
Advertisers are projected to lose $172 billion a year to ad fraud by 2028. I have seen how quickly that problem can move from an abstract industry statistic to a very real performance issue inside a Google Ads account.
The risk is especially high in competitive industries where CPCs are expensive and every wasted click hurts. One client I worked with was in exactly that situation, and invalid click activity was dragging campaign performance below any profitable level.
After testing the usual defenses, I adjusted Google Ads audience targeting in a way that reduced invalid-click activity by 50% and brought the campaigns back to profitable performance.
Case study: How I cut invalid clicks by 50%
The client sold book editing and ghostwriting services. The search terms triggering the ads were relevant and high intent, but the traffic was not converting anywhere close to the level needed for profitability.
The warning signs appeared quickly. Google was reporting a 60% to 80% invalid click rate. Microsoft Clarity recordings showed bot-like behavior from Google Ads traffic. Many search terms had click-through rates above 80%, and some were even above 100%. GA4 and other analytics tools also showed far fewer sessions than the number of clicks reported in Google Ads.
I tested third-party click fraud tools first, but they did not produce any measurable improvement in performance.
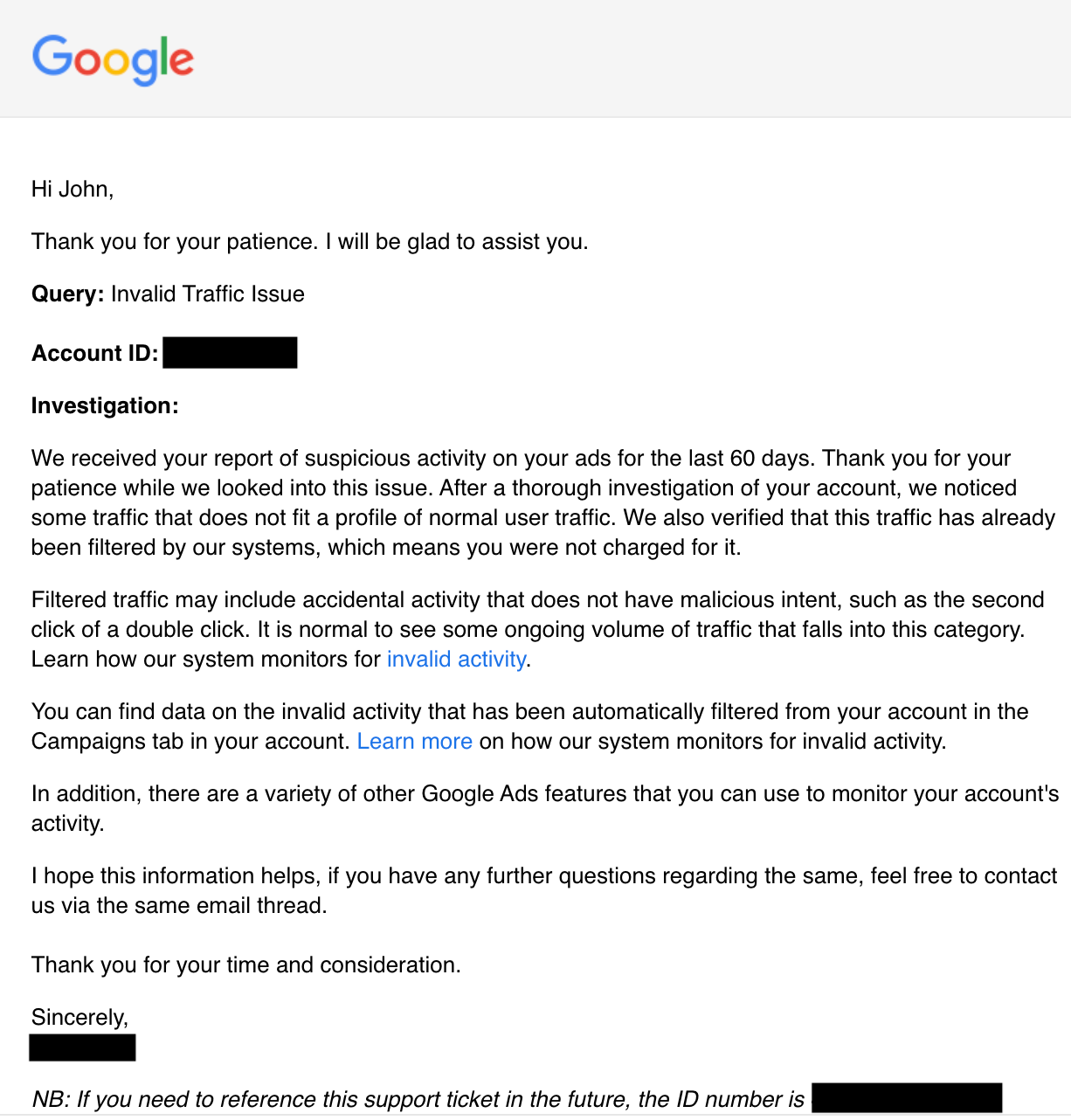
Next, I filed an investigation with Google. Google agreed that suspicious activity existed, but said it had already caught all of it and had not charged the account for those clicks.

