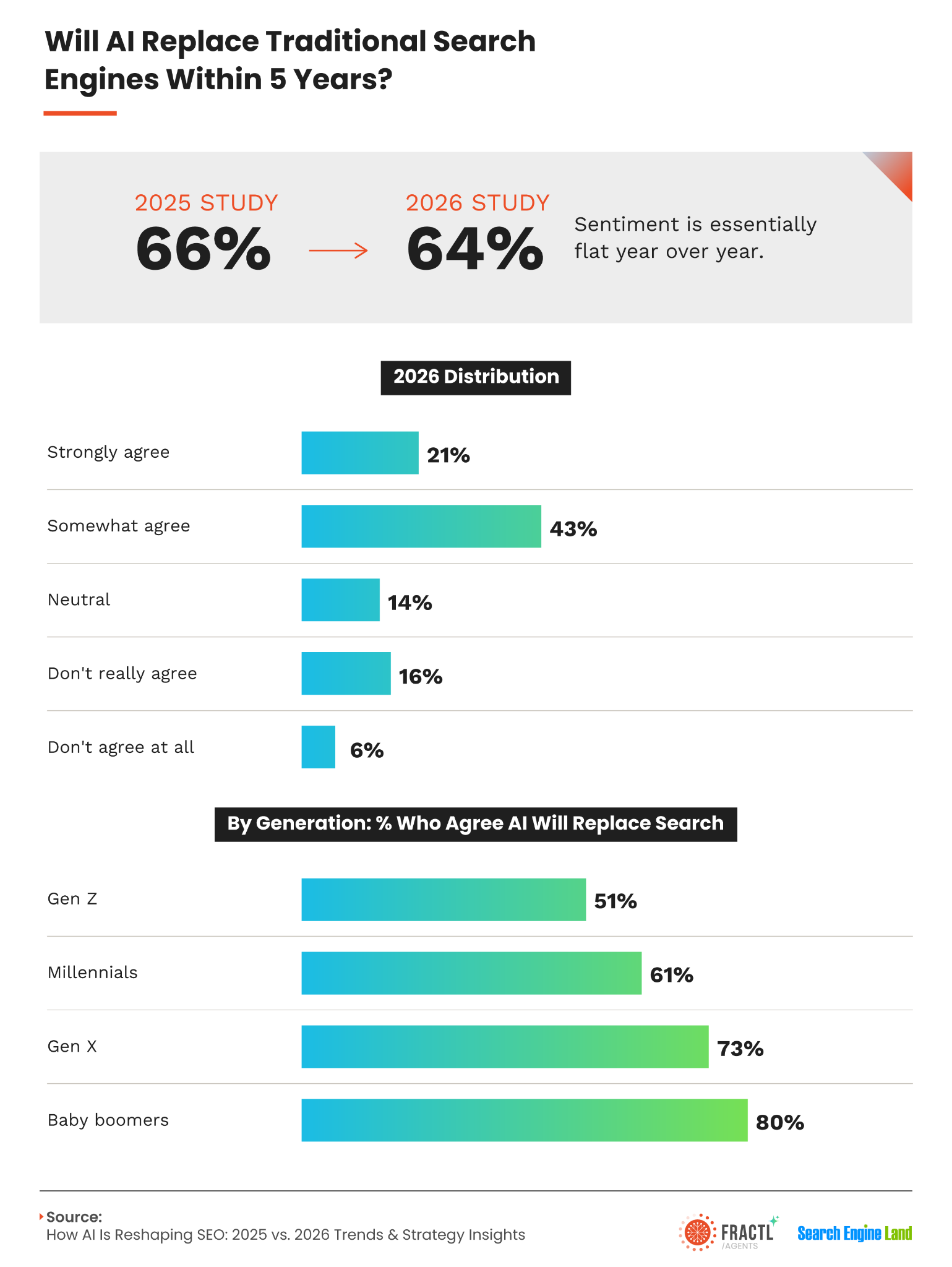
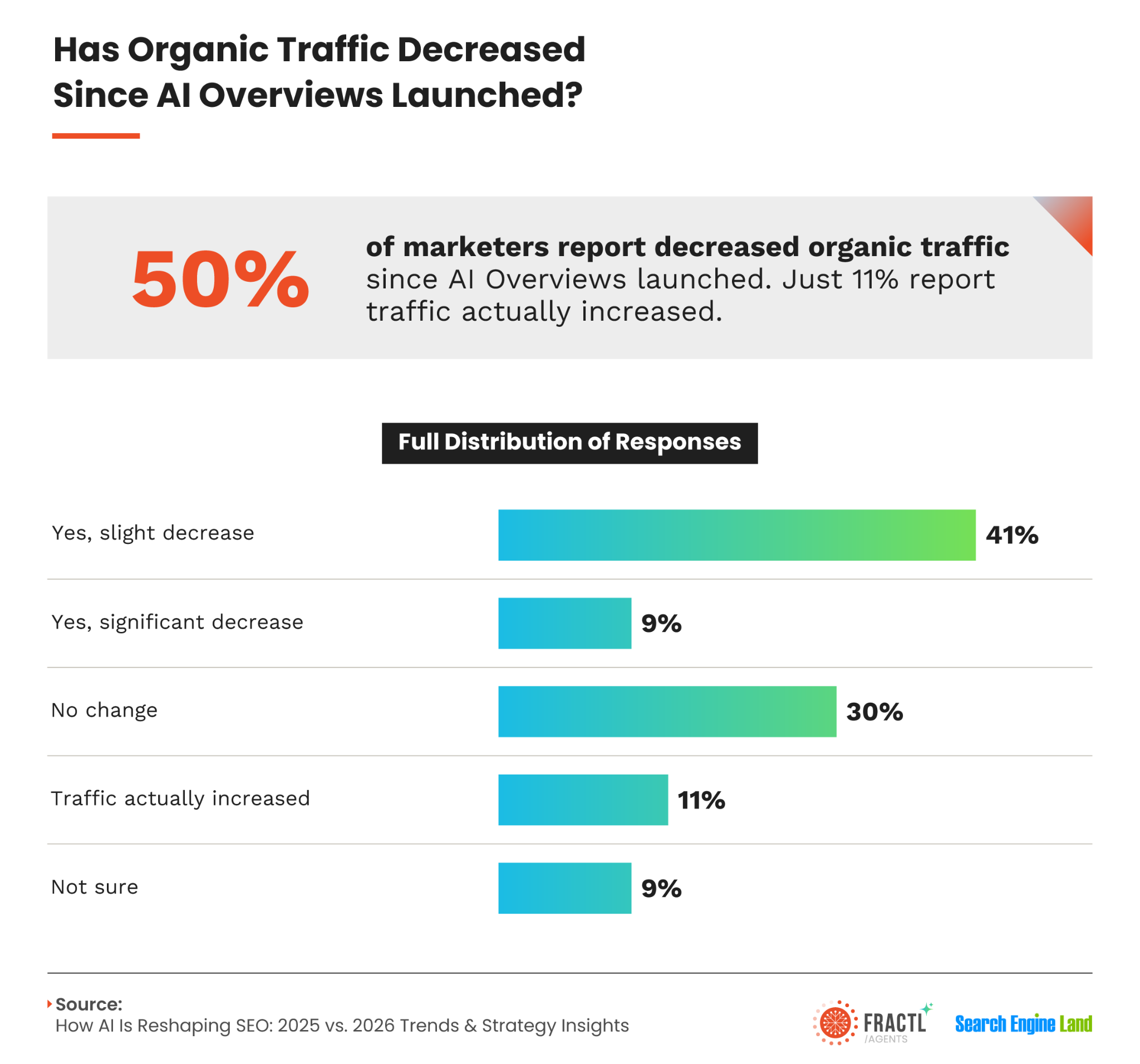
However, today’s search environment is changing faster than ever. Large language models, AI-generated answers, and frequent algorithm updates are reshaping how people find information, making it increasingly difficult for us to rely on yesterday’s playbook.