I was still confident that Google was not filtering out all of the invalid activity, so I decided to use the targeting controls inside the account more aggressively.
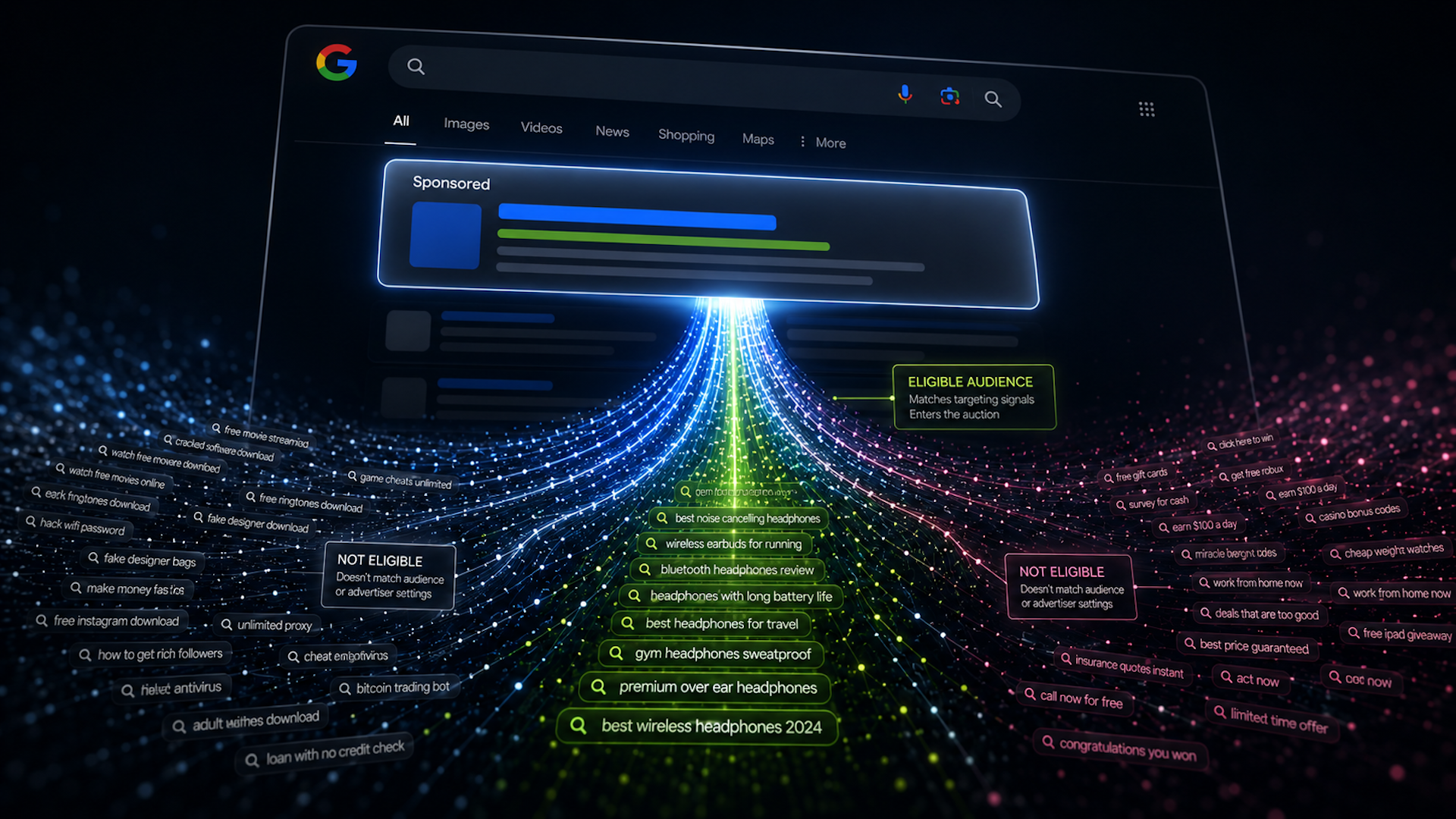
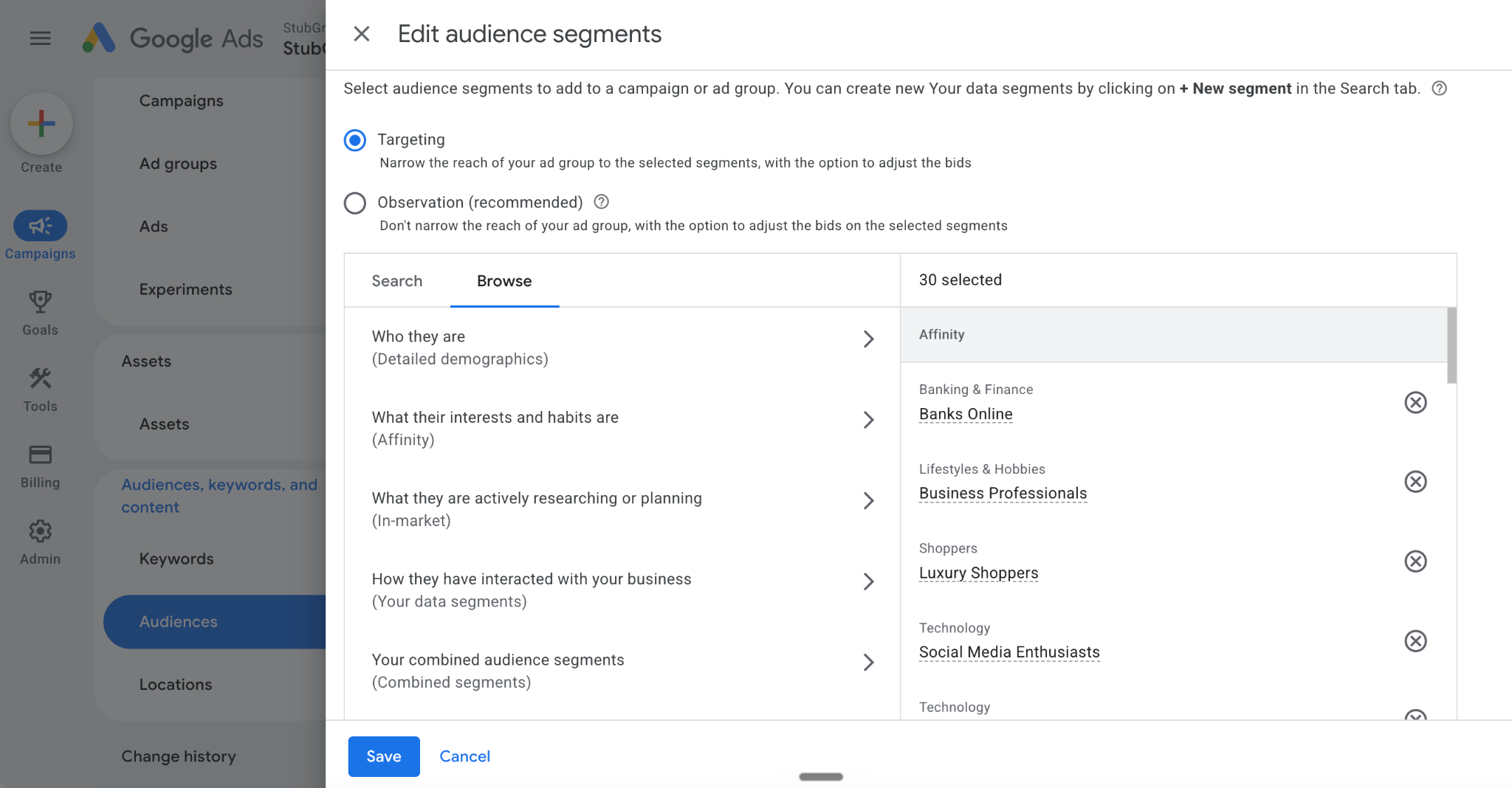
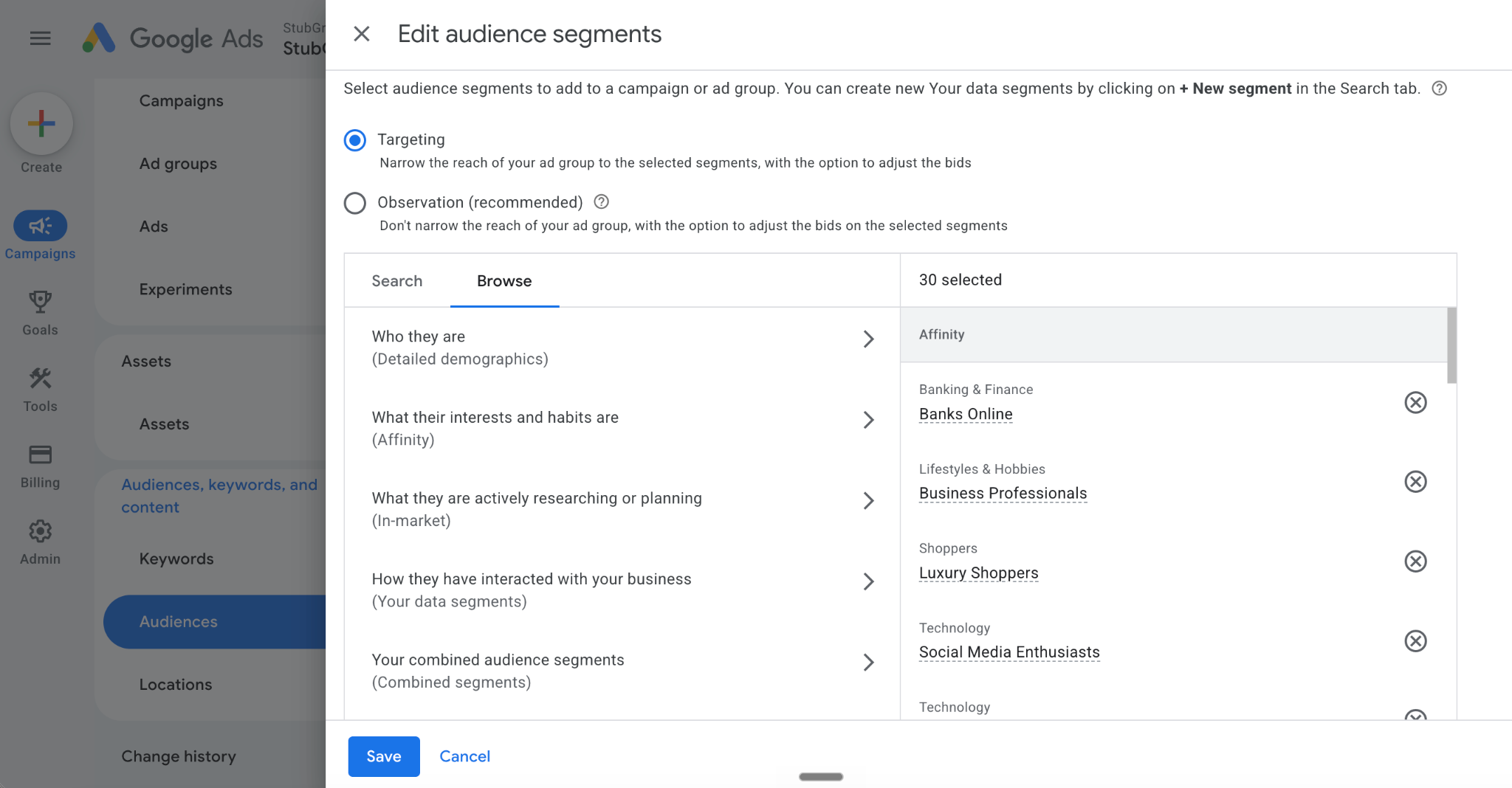
I added 540 Google-defined audiences to the Google Search campaigns and set them to Targeting.