The metrics we once used to keep brands afloat — traffic, domain authority increases, and keyword rankings — no longer define SEO success on their own. We can reach the top of a search results page and still see very few conversions.
If we continue chasing those numbers in isolation, we risk being left behind. We have to adapt.
We now widen our view to the outcomes that matter most: trust and brand authority. Unlike a temporary ranking or traffic spike, trust and authority are not earned quickly or easily.
We need time to spread the word about our brand, and we need even more time to prove that people can rely on us. Once we establish that trust, however, it becomes much harder to dislodge.
An algorithm update can cut our traffic overnight. It cannot erase genuine trust overnight.
Our challenge is learning how to build trust and strengthen our brand while every competitor is trying to do the same. We also need meaningful ways to measure concepts that can initially seem difficult to quantify.
We have found that the answers involve some nuance, but they are simpler than they appear. The process begins with a shift in perspective.
Why we see link building as more than rankings
For years, we treated link building like a popularity contest. The site that collected the most votes, in the form of backlinks, was often rewarded with a prominent position in the search results.
Over time, Google and other search engines updated their algorithms to improve the search experience. With each change, Google cracked down on more sites that tried to manipulate the system with backlink volume instead of earning links with real editorial and audience value. Countless sites lost traffic, and many still feel the effects.
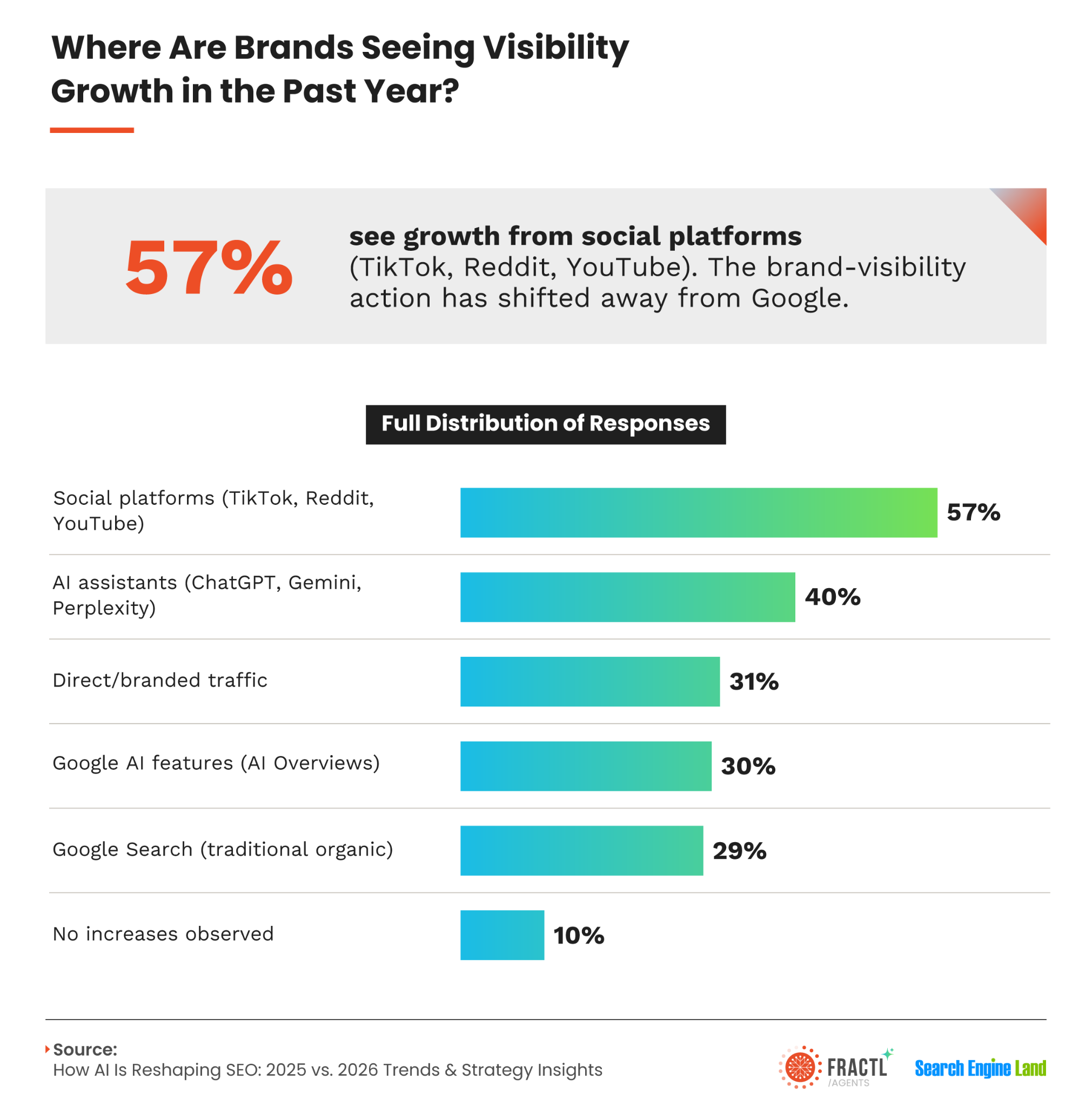
Today, we see Google place more emphasis on relevance, industry trust, and authority. That helps explain why a familiar brand can attract more searchers than a smaller competitor even when both publish similar content and target similar keywords.
Large language models and Google’s AI Overviews have widened this divide. These systems can use retrieval-augmented generation, or RAG, to retrieve relevant sources, often favoring authoritative publications and proprietary information. If we merely repeat a statistic already cited by a top-tier publication, an AI system may choose the better-known source to reduce the risk of spreading inaccurate information.
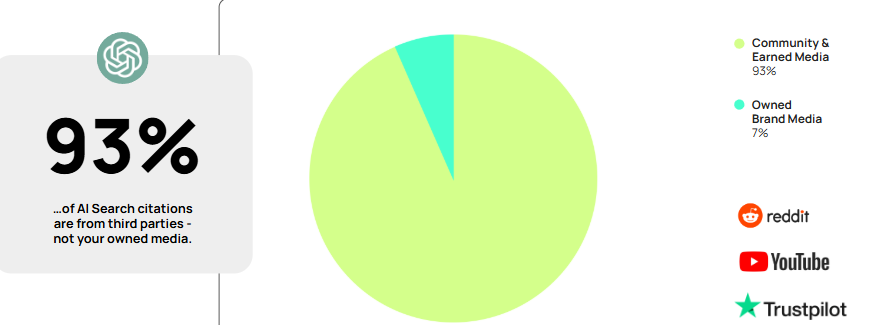
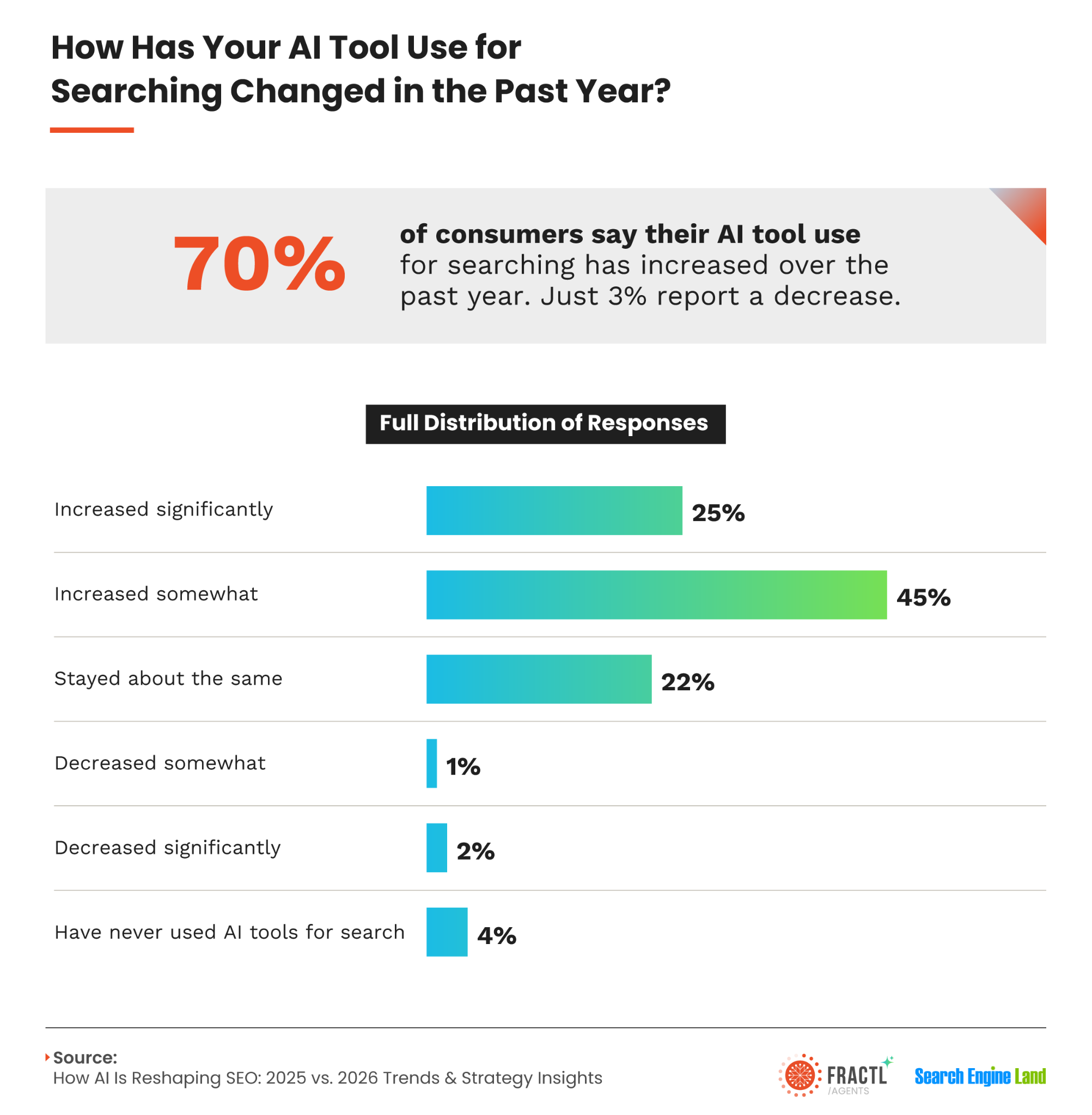
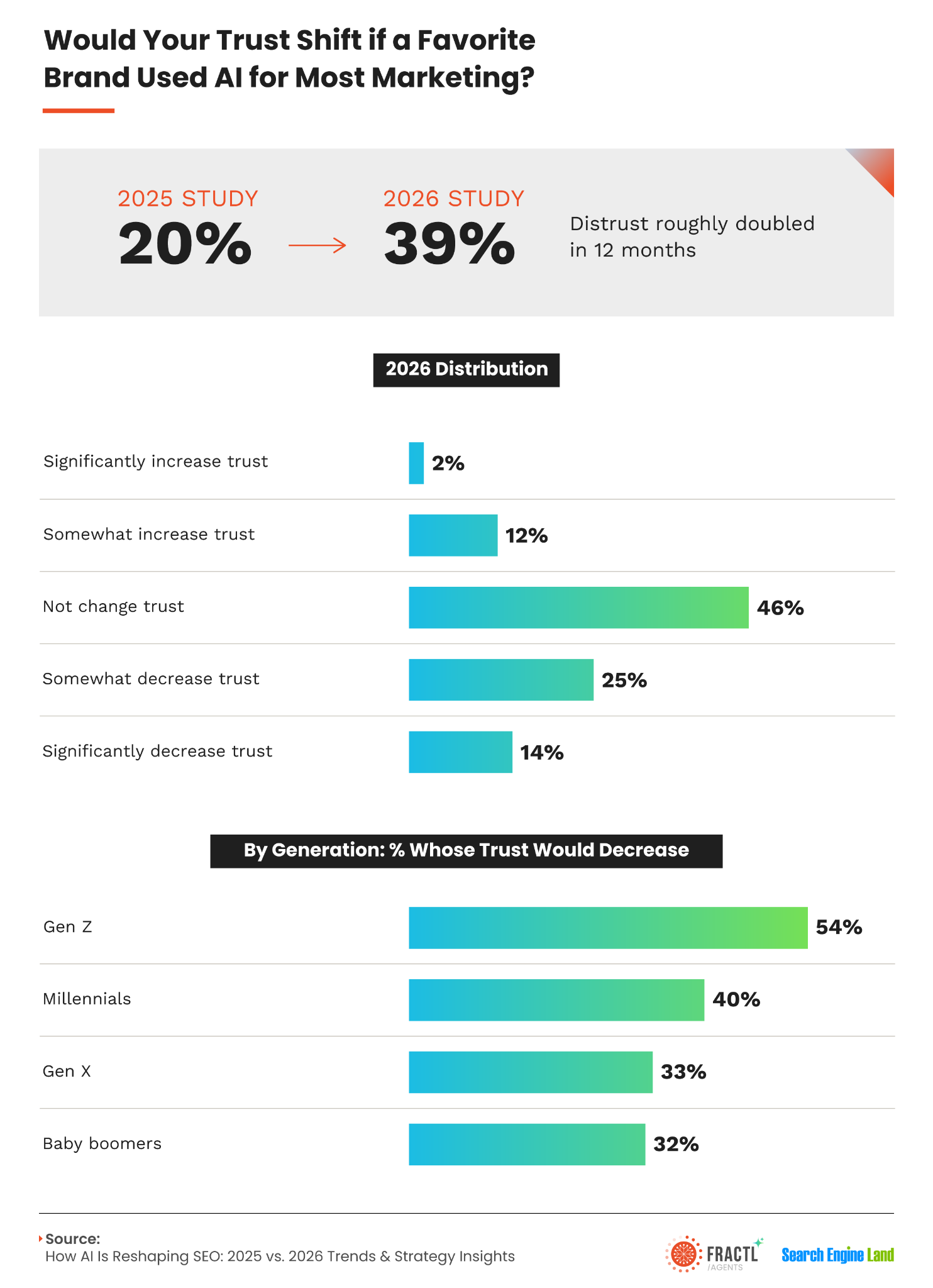
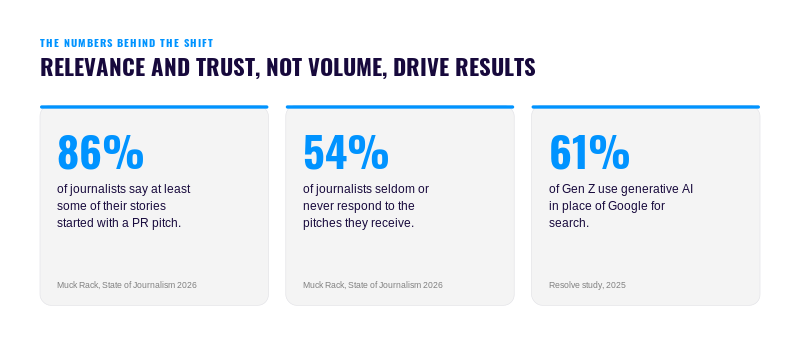
We also see younger searchers moving toward AI tools. In a 2025 Resolve study, 61% of Gen Z respondents said they used generative AI instead of Google.