The result was immediate. The invalid click rate dropped by 50%, and the conversion rate rose back to profitable levels.
Here is why I tested this approach, why I believe it worked, and what advertisers should understand before trying it in their own accounts.
What click fraud and invalid clicks actually are
Google defines invalid clicks as clicks on ads that do not come from genuine user interest. That includes intentionally fraudulent activity, accidental clicks, and duplicate clicks.
In practice, this can include actual fraud, such as competitors clicking ads, as well as less malicious behavior like accidental double-taps.
Google does not charge advertisers for clicks it determines are invalid. If Google initially charges for a click and later classifies it as invalid, it credits the advertiser back for that activity.
Why the usual defenses can fall short
Google catches a lot of invalid click activity, but this account showed me that the system is not perfect.
That gap is why so many third-party click fraud tools exist. Most of them try to identify suspicious IP addresses and block them before they can keep costing advertisers money.
The challenge is that fraudsters understand how these tools work. They can cycle through IP addresses with VPNs and avoid being stopped by a system that only blocks previously identified addresses.
If a tool blocks an IP address after suspicious activity occurs, that may help only if the same IP address is used again. When the source keeps changing, old IP exclusions lose much of their value.
There is also a platform limit to consider: Google allows a maximum of 500 IP address exclusions per campaign.
The tactic: Add audiences set to Targeting
I started thinking about what might separate fraudulent traffic from legitimate traffic. Google’s predefined audiences stood out because Google builds hundreds of audience segments from demographics, search behavior, and browsing behavior.
For example, someone researching private jet companies and Rolex watches might be classified by Google as a luxury shopper and added to that audience.
My hypothesis was simple: fraudsters who constantly rotate IP addresses may not also be building normal-looking online behavior profiles that fit neatly into Google’s predefined audiences.
So I added most of the available audiences to the Search campaigns. I was not trying to target only audiences that matched the ideal customer. I was using the audiences as a filter for users who carried enough Google audience signals to look more like real people.
The key detail is that I chose Targeting, not Observation.
When I use Targeting, Google limits ads to people who trigger the keywords and also belong to the selected audiences.
When I use Observation, Google simply reports how people in those audiences engage with the ads compared with everyone else. The ads can still show to anyone who triggers the keywords.
I would only test this tactic in accounts with unusually high invalid click rates. It can create real downside, including the risk of blocking legitimate searchers who do not fit inside Google’s predefined audience segments.
How to test this in your own account
In a Search campaign, go to Audiences > Edit audience segments > Targeting > Browse. Then select the audiences you want to add and click Save.
Common questions about fighting click fraud
Will Google refund clicks it identifies as invalid?
If Google identifies a click as invalid when it happens, I am not charged for that click. If Google identifies the click as invalid later, the account receives a credit toward future advertising.
How do I see how many invalid clicks I am getting?