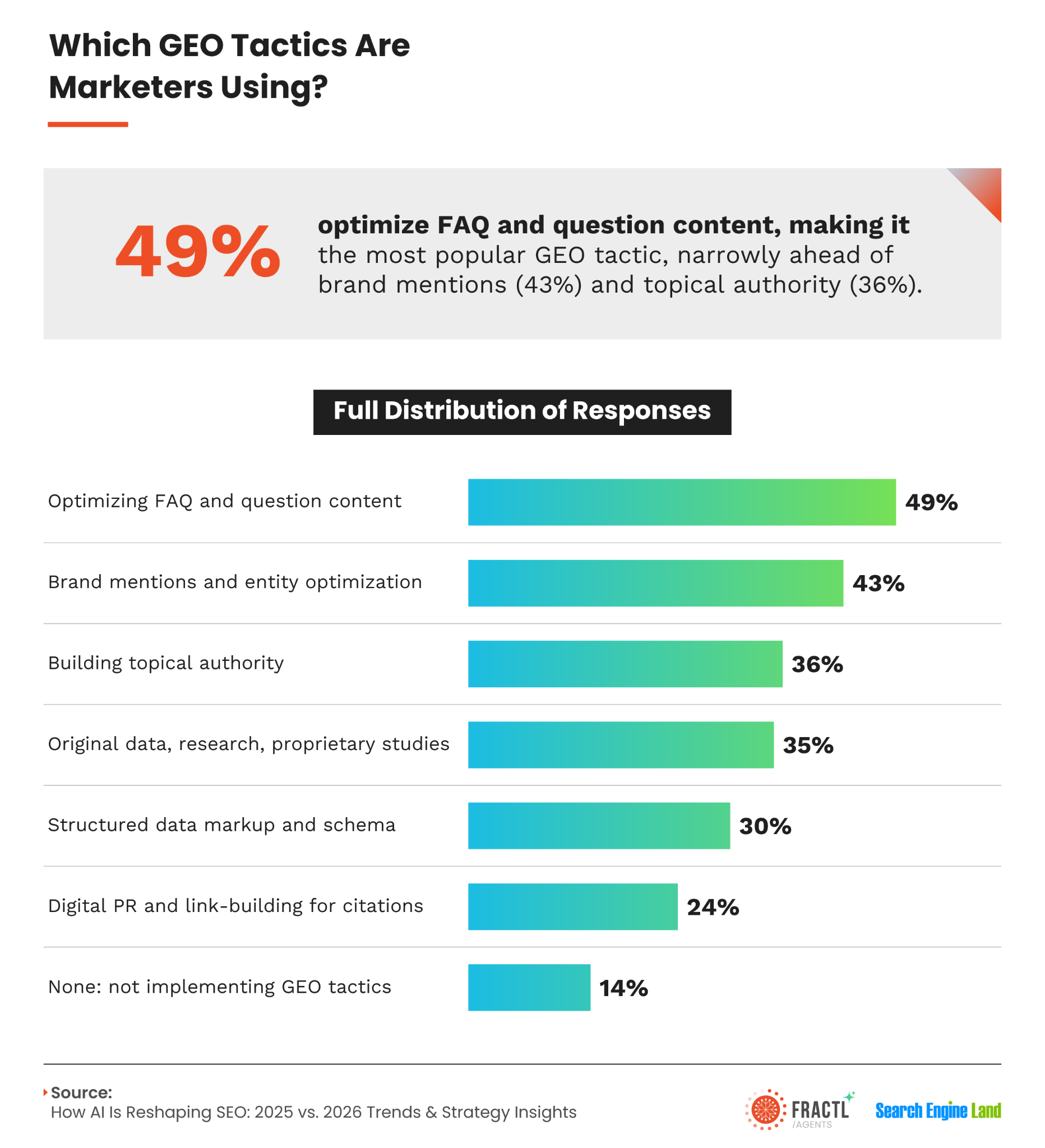
None of this means every form of link building looks like spam to Google or an LLM. It means we need backlinks to work alongside a broader set of authority signals.
When publications and journalists cite our brand, they signal authority. When we publish original content and proprietary data, we signal authority. When we create useful graphics and informative videos, we signal authority again.
Once Google and AI systems recognize these signals, the backlinks supporting them become meaningful votes of confidence. Our site may then be more likely to rank prominently, appear in AI Overviews, and receive citations in LLM-generated answers.
How we use E-E-A-T in a competitive search environment
In 2018, Google updated its quality-rater guidance to place greater focus on expertise, authoritativeness, and trustworthiness, commonly shortened to E-A-T. In 2022, Google added another E for experience. Together, these qualities provide a framework for understanding how Google considers credibility and legitimacy.
- Experience: We demonstrate that an author has personally engaged with the subject. Examples include a forum where people describe testing a product or a gardener documenting firsthand pest-prevention trials.
- Expertise: We show that the author has relevant knowledge, qualifications, or credentials supporting the information and advice.
- Authoritativeness: We earn recognition from credible sources and industry voices that cite or link to our work, helping establish us as a respected participant in the field.
- Trustworthiness: We remain transparent, accurate, and honest. We avoid deceiving readers or using manipulative link-building practices.
We apply E-E-A-T both on and off the page. Author biographies can demonstrate expertise, while accurate sourcing can demonstrate trustworthiness. Off the page, we strengthen E-E-A-T signals through the quality of the sites that link to us and the journalists who rely on us as a source. Both dimensions influence how search engines assess whether our information is useful, accurate, and credible.
If we consistently earn backlinks from dozens of irrelevant websites, that pattern can look like a low-quality or manufactured signal. If several respected journalists mention our brand because we published a valuable study, those mentions are much more likely to function as genuine votes of confidence.

For us, link quantity is no longer a reliable proxy for legitimacy. We look for backlinks that demonstrate real relevance and value.
We cannot earn those links half-heartedly. We need a coordinated strategy that strengthens credibility both on and off our site.
The off-page SEO tactics we use to demonstrate value
When we ask how to earn links that search engines and LLMs will treat as signs of trust, we do not look for a single outreach tactic. Strong links usually emerge from several activities that we sustain over time.
We create genuinely linkable assets
To prove that people genuinely want to reference our site, we first create content worth referencing. If we are accustomed to quick and easy links, this may require a larger investment in content than we have made before. A routine how-to article or listicle is rarely enough by itself.
We define linkable content as something journalists, publishers, and readers find distinctive and useful — something they have not already encountered dozens of times. We often draw from the following content formats.