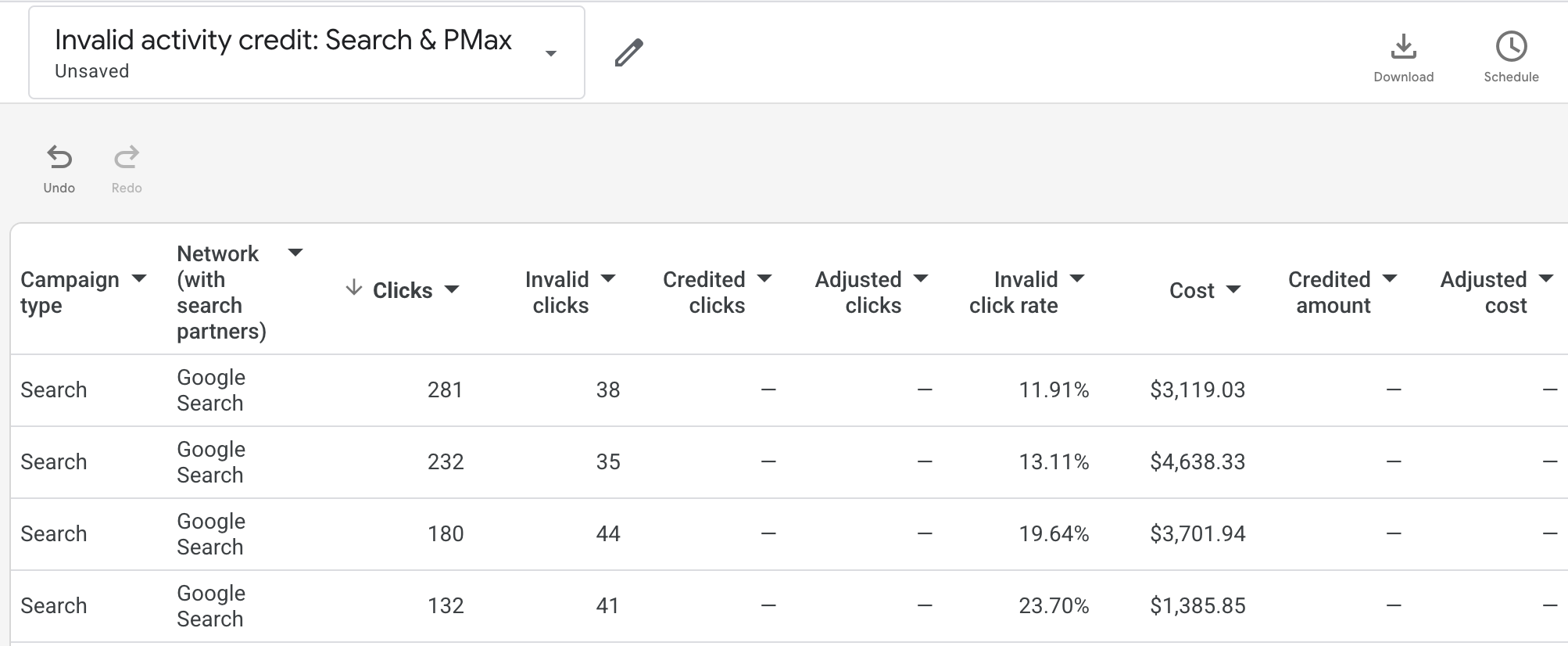
The Invalid activity credit report in Report Editor inside the Google Ads UI provides the most detailed reporting.
I look at two key metrics there: Invalid clicks, which are clicks I was not charged for, and Credited clicks, which are clicks I was originally charged for but later credited back.

I can also add the Invalid clicks and Invalid click rate columns at the campaign level, though not at the ad group or keyword level.
What is a normal invalid click rate?
A February study found an 11.4% invalid click rate across 43,700 accounts.
Industry makes a major difference. While the average invalid click rate for StubGroup clients is very close to that study’s finding, I have seen advertisers in competitive industries with invalid click rates above 40%.
Should I file an investigation with Google?
If I have reason to believe Google is charging for invalid clicks, I consider filing an investigation here.
Why this approach worked best
Using Google’s predefined audiences as a filter cut this account’s reported invalid click rate in half. More importantly, it blocked activity that Google had said it was already catching, which turned failing campaigns into profitable ones.
Inspired by this post on Search Engine Land.