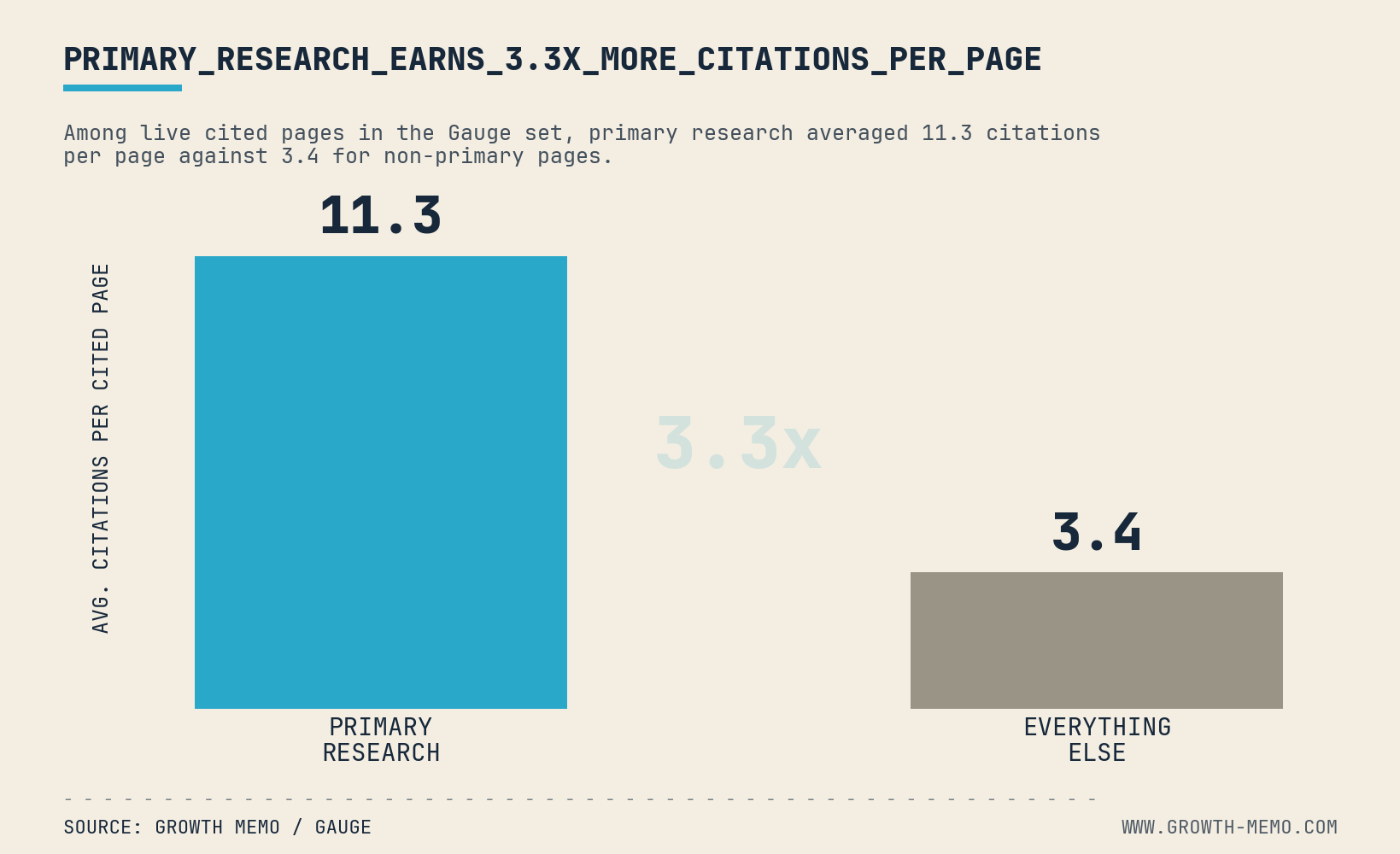
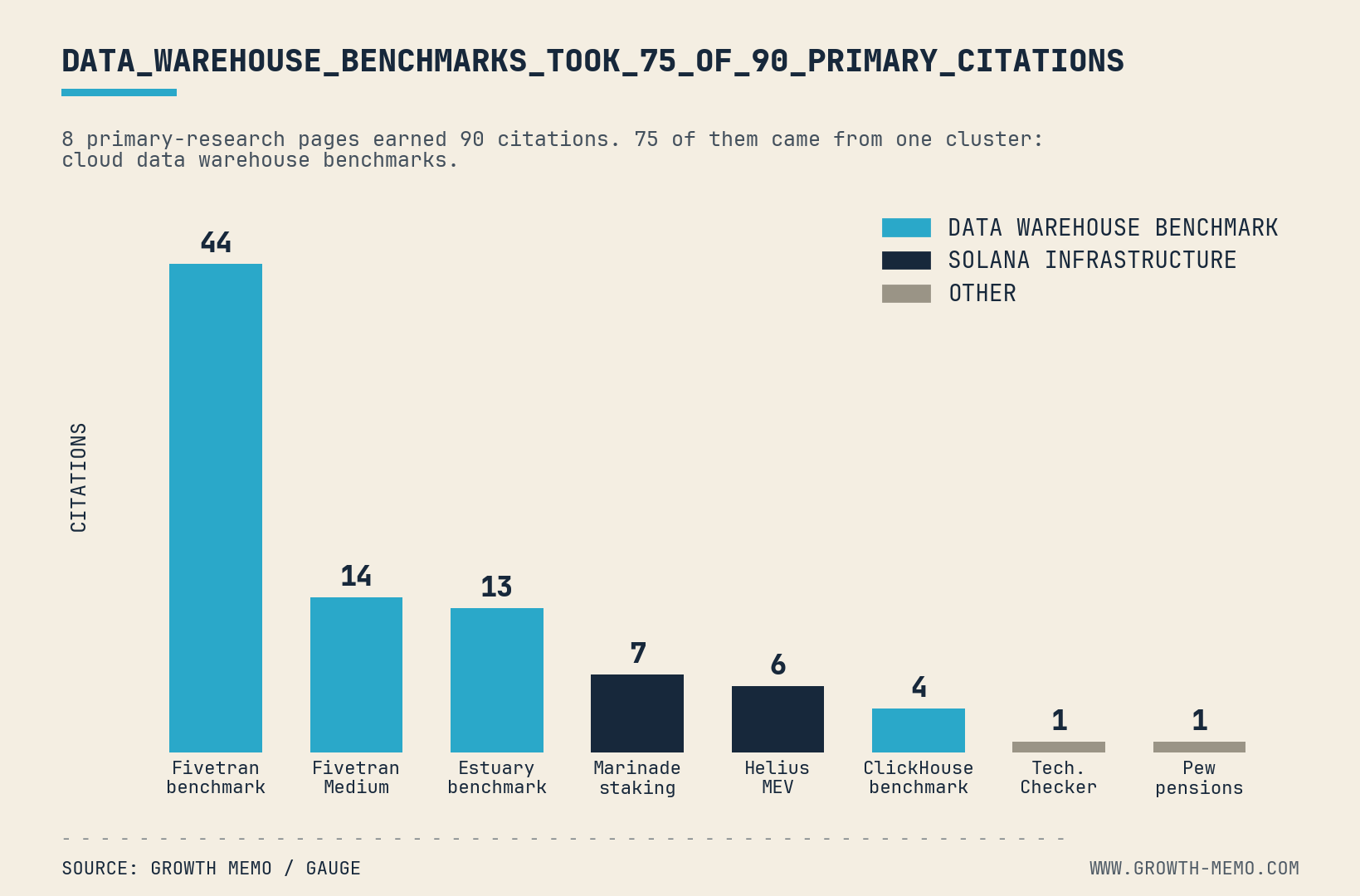
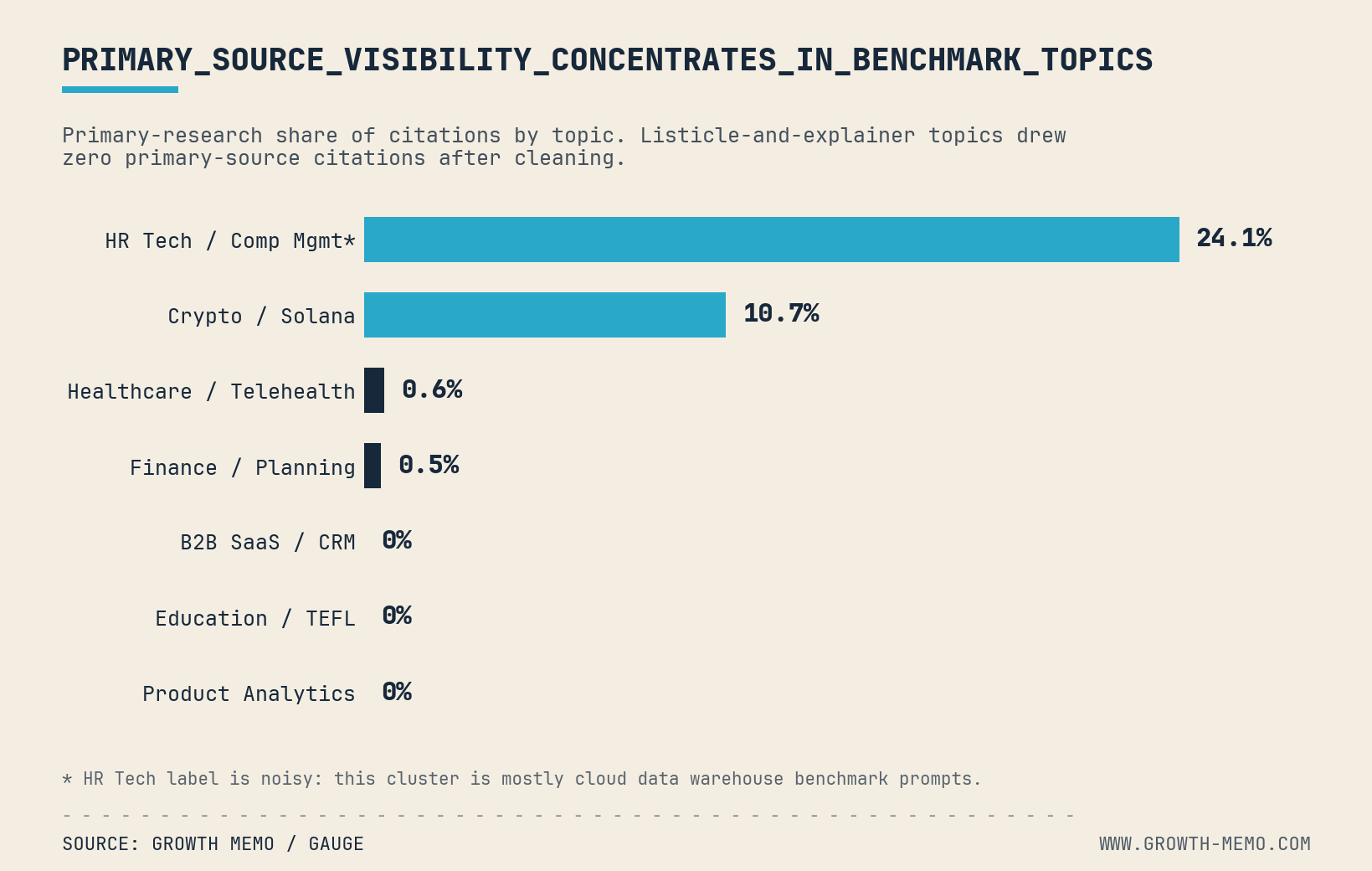
- Original data and proprietary research: We publish information people cannot find elsewhere. In a crowded search environment, that means conducting original research rather than recycling familiar statistics. When a journalist needs a statistic and our site is the primary source, we can earn a natural backlink.
- Thought leadership and expert commentary: We share an original perspective from a credible expert within our organization, giving publishers a useful idea or quotation they may cite in future coverage.
- Authoritative long-form guides: We answer the main question thoroughly and anticipate the follow-up questions a reader is likely to ask. This depth can help us earn links as audiences move further into their research.
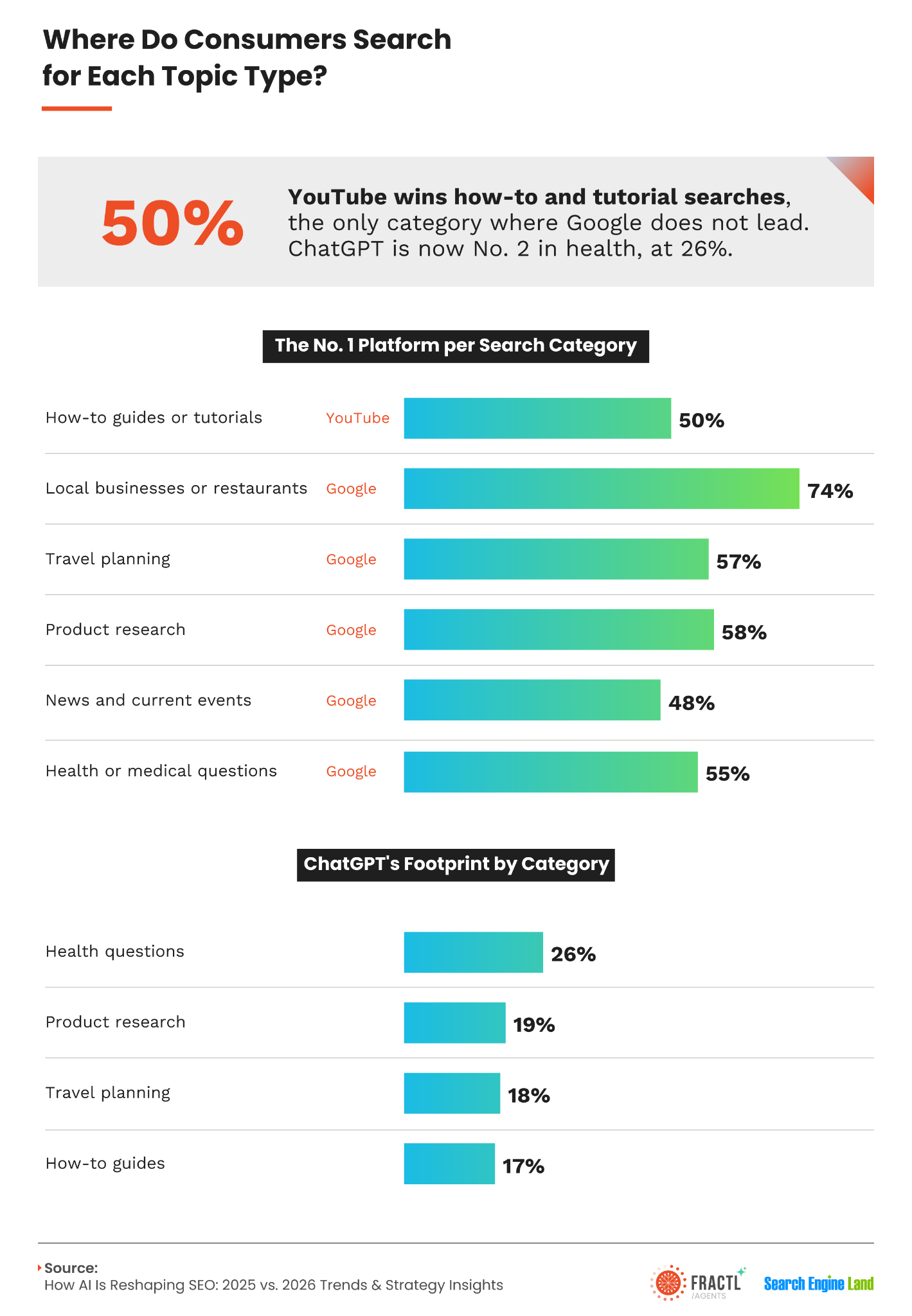
- Engaging visuals and infographics: We invest in visual assets that make complex information easier to understand and share. Ahrefs found that YouTube mentions strongly correlated with inclusion in AI Overviews. Videos can be especially valuable, but informative infographics also give publishers a useful visual for their own audiences.
These formats demand more time, effort, and money, but we have found that they are often more sustainable than disposable content. They help us earn credible editorial citations and build industry authority that is more resilient to algorithm updates.
We connect link building with digital PR
We place digital PR at the center of authority building because it connects brand development with link acquisition. It helps us earn coverage, attract links, and introduce our organization to new audiences through credible journalists. Those are precisely the kinds of signals search engines can consider when assessing legitimacy.
Unlike traditional PR, our digital PR work focuses on online coverage and backlinks from news organizations and media outlets. We create useful assets or proprietary data, identify the journalists most likely to care, and pitch stories that fit their established beats.
Many of these publications carry significant influence and reach large audiences that can introduce our brand to more people. When a highly authoritative outlet covers our story, other journalists may discover and cite it organically. Syndication can amplify the effect further when a media group republishes an article across its network, potentially producing many relevant links from one story.
Our strongest digital PR campaigns typically use one or more of the following approaches.

- Data-led PR campaigns: We begin with what journalists and their readers care about, not simply what we find interesting. We review local news, Google News, and current coverage to understand which subjects are gaining attention. By considering journalist intent from the start, we improve our chances of receiving responses and earning placements.
- Newsjacking or reactive PR: When we can move quickly, we contribute expert opinions, data, or commentary to breaking stories that relate to our brand. This gives journalists material they can use while the topic is still timely.
- Proactive PR: We anticipate trends before they break and prepare insights around recurring news cycles, holidays, and other relevant media moments.
- Contributed content and guest features: We place useful content written by our experts in relevant publications, allowing us to speak directly to established audiences and earn recognition.
When we combine these tactics effectively, we can elevate our brand to a level that competitors cannot reproduce with a batch of low-value links.
We build relationships with journalists and publishers
We know that even fascinating proprietary data, packaged in an expertly designed analysis, can fail if our journalist outreach is poorly targeted.

Journalists receive an enormous number of PR pitches, and those messages can either support or obstruct their work. According to a 2026 Muck Rack study, nearly nine in 10 journalists said at least some of their stories originated with PR pitches.
The same survey found that 54% of journalists seldom or never responded to most pitches. Relevance was a central problem: nearly half said a genuinely relevant pitch was rare.
If we send a journalist at an economics publication a pitch about music-listening habits, we should expect a rejection because the subject may matter to only a small part of that publication’s audience. We do not take that response personally. Journalists build their careers around particular topics and beats, and our job is to support that work rather than distract from it.
We therefore approach outreach as relationship building: a two-way exchange that should benefit everyone involved. Above all, we remember that there is a real person on the other side of every email.
- We personalize our emails and explain why a story fits the journalist’s audience.
- We respond graciously when a journalist says no because our next idea may be a better fit.
- We share relevant work from journalists and publications through social media.
- We contribute thoughtful comments when we have something useful to add.
- We cite journalists’ reporting in future content when it genuinely supports our work.
As we strengthen these relationships, journalists become more likely to consider future opportunities. A thoughtful follow-up or second pitch can receive a warmer response when a reporter already knows that we provide reliable data and useful commentary.
PR relationships grow over time. Even when our first pitch does not fit a journalist’s beat, we remain willing to return with a better story or a new set of relevant data.
How we measure real brand authority
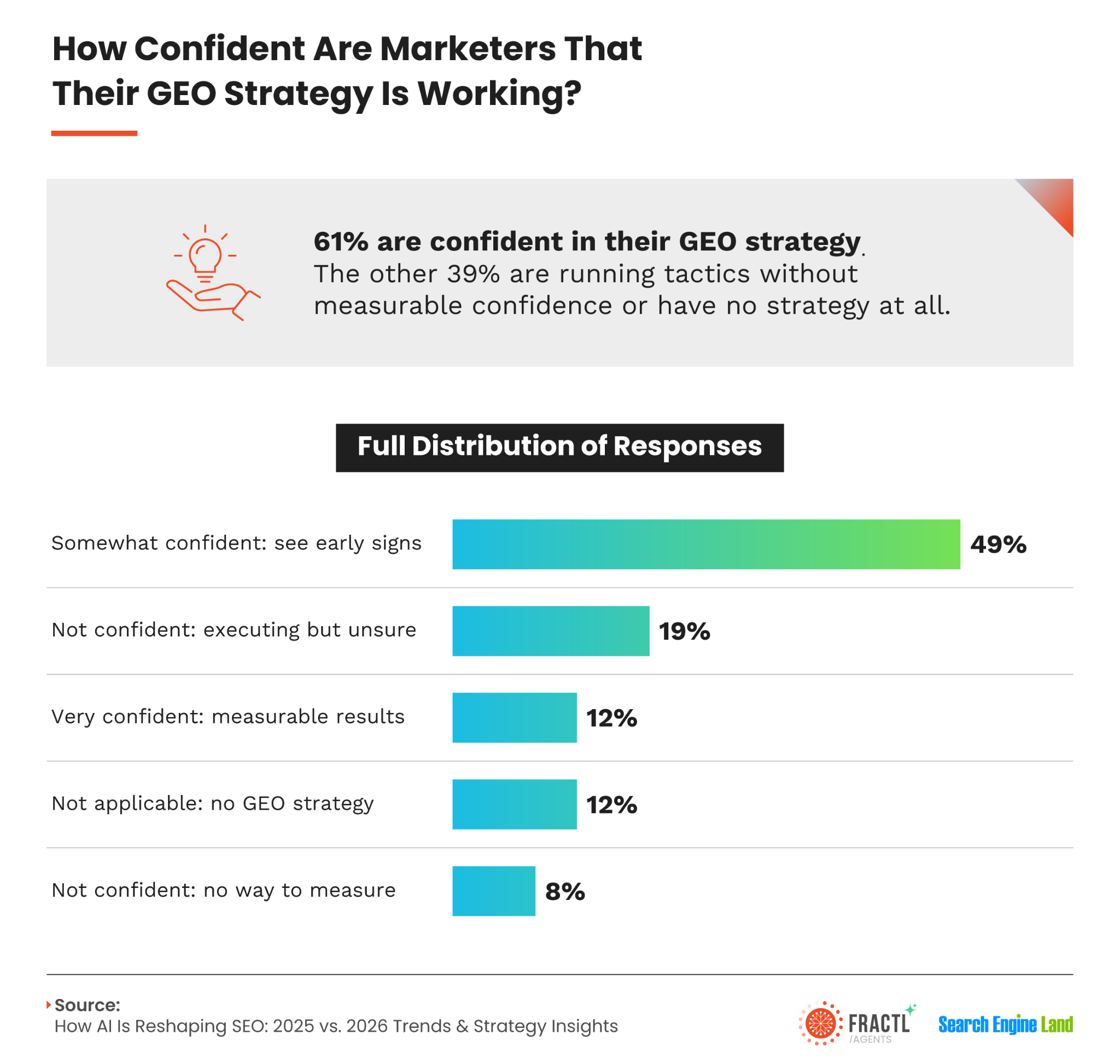
We recognize that authority, trust, and legitimacy feel less concrete than traffic or keyword position. Yet they have become more important. A traffic surge may look encouraging while reflecting temporary attention, weak intent, or an advantage that disappears after an algorithm update.
Authority and legitimacy are more durable. We can also measure the impact of credibility-focused work through several meaningful indicators.
- Earned media placements: We track the publications that cover our brand, including coverage containing an unlinked mention. These placements help us assess brand credibility.
- Branded search volume: We monitor whether more people search for our company or products after discovering us through media coverage.
- Industry coverage: We look for the point at which publications we have not contacted begin citing our work. That organic pickup is a valuable sign that our authority is spreading.
- Conversions: We measure whether greater credibility leads more people to trust our organization, products, or services and ultimately take meaningful action.
- Organic ranking improvements for target keywords: We still review rankings, but we treat them as one indicator within a broader picture. Sustained movement can show that search engines increasingly view us as a credible result relative to competing pages.

We do not expect these indicators to appear overnight.
- We invest real effort in creating proprietary data.
- We build trust with journalists through repeated, useful interactions.
- We grow authority through sustained work over time.
Our advice is simple: we stay patient, keep improving, and allow credible results to compound.
How we build a credibility-focused link strategy
Knowing the principles of SEO authority is one thing; building an entire campaign around them is another. We use the following five-step process to turn those principles into consistent action.
- Step 1 — We define our target publications: We identify five to 10 publications that our audience trusts and that search engines are likely to recognize as authoritative within our field. These become our priority coverage targets.
- Step 2 — We develop linkable assets: We create at least two content or media assets designed around the interests of those publications. We may use original survey data, visual guides, proprietary analysis, or expert thought leadership.
- Step 3 — We launch a digital PR campaign: We proactively pitch our assets to relevant publications. We can also use platforms such as Connectively or Muck Rack to identify ongoing opportunities with writers covering subjects related to our research.
- Step 4 — We nurture relationships: We treat every positive media interaction as the beginning of a longer relationship. We follow up with useful information, engage with published coverage, and build the kind of rapport a journalist can rely on.
- Step 5 — We measure and iterate: We review our authority indicators each quarter, learn from the response to our campaigns, and adjust our content and outreach accordingly.

We know this process can consume a team’s time, particularly when resources or specialized expertise are limited.
In those situations, we may benefit from working with a link-building and digital PR specialist who can expand our capacity and keep pace with search changes. The right support can help us establish sustainable visibility without allowing every minor ranking fluctuation to pull us off course.
How we build authority that lasts at Resolve
We know that quality usually stands the test of time better than quantity. The difficult part is maintaining that focus when competitors appear to be winning with sudden traffic spikes or eye-catching vanity metrics.
We do not let temporary numbers distract us from the larger goal. We focus on lasting authority and legitimacy earned through sustained content creation, thoughtful PR outreach, and genuine relationship building.
When an internal team lacks the time or patience required to maintain that effort, we can step in.
At Resolve, we work with brands to build credibility-focused SEO campaigns through linkable content, data-led digital PR, and hands-on link building. Our goal is sustainable organic growth, not a burst of visibility that disappears after the next algorithm update.

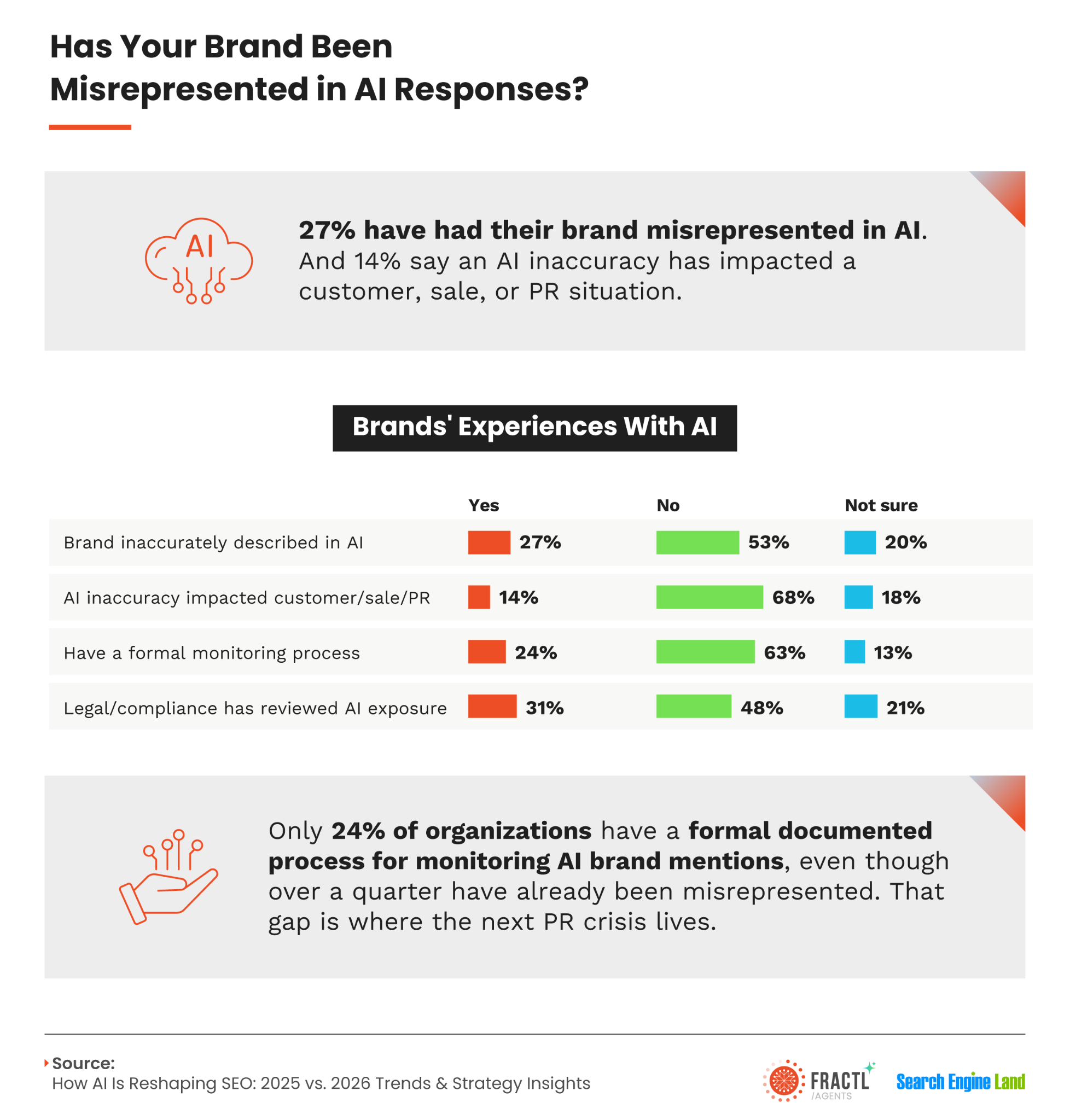
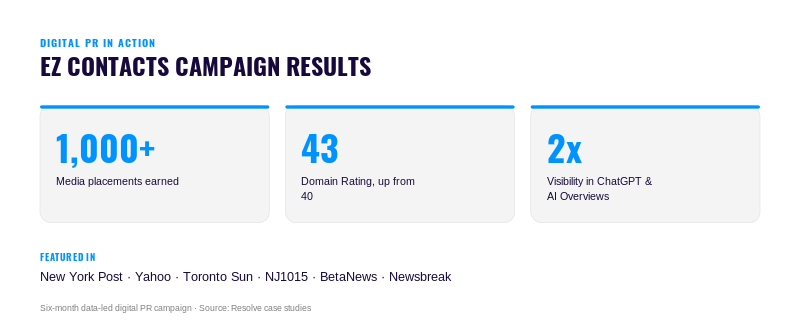
We have seen this approach pay off. In a recent data-led campaign for EZ Contacts, we earned more than 1,000 placements in outlets including the New York Post and Yahoo. As the coverage grew, the brand’s visibility in ChatGPT and Google’s AI Overviews doubled. That is the kind of durable growth we want to build — growth that extends beyond the next algorithm update.

When we are ready to build links that last, we can visit growresolve.com to learn more.
Our answers to common link-building questions
How do we distinguish link building from digital PR?
We see considerable overlap between link building and digital PR, but we do not treat them as identical. Link building is the broader practice of acquiring backlinks from other websites to improve search authority. Digital PR is a particular approach within that practice, focused on earning links through media coverage, journalist relationships, and placements in credible publications rather than relying on directory submissions, guest-post exchanges, or other lower-authority tactics.
We often use digital PR to pursue the strongest editorial backlinks because reputable outlets have real audiences and established review standards. At the same time, this work builds brand visibility and consumer trust in ways that many conventional link-building methods do not.
How long do we wait for meaningful results?
We do not expect authoritative backlinks or earned media coverage to produce results overnight. That is an honest trade-off when we choose a credibility-focused approach instead of more aggressive tactics. Most brands can begin seeing meaningful domain-authority gains and early ranking movement after three to six months of consistent execution, while highly competitive keywords and top-tier placements may require more time.
The advantage is that our results can compound. Links from credible publications tend to endure, strong journalist relationships can create repeat opportunities, and the authority generated through consistent coverage can keep delivering value long after the initial campaign.
What do we mean by an authority backlink?
We define an authority backlink as a link from a source that search engines and its audience regard as credible and trustworthy. These sources typically have genuine readers, clear editorial processes, established authority, and topical relevance to our industry.
A regular backlink can come from any website willing to link to us, regardless of its relevance, quality, or editorial standards. That distinction matters because search engines do not evaluate every link equally. One editorial link from a respected industry publication can be more valuable than dozens of links from low-authority sites, while also supporting the kind of E-E-A-T credibility that bulk link acquisition cannot reproduce.
Do we value brand mentions without hyperlinks?
Yes. We recognize that Google can associate brand mentions with entities even when a publication does not include a hyperlink. Relevant, unlinked mentions in credible coverage can still contribute to the wider authority signals surrounding our brand.
That is why we consider digital PR valuable even when every placement does not produce a direct link. A credibility-focused off-page strategy should not be reduced to backlink acquisition alone. Our larger objective is to build a brand that respected publications genuinely want to mention, cite, and cover.
What risks do we face with outdated link-building tactics?
We see risks ranging from wasted effort to serious search penalties. Link buying, reciprocal-link schemes, private blog networks, and manipulative anchor-text optimization can violate Google’s spam policies. These tactics may trigger manual actions or algorithmic suppression that substantially reduces our search visibility.
Even when outdated tactics do not produce an immediate penalty, they can lose their value as search systems become better at identifying manufactured signals. Recovering from a link-related penalty can be slow and expensive. We would rather invest in credible link building from the beginning than repair the damage caused by shortcuts later.
Inspired by this post on Search Engine Land.